

Population coding of time-varying sounds in the nonlemniscal inferior colliculus
- PMID: 38505907
- PMCID: PMC11381119
- DOI: 10.1152/jn.00013.2024
Population coding of time-varying sounds in the nonlemniscal inferior colliculus
Abstract
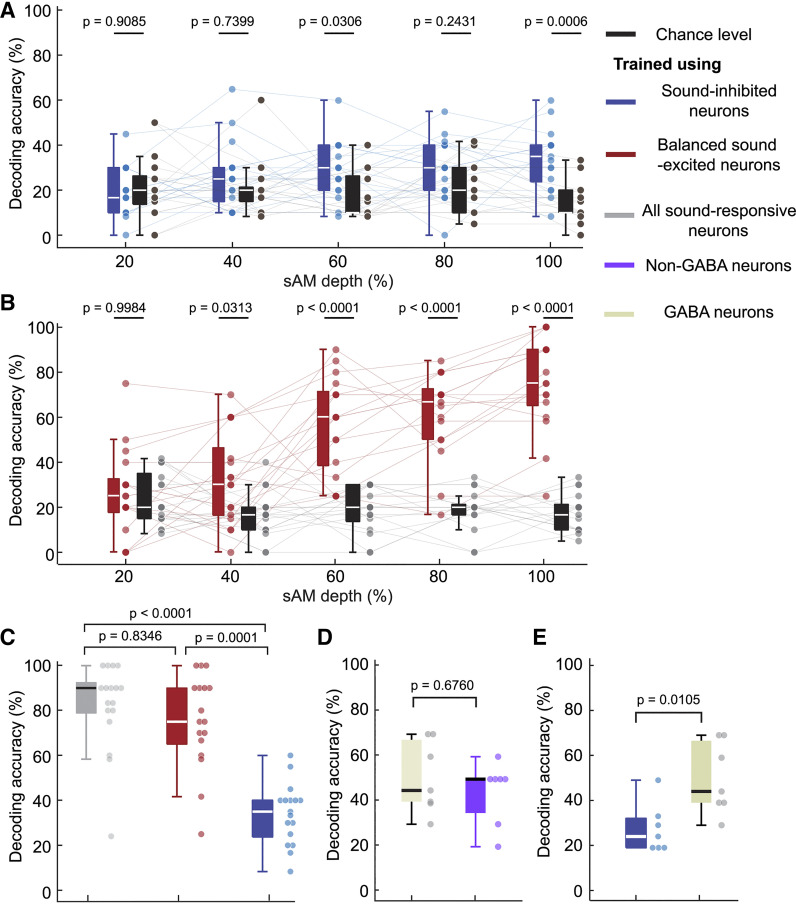
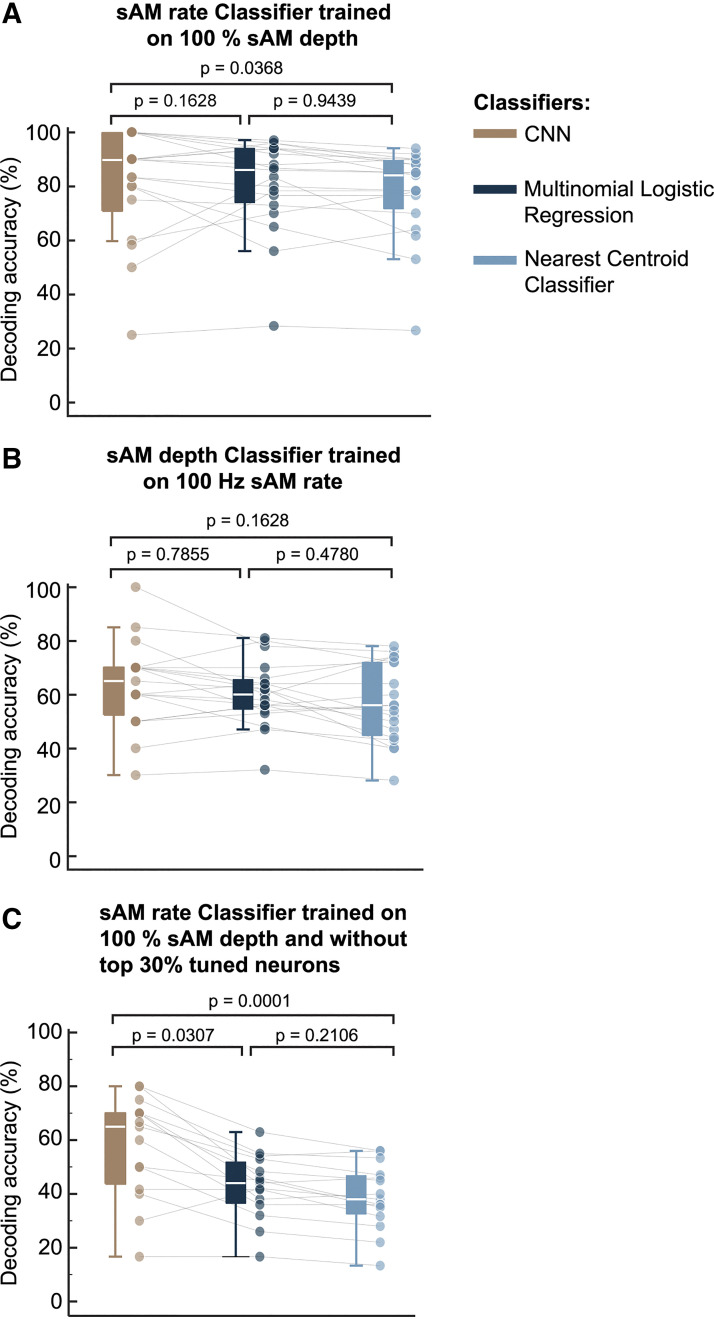
The inferior colliculus (IC) of the midbrain is important for complex sound processing, such as discriminating conspecific vocalizations and human speech. The IC's nonlemniscal, dorsal "shell" region is likely important for this process, as neurons in these layers project to higher-order thalamic nuclei that subsequently funnel acoustic signals to the amygdala and nonprimary auditory cortices, forebrain circuits important for vocalization coding in a variety of mammals, including humans. However, the extent to which shell IC neurons transmit acoustic features necessary to discern vocalizations is less clear, owing to the technical difficulty of recording from neurons in the IC's superficial layers via traditional approaches. Here, we use two-photon Ca2+ imaging in mice of either sex to test how shell IC neuron populations encode the rate and depth of amplitude modulation, important sound cues for speech perception. Most shell IC neurons were broadly tuned, with a low neurometric discrimination of amplitude modulation rate; only a subset was highly selective to specific modulation rates. Nevertheless, neural network classifier trained on fluorescence data from shell IC neuron populations accurately classified amplitude modulation rate, and decoding accuracy was only