

Exploring the potential of ChatGPT in medical dialogue summarization: a study on consistency with human preferences
- PMID: 38486198
- PMCID: PMC10938713
- DOI: 10.1186/s12911-024-02481-8
Exploring the potential of ChatGPT in medical dialogue summarization: a study on consistency with human preferences
Abstract
Background: Telemedicine has experienced rapid growth in recent years, aiming to enhance medical efficiency and reduce the workload of healthcare professionals. During the COVID-19 pandemic in 2019, it became especially crucial, enabling remote screenings and access to healthcare services while maintaining social distancing. Online consultation platforms have emerged, but the demand has strained the availability of medical professionals, directly leading to research and development in automated medical consultation. Specifically, there is a need for efficient and accurate medical dialogue summarization algorithms to condense lengthy conversations into shorter versions focused on relevant medical facts. The success of large language models like generative pre-trained transformer (GPT)-3 has recently prompted a paradigm shift in natural language processing (NLP) research. In this paper, we will explore its impact on medical dialogue summarization.
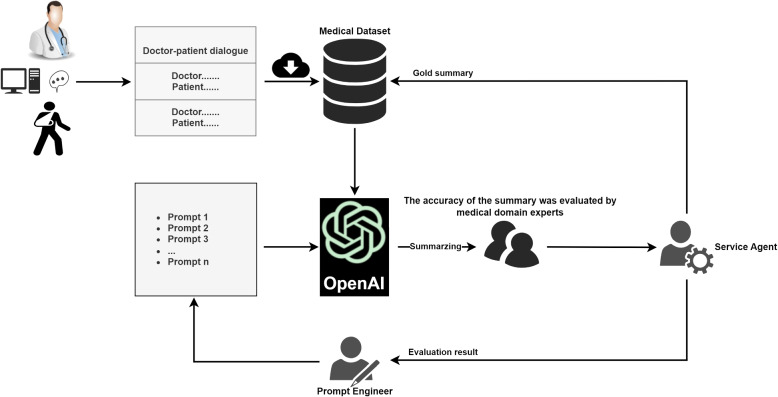
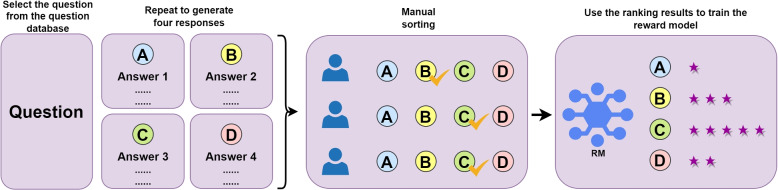
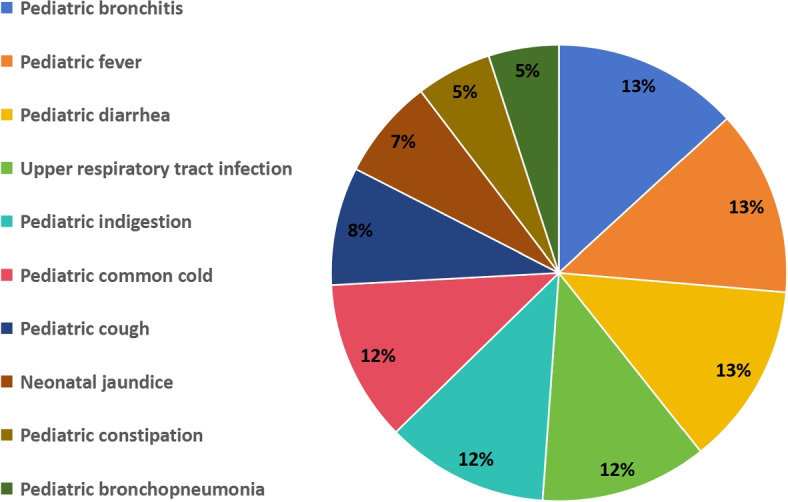
Methods: We present the performance and evaluation results of two approaches on a medical dialogue dataset. The first approach is based on fine-tuned pre-trained language models, such as bert-based summarization (BERTSUM) and bidirectional auto-regressive Transformers (BART). The second approach utilizes a large language models (LLMs) GPT-3.5 with inter-context learning (ICL). Evaluation is conducted using automated metrics such as ROUGE and BERTScore.
