

The RNA secondary structure of androgen receptor-FL and V7 transcripts reveals novel regulatory regions
- PMID: 38554103
- PMCID: PMC11194067
- DOI: 10.1093/nar/gkae220
The RNA secondary structure of androgen receptor-FL and V7 transcripts reveals novel regulatory regions
Abstract
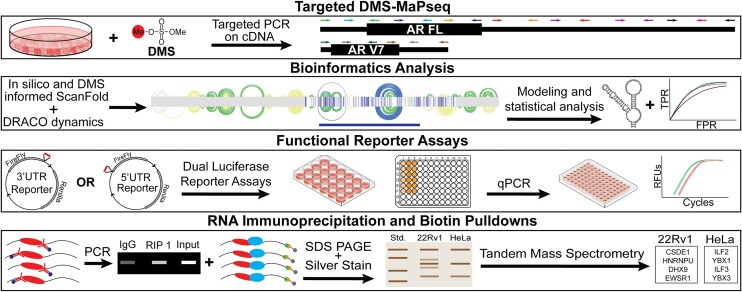
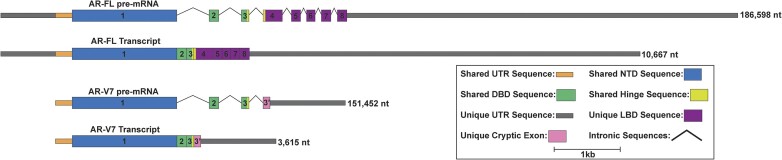
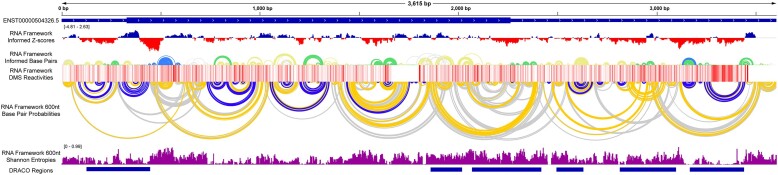
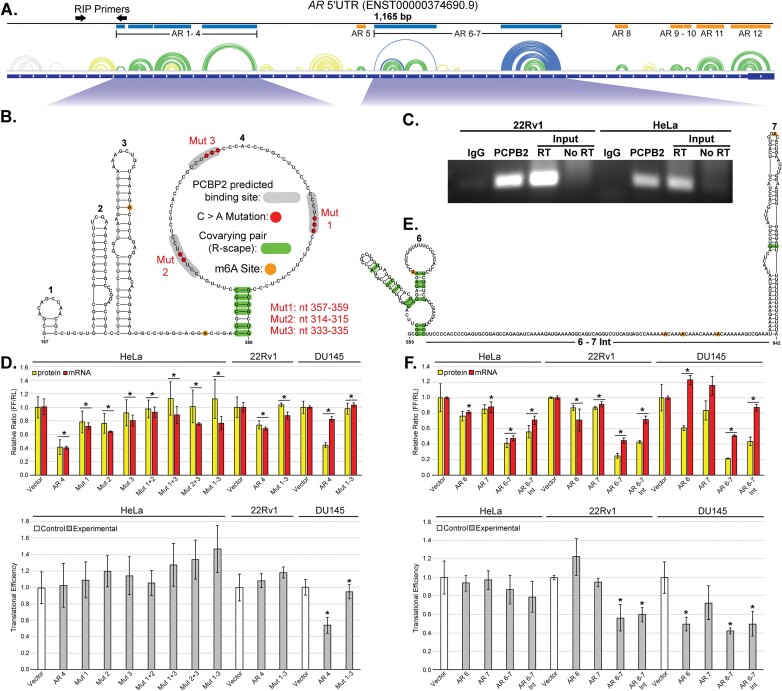
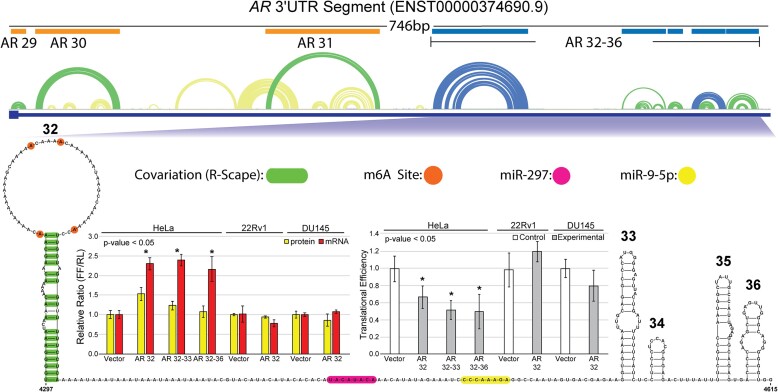
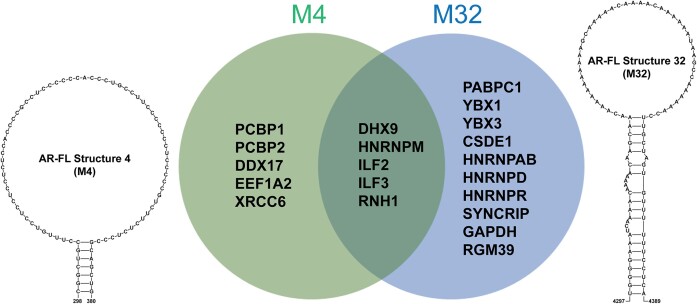
The androgen receptor (AR) is a ligand-dependent nuclear transcription factor belonging to the steroid hormone nuclear receptor family. Due to its roles in regulating cell proliferation and differentiation, AR is tightly regulated to maintain proper levels of itself and the many genes it controls. AR dysregulation is a driver of many human diseases including prostate cancer. Though this dysregulation often occurs at the RNA level, there are many unknowns surrounding post-transcriptional regulation of AR mRNA, particularly the role that RNA secondary structure plays. Thus, a comprehensive analysis of AR transcript secondary structure is needed. We address this through the computational and experimental analyses of two key isoforms, full length (AR-FL) and truncated (AR-V7). Here, a combination of in-cell RNA secondary structure probing experiments (targeted DMS-MaPseq) and computational predictions were used to characterize the static structural landscape and conformational dynamics of both isoforms. Additionally, in-cell assays were used to identify functionally relevant structures in the 5' and 3' UTRs of AR-FL. A notable example is a conserved stem loop structure in the 5'UTR of AR-FL that can bind to Poly(RC) Binding Protein 2 (PCBP2). Taken together, our results reveal novel features that regulate AR expression.
© The Author(s) 2024. Published by Oxford University Press on behalf of Nucleic Acids Research.
Figures

Similar articles
-
