

Self-supervised pre-training for joint optic disc and cup segmentation via attention-aware network
- PMID: 38438876
- PMCID: PMC10910696
- DOI: 10.1186/s12886-024-03376-y
Self-supervised pre-training for joint optic disc and cup segmentation via attention-aware network
Abstract
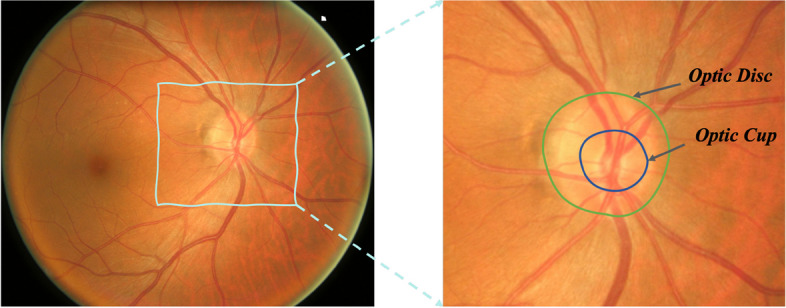
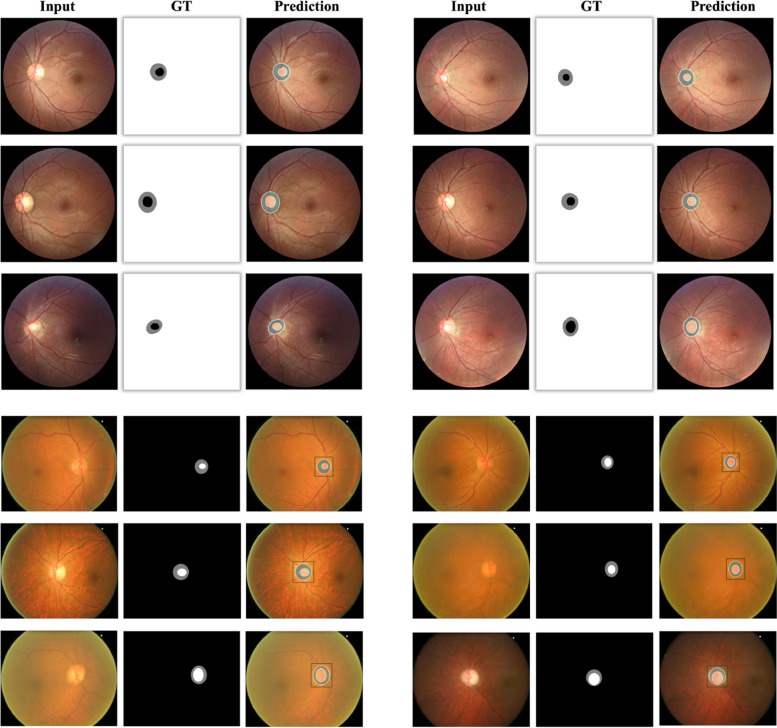
Image segmentation is a fundamental task in deep learning, which is able to analyse the essence of the images for further development. However, for the supervised learning segmentation method, collecting pixel-level labels is very time-consuming and labour-intensive. In the medical image processing area for optic disc and cup segmentation, we consider there are two challenging problems that remain unsolved. One is how to design an efficient network to capture the global field of the medical image and execute fast in real applications. The other is how to train the deep segmentation network using a few training data due to some medical privacy issues. In this paper, to conquer such issues, we first design a novel attention-aware segmentation model equipped with the multi-scale attention module in the pyramid structure-like encoder-decoder network, which can efficiently learn the global semantics and the long-range dependencies of the input images. Furthermore, we also inject the prior knowledge that the optic cup lies inside the optic disc by a novel loss function. Then, we propose a self-supervised contrastive learning method for optic disc and cup segmentation. The unsupervised feature representation is learned by matching an encoded query to a dictionary of encoded keys using a contrastive technique. Finetuning the pre-trained model using the proposed loss function can help achieve good performance for the task. To validate the effectiveness of the proposed method, extensive systemic evaluations on different public challenging optic disc and cup benchmarks, including DRISHTI-GS and REFUGE datasets demonstrate the superiority of the proposed method, which can achieve new state-of-the-art performance approaching 0.9801 and 0.9087 F1 score respectively while gaining 0.9657 and 0.8976 . The code will be made publicly available.
Keywords: Deep learning; Medical image processing; Optic disc and cup segmentation.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures





References
-
- Drance S, Anderson DR, Schulzer M, Collaborative Normal-Tension Glaucoma Study Group, et al. Risk factors for progression of visual field abnormalities in normal-tension glaucoma. Am J Ophthalmol. 2001;131(6):699–708. - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
