

Utilizing large language models in breast cancer management: systematic review
- PMID: 38504034
- PMCID: PMC10950983
- DOI: 10.1007/s00432-024-05678-6
Utilizing large language models in breast cancer management: systematic review
Abstract
Purpose: Despite advanced technologies in breast cancer management, challenges remain in efficiently interpreting vast clinical data for patient-specific insights. We reviewed the literature on how large language models (LLMs) such as ChatGPT might offer solutions in this field.
Methods: We searched MEDLINE for relevant studies published before December 22, 2023. Keywords included: "large language models", "LLM", "GPT", "ChatGPT", "OpenAI", and "breast". The risk bias was evaluated using the QUADAS-2 tool.
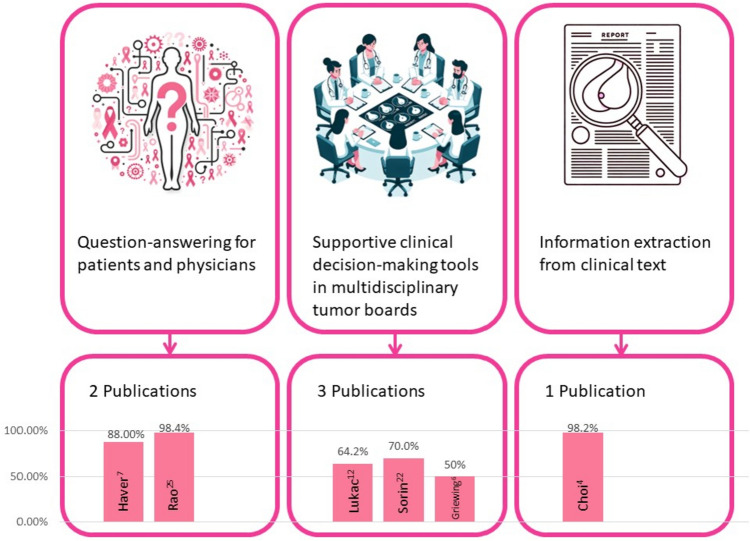
Results: Six studies evaluating either ChatGPT-3.5 or GPT-4, met our inclusion criteria. They explored clinical notes analysis, guideline-based question-answering, and patient management recommendations. Accuracy varied between studies, ranging from 50 to 98%. Higher accuracy was seen in structured tasks like information retrieval. Half of the studies used real patient data, adding practical clinical value. Challenges included inconsistent accuracy, dependency on the way questions are posed (prompt-dependency), and in some cases, missing critical clinical information.
Conclusion: LLMs hold potential in breast cancer care, especially in textual information extraction and guideline-driven clinical question-answering. Yet, their inconsistent accuracy underscores the need for careful validation of these models, and the importance of ongoing supervision.
Keywords: Artificial intelligence; Breast cancer; GPT; Large language models.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
The authors declare that they have no conflict of interest.
Figures
References
-
- Brin D, Sorin V, Konen E, Nadkarni G, Glicksberg BS, Klang E (2023) How large language models perform on the united states medical licensing examination: a systematic review. medRxiv 23:543
-
- Bubeck S, Chandrasekaran V, Eldan R, et al. (2023) Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712
-
- Chaudhry HJ, Katsufrakis PJ, Tallia AF (2020) The USMLE step 1 decision. JAMA 323(20):2017 - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Miscellaneous
