

A Machine Learning Model for Week-Ahead Hypoglycemia Prediction From Continuous Glucose Monitoring Data
- PMID: 38445628
- PMCID: PMC11572183
- DOI: 10.1177/19322968241236208
A Machine Learning Model for Week-Ahead Hypoglycemia Prediction From Continuous Glucose Monitoring Data
Abstract
Background: Remote patient monitoring (RPM) programs augment type 1 diabetes (T1D) care based on retrospective continuous glucose monitoring (CGM) data. Few methods are available to estimate the likelihood of a patient experiencing clinically significant hypoglycemia within one week.
Methods: We developed a machine learning model to estimate the probability that a patient will experience a clinically significant hypoglycemic event, defined as CGM readings below 54 mg/dL for at least 15 consecutive minutes, within one week. The model takes as input the patient's CGM time series over a given week, and outputs the predicted probability of a clinically significant hypoglycemic event the following week. We used 10-fold cross-validation and external validation (testing on cohorts different from the training cohort) to evaluate performance. We used CGM data from three different cohorts of patients with T1D: REPLACE-BG (226 patients), Juvenile Diabetes Research Foundation (JDRF; 355 patients) and Tidepool (120 patients).
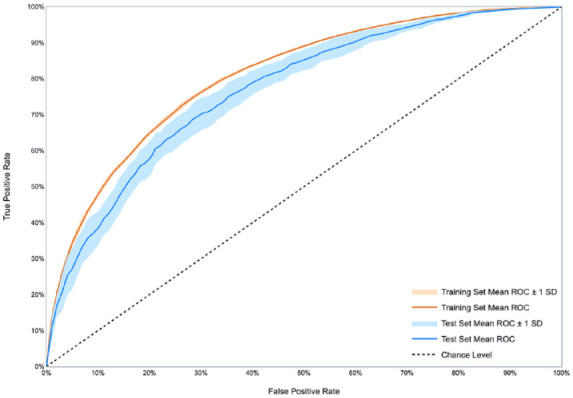
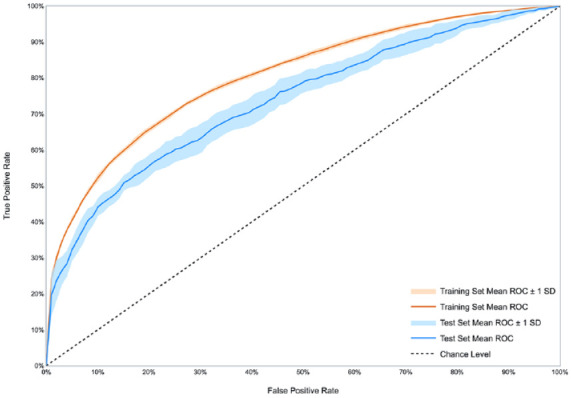
Results: In 10-fold cross-validation, the average area under the receiver operating characteristic curve (ROC-AUC) was 0.77 (standard deviation [SD]: 0.0233) on the REPLACE-BG cohort, 0.74 (SD: 0.0188) on the JDRF cohort, and 0.76 (SD: 0.02) on the Tidepool cohort. In external validation, the average ROC-AUC across the three cohorts was 0.74 (SD: 0.0262).
Conclusions: We developed a machine learning algorithm to estimate the probability of a clinically significant hypoglycemic event within one week. Predictive algorithms may provide diabetes care providers using RPM with additional context when prioritizing T1D patients for review.
Keywords: clinical decision support; continuous glucose monitoring; hypoglycemia prediction; machine learning; patient prioritization; type 1 diabetes.
Conflict of interest statement
Declaration of Conflicting InterestsThe author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: DS is an advisor to Carta Healthcare.
Figures





References
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
