

Precise prediction of phase-separation key residues by machine learning
- PMID: 38531854
- PMCID: PMC10965946
- DOI: 10.1038/s41467-024-46901-9
Precise prediction of phase-separation key residues by machine learning
Abstract
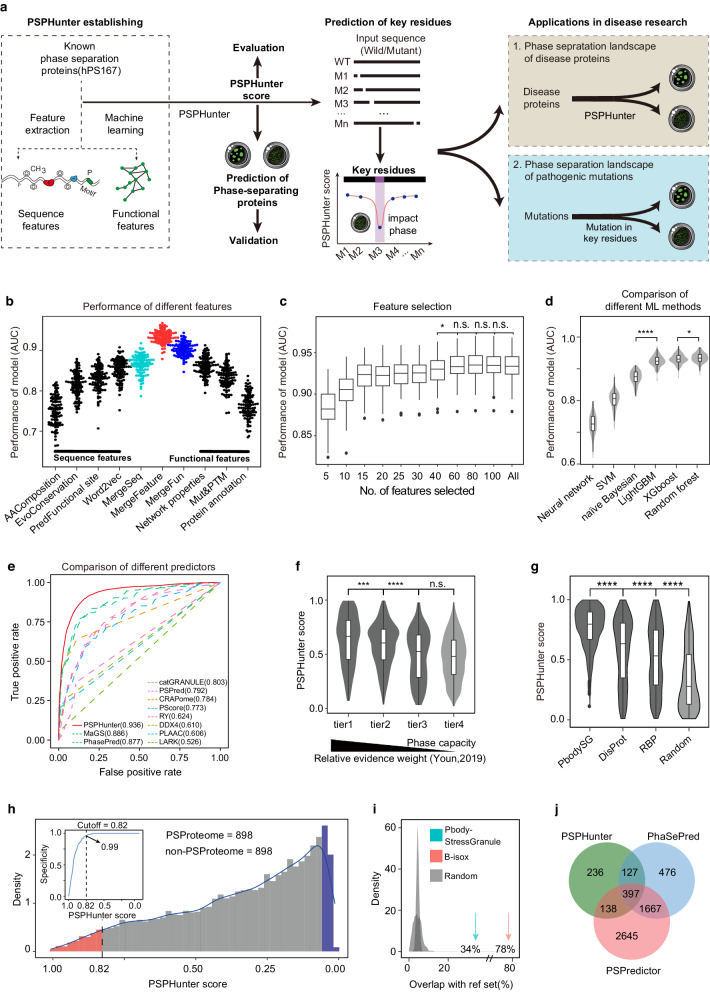
Understanding intracellular phase separation is crucial for deciphering transcriptional control, cell fate transitions, and disease mechanisms. However, the key residues, which impact phase separation the most for protein phase separation function have remained elusive. We develop PSPHunter, which can precisely predict these key residues based on machine learning scheme. In vivo and in vitro validations demonstrate that truncating just 6 key residues in GATA3 disrupts phase separation, enhancing tumor cell migration and inhibiting growth. Glycine and its motifs are enriched in spacer and key residues, as revealed by our comprehensive analysis. PSPHunter identifies nearly 80% of disease-associated phase-separating proteins, with frequent mutated pathological residues like glycine and proline often residing in these key residues. PSPHunter thus emerges as a crucial tool to uncover key residues, facilitating insights into phase separation mechanisms governing transcriptional control, cell fate transitions, and disease development.
© 2024. The Author(s).
Conflict of interest statement
J.D., J.S., J.Q. and C.Z. are listed as inventors of a patent applications titled ‘A machine learning method for predicting phase separation driving residues’, the remaining authors declare no competing interests.
Figures






References
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