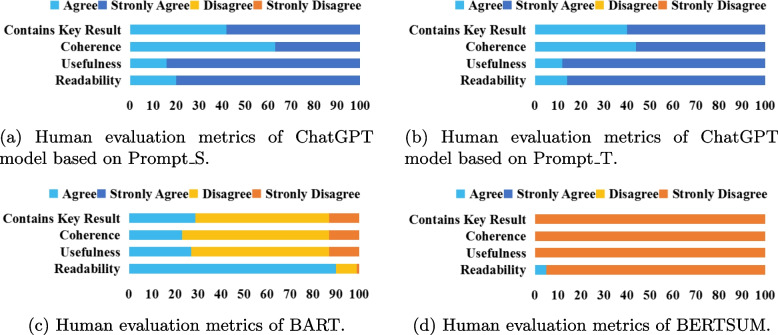
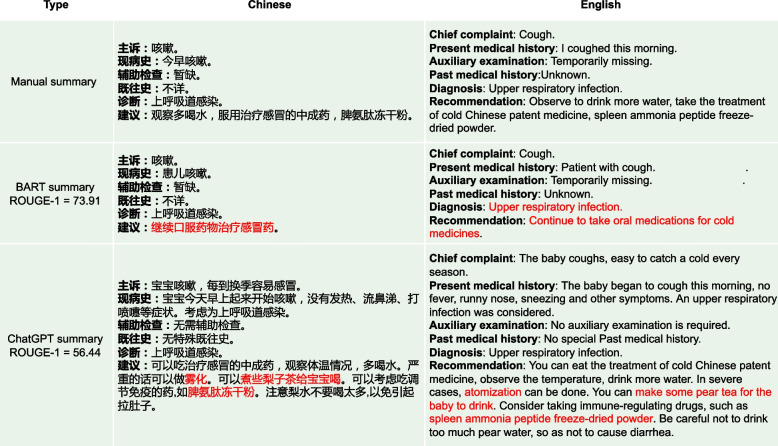
Results: In comparison to the BART and ChatGPT models, the summaries generated by the BERTSUM model not only exhibit significantly lower ROUGE and BERTScore values but also fail to pass the testing for any of the metrics in manual evaluation. On the other hand, the BART model achieved the highest ROUGE and BERTScore values among all evaluated models, surpassing ChatGPT. Its ROUGE-1, ROUGE-2, ROUGE-L, and BERTScore values were 14.94%, 53.48%, 32.84%, and 6.73% higher respectively than ChatGPT's best results. However, in the manual evaluation by medical experts, the summaries generated by the BART model exhibit satisfactory performance only in the "Readability" metric, with less than 30% passing the manual evaluation in other metrics. When compared to the BERTSUM and BART models, the ChatGPT model was evidently more favored by human medical experts.
Conclusion: On one hand, the GPT-3.5 model can manipulate the style and outcomes of medical dialogue summaries through various prompts. The generated content is not only better received than results from certain human experts but also more comprehensible, making it a promising avenue for automated medical dialogue summarization. On the other hand, automated evaluation mechanisms like ROUGE and BERTScore fall short in fully assessing the outputs of large language models like GPT-3.5. Therefore, it is necessary to research more appropriate evaluation criteria.
Keywords: Automated medical consultation; ChatGPT; Internet Healthcare; Large language models; Medical dialogue summarization.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures










Similar articles
-
Exploring the Efficacy of Large Language Models in Summarizing Mental Health Counseling Sessions: Benchmark Study.JMIR Ment Health. 2024 Jul 23;11:e57306. doi: 10.2196/57306. JMIR Ment Health. 2024. PMID: 39042893 Free PMC article.
-
Expert evaluation of large language models for clinical dialogue summarization.Sci Rep. 2025 Jan 7;15(1):1195. doi: 10.1038/s41598-024-84850-x. Sci Rep. 2025. PMID: 39774141 Free PMC article.
-
Summarizing Online Patient Conversations Using Generative Language Models: Experimental and Comparative Study.JMIR Med Inform. 2025 Apr 14;13:e62909. doi: 10.2196/62909. JMIR Med Inform. 2025. PMID: 40228244 Free PMC article.
-
Text summarization with ChatGPT for drug labeling documents.Drug Discov Today. 2024 Jun;29(6):104018. doi: 10.1016/j.drudis.2024.104018. Epub 2024 May 7. Drug Discov Today. 2024. PMID: 38723763 Review.
-
The Breakthrough of Large Language Models Release for Medical Applications: 1-Year Timeline and Perspectives.J Med Syst. 2024 Feb 17;48(1):22. doi: 10.1007/s10916-024-02045-3. J Med Syst. 2024. PMID: 38366043 Free PMC article. Review.
Cited by
-
Generative AI and future education: a review, theoretical validation, and authors' perspective on challenges and solutions.PeerJ Comput Sci. 2024 Dec 3;10:e2105. doi: 10.7717/peerj-cs.2105. eCollection 2024. PeerJ Comput Sci. 2024. PMID: 39650462 Free PMC article.
-
Exploring the Efficacy of Large Language Models in Summarizing Mental Health Counseling Sessions: Benchmark Study.JMIR Ment Health. 2024 Jul 23;11:e57306. doi: 10.2196/57306. JMIR Ment Health. 2024. PMID: 39042893 Free PMC article.
-
Evaluating the Impact of Artificial Intelligence (AI) on Clinical Documentation Efficiency and Accuracy Across Clinical Settings: A Scoping Review.Cureus. 2024 Nov 19;16(11):e73994. doi: 10.7759/cureus.73994. eCollection 2024 Nov. Cureus. 2024. PMID: 39703286 Free PMC article.
-
A Review of Large Language Models in Medical Education, Clinical Decision Support, and Healthcare Administration.Healthcare (Basel). 2025 Mar 10;13(6):603. doi: 10.3390/healthcare13060603. Healthcare (Basel). 2025. PMID: 40150453 Free PMC article. Review.
-
The use of large language models to enhance cancer clinical trial educational materials.JNCI Cancer Spectr. 2025 Mar 3;9(2):pkaf021. doi: 10.1093/jncics/pkaf021. JNCI Cancer Spectr. 2025. PMID: 39921887 Free PMC article.
References
-
- Jain R, Jangra A, Saha S, Jatowt A. A survey on medical document summarization. 2022. arXiv preprint arXiv:2212.01669
-
- Navarro DF, Dras M, Berkovsky S. Few-shot fine-tuning SOTA summarization models for medical dialogues. In: Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Student Research Workshop. 2022. p. 254–266. https://aclanthology.org/2022.naacl-srw.32/.
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
