

Alignment of brain embeddings and artificial contextual embeddings in natural language points to common geometric patterns
- PMID: 38553456
- PMCID: PMC10980748
- DOI: 10.1038/s41467-024-46631-y
Alignment of brain embeddings and artificial contextual embeddings in natural language points to common geometric patterns
Erratum in
-
Author Correction: Alignment of brain embeddings and artificial contextual embeddings in natural language points to common geometric patterns.Nat Commun. 2024 Oct 1;15(1):8500. doi: 10.1038/s41467-024-52626-6. Nat Commun. 2024. PMID: 39353920 Free PMC article. No abstract available.
Abstract
Contextual embeddings, derived from deep language models (DLMs), provide a continuous vectorial representation of language. This embedding space differs fundamentally from the symbolic representations posited by traditional psycholinguistics. We hypothesize that language areas in the human brain, similar to DLMs, rely on a continuous embedding space to represent language. To test this hypothesis, we densely record the neural activity patterns in the inferior frontal gyrus (IFG) of three participants using dense intracranial arrays while they listened to a 30-minute podcast. From these fine-grained spatiotemporal neural recordings, we derive a continuous vectorial representation for each word (i.e., a brain embedding) in each patient. Using stringent zero-shot mapping we demonstrate that brain embeddings in the IFG and the DLM contextual