

A universal molecular control for DNA, mRNA and protein expression
- PMID: 38509097
- PMCID: PMC10954659
- DOI: 10.1038/s41467-024-46456-9
A universal molecular control for DNA, mRNA and protein expression
Abstract
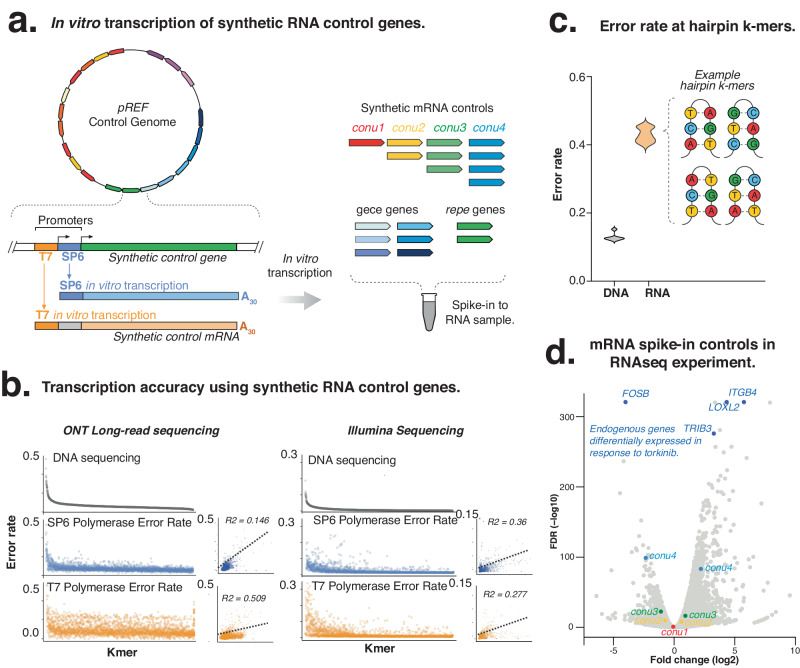
The expression of genes encompasses their transcription into mRNA followed by translation into protein. In recent years, next-generation sequencing and mass spectrometry methods have profiled DNA, RNA and protein abundance in cells. However, there are currently no reference standards that are compatible across these genomic, transcriptomic and proteomic methods, and provide an integrated measure of gene expression. Here, we use synthetic biology principles to engineer a multi-omics control, termed pREF, that can act as a universal molecular standard for next-generation sequencing and mass spectrometry methods. The pREF sequence encodes 21 synthetic genes that can be in vitro transcribed into spike-in mRNA controls, and in vitro translated to generate matched protein controls. The synthetic genes provide qualitative controls that can measure sensitivity and quantitative accuracy of DNA, RNA and peptide detection. We demonstrate the use of pREF in metagenome DNA sequencing and RNA sequencing experiments and evaluate the quantification of proteins using mass spectrometry. Unlike previous spike-in controls, pREF can be independently propagated and the synthetic mRNA and protein controls can be sustainably prepared by recipient laboratories using common molecular biology techniques. Together, this provides a universal synthetic standard able to integrate genomic, transcriptomic and proteomic methods.
© 2024. The Author(s).
Conflict of interest statement
The Garvan Institute has filed patents covering aspects of this study. T.R.M. and H.M.G. have received financial support from Oxford Nanopore Technologies for travel, accommodations and research costs. The other authors declare no competing interests.
Figures




References
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