Androgen receptor and its splice variant, AR-V7, differentially regulate FOXA1 sensitive genes in LNCaP prostate cancer cells.Int J Biochem Cell Biol. 2014 Sep;54:49-59. doi: 10.1016/j.biocel.2014.06.013. Epub 2014 Jul 4. Int J Biochem Cell Biol. 2014. PMID: 25008967 Free PMC article.
-
Expression of androgen receptor splice variants in prostate cancer bone metastases is associated with castration-resistance and short survival.PLoS One. 2011 Apr 28;6(4):e19059. doi: 10.1371/journal.pone.0019059. PLoS One. 2011. PMID: 21552559 Free PMC article.
-
Distinct transcriptional programs mediated by the ligand-dependent full-length androgen receptor and its splice variants in castration-resistant prostate cancer.Cancer Res. 2012 Jul 15;72(14):3457-62. doi: 10.1158/0008-5472.CAN-11-3892. Epub 2012 Jun 18. Cancer Res. 2012. PMID: 22710436 Free PMC article.
-
Molecular Origin, Expression Regulation, and Biological Function of Androgen Receptor Splicing Variant 7 in Prostate Cancer.Urol Int. 2021;105(5-6):337-353. doi: 10.1159/000510124. Epub 2020 Sep 21. Urol Int. 2021. PMID: 32957106 Review.
-
Role of androgen receptor splice variants, their clinical relevance and treatment options.World J Urol. 2020 Mar;38(3):647-656. doi: 10.1007/s00345-018-02619-0. Epub 2019 Jan 19. World J Urol. 2020. PMID: 30659302 Review.
Cited by
-
Identification of a conserved RNA structure in the TNFRSF1A 3'UTR: Implications for post-transcriptional regulation.bioRxiv [Preprint]. 2025 Jun 19:2025.06.18.660452. doi: 10.1101/2025.06.18.660452. bioRxiv. 2025. PMID: 40611903 Free PMC article. Preprint.
References
-
- Tsai M.J., O’Malley B.W Molecular mechanisms of action of steroid/thyroid receptor superfamily members. Annu. Rev. Biochem. 1994; 63:451–486. - PubMed
-
- Yeh S., Tsai M.Y., Xu Q., Mu X.M., Lardy H., Huang K.E., Lin H., Yeh S.D., Altuwaijri S., Zhou X. et al. . Generation and characterization of androgen receptor knockout (ARKO) mice: an in vivo model for the study of androgen functions in selective tissues. Proc. Natl. Acad. Sci. U.S.A. 2002; 99:13498–13503. - PMC - PubMed
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