embedding space have common geometric patterns. The common geometric patterns allow us to predict the brain embedding in IFG of a given left-out word based solely on its geometrical relationship to other non-overlapping words in the podcast. Furthermore, we show that contextual embeddings capture the geometry of IFG embeddings better than static word embeddings. The continuous brain embedding space exposes a vector-based neural code for natural language processing in the human brain.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
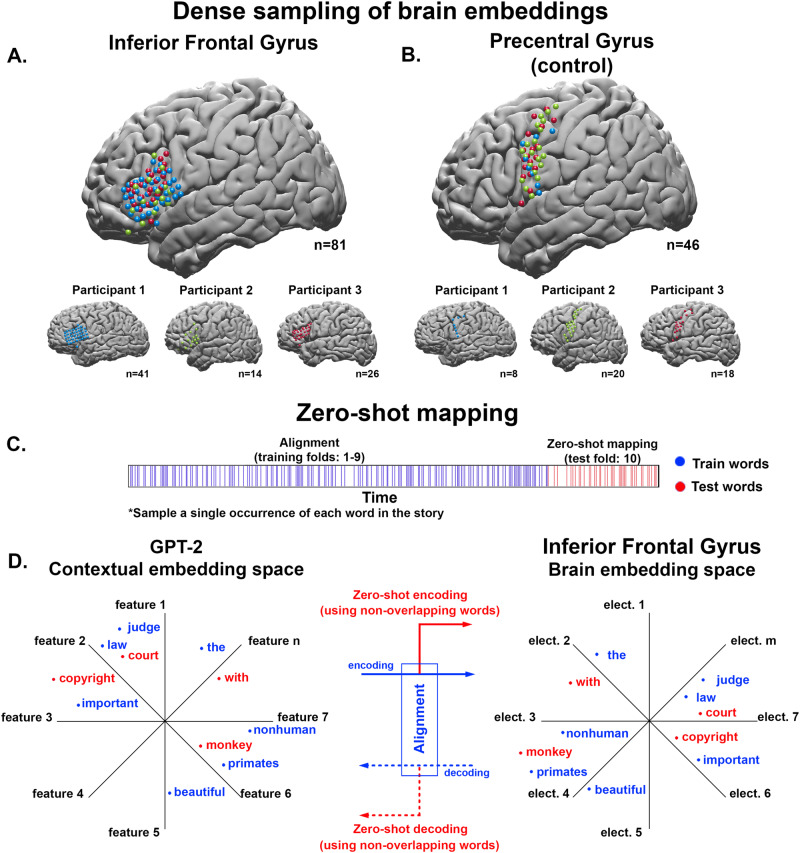
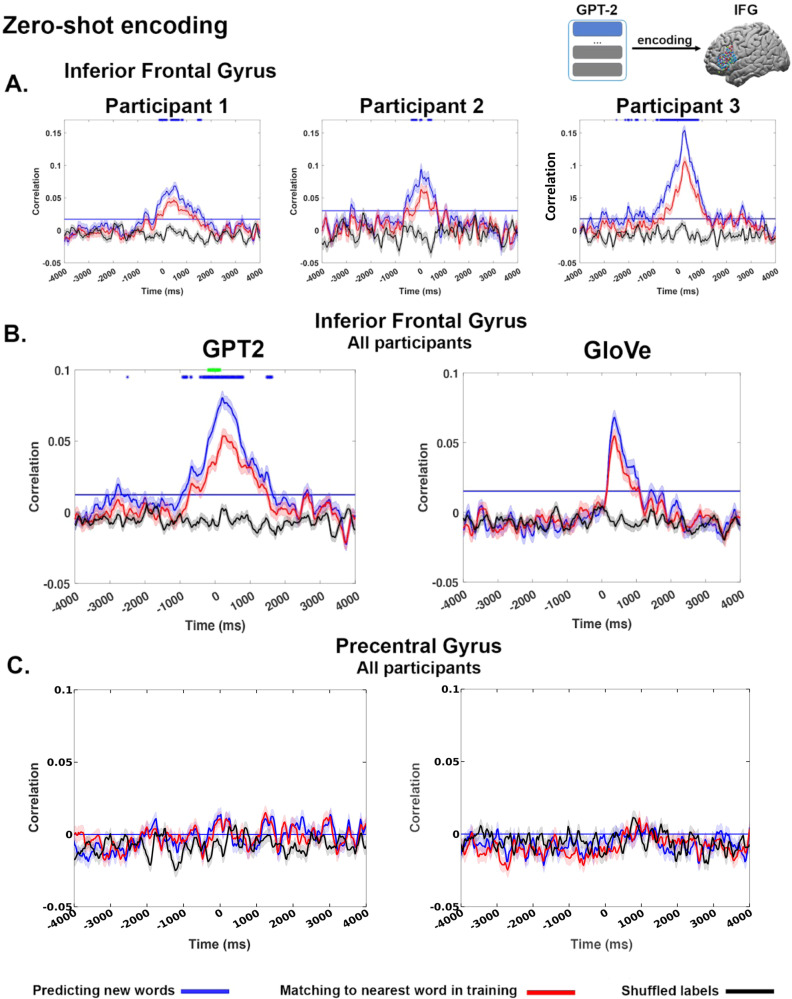
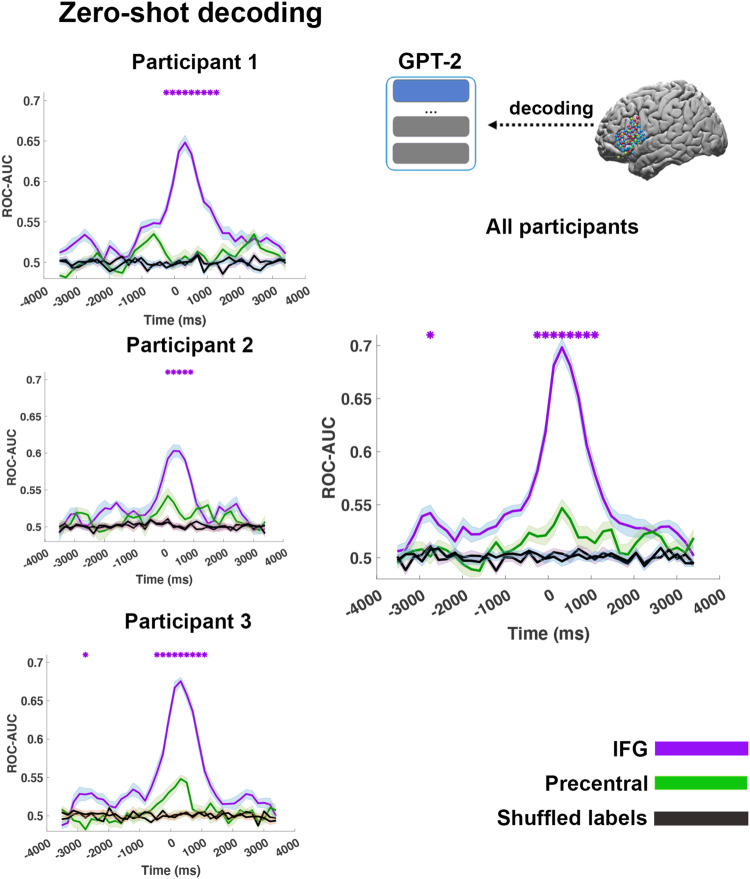
References
-
- Lees, R. B. & Chomsky, N. Syntactic structures. Language33, 375 (1957).
-
- Fodor, J. A. The Language of Thought (Harvard Univ. Press, 1975).
-
- Landauer, T. K. & Dumais, S. T. A solution to Plato’s problem: the latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychol. Rev.104, 211–240 (1997).
-
- Pennington, J., Socher, R. & Manning, C. Glove: global vectors for word representation. In Proc. 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) 1532–1543 (Association for Computational Linguistics, 2014).
-
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S. & Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems (eds. Burges, C. J. C., Bottou, L., Welling, M., Ghahramani, Z. & Weinberger, K. Q.) (Curran Associates Inc., 2013).
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
