

Ensemble pretrained language models to extract biomedical knowledge from literature
- PMID: 38520725
- PMCID: PMC11339500
- DOI: 10.1093/jamia/ocae061
Ensemble pretrained language models to extract biomedical knowledge from literature
Abstract
Objectives: The rapid expansion of biomedical literature necessitates automated techniques to discern relationships between biomedical concepts from extensive free text. Such techniques facilitate the development of detailed knowledge bases and highlight research deficiencies. The LitCoin Natural Language Processing (NLP) challenge, organized by the National Center for Advancing Translational Science, aims to evaluate such potential and provides a manually annotated corpus for methodology development and benchmarking.
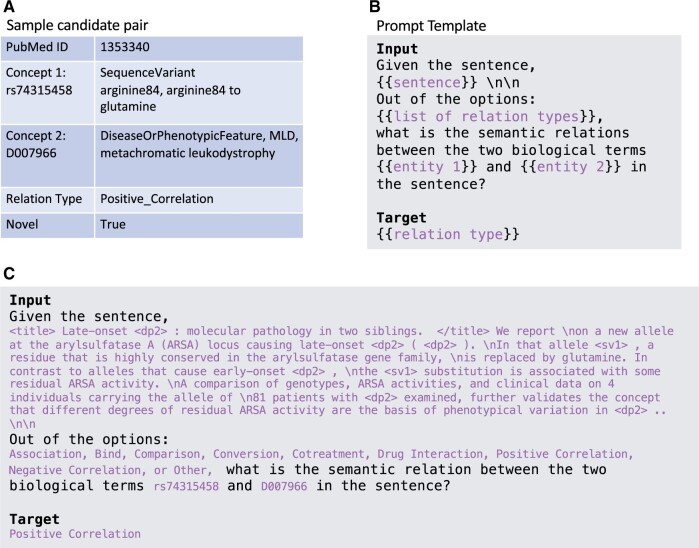
Materials and methods: For the named entity recognition (NER) task, we utilized ensemble learning to merge predictions from three domain-specific models, namely BioBERT, PubMedBERT, and BioM-ELECTRA, devised a rule-driven detection method for cell line and taxonomy names and annotated 70 more abstracts as additional corpus. We further finetuned the T0pp model, with 11 billion parameters, to boost the performance on relation extraction and leveraged entites' location information (eg, title, background) to enhance novelty prediction performance in relation extraction (RE).
Results: Our pioneering NLP system designed for this challenge secured first place in Phase I-NER and second place in Phase II-relation extraction and novelty prediction, outpacing over 200 teams. We tested OpenAI ChatGPT 3.5 and ChatGPT 4 in a Zero-Shot setting using the same test set, revealing that our finetuned model considerably surpasses these broad-spectrum large language models.
Discussion and conclusion: Our outcomes depict a robust NLP system excelling in NER and RE across various biomedical entities, emphasizing that task-specific models remain superior to generic large ones. Such insights are valuable for endeavors like knowledge graph development and hypothesis formulation in biomedical research.
Keywords: ensemble learning; knowledge base; large language model; named entity recognition; relation extraction.
© The Author(s) 2024. Published by Oxford University Press on behalf of the American Medical Informatics Association.
Conflict of interest statement
None declared.
Figures


References
-
- Leser U, Hakenberg J. What makes a gene name? Named entity recognition in the biomedical literature. Brief Bioinform. 2005;6(4):357-369. - PubMed
-
- Song B, Li F, Liu Y, Zeng X. Deep learning methods for biomedical named entity recognition: a survey and qualitative comparison. Brief Bioinform. 2021;22(6):bbab282. - PubMed
-
- Huang Z, Xu W, Yu K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 150801991, 2015, preprint: not peer reviewed. https://arxiv.org/abs/1508.01991
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