marginally reduced when highly tuned neurons were omitted from training data. Rather, classifier accuracy increased monotonically with the modulation depth of the training data, such that classifiers trained on full-depth modulated sounds had median decoding errors of ∼0.2 octaves. Thus, shell IC neurons may transmit time-varying signals via a population code, with perhaps limited reliance on the discriminative capacity of any individual neuron.NEW & NOTEWORTHY The IC's shell layers originate a "nonlemniscal" pathway important for perceiving vocalization sounds. However, prior studies suggest that individual shell IC neurons are broadly tuned and have high response thresholds, implying a limited reliability of efferent signals. Using Ca2+ imaging, we show that amplitude modulation is accurately represented in the population activity of shell IC neurons. Thus, downstream targets can read out sounds' temporal envelopes from distributed rate codes transmitted by populations of broadly tuned neurons.
Keywords: amplitude modulation; auditory system; calcium imaging; inferior colliculus.
Conflict of interest statement
No conflicts of interest, financial or otherwise, are declared by the authors.
Figures









Update of
-
Population coding of time-varying sounds in the non-lemniscal Inferior Colliculus.bioRxiv [Preprint]. 2023 Aug 16:2023.08.14.553263. doi: 10.1101/2023.08.14.553263. bioRxiv. 2023. Update in: J Neurophysiol. 2024 May 1;131(5):842-864. doi: 10.1152/jn.00013.2024. PMID: 37645904 Free PMC article. Updated. Preprint.
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous