

DSGA-Net: Deeply separable gated transformer and attention strategy for medical image segmentation network
- PMID: 38559323
- PMCID: PMC7615776
- DOI: 10.1016/j.jksuci.2023.04.006
DSGA-Net: Deeply separable gated transformer and attention strategy for medical image segmentation network
Abstract
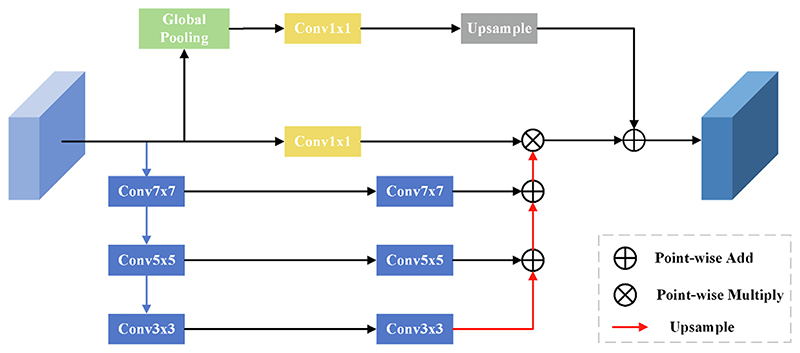
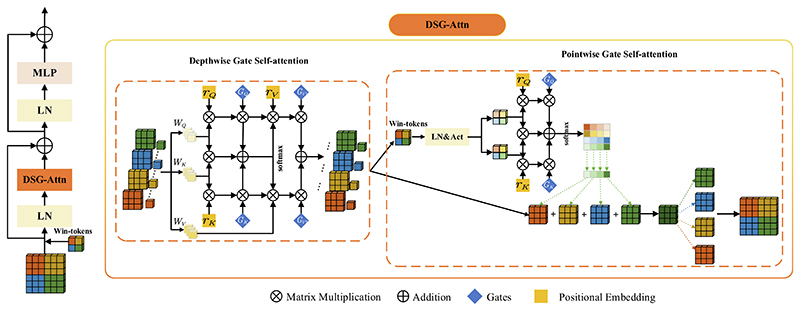
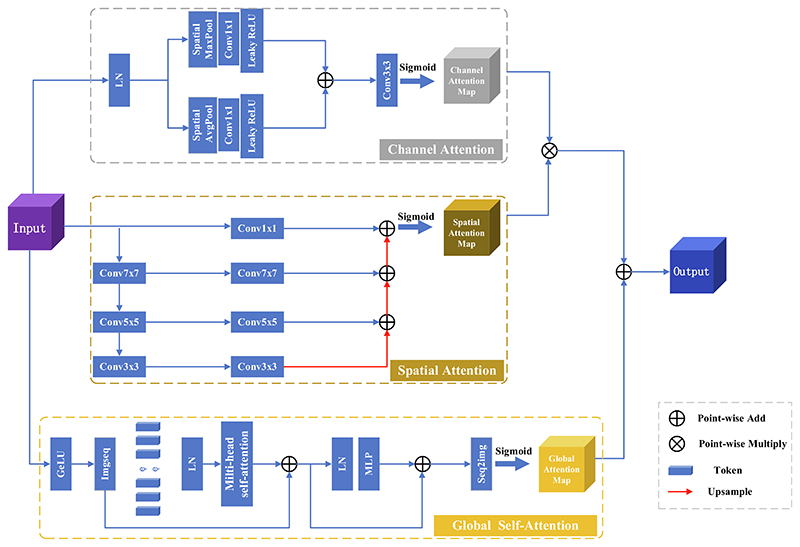
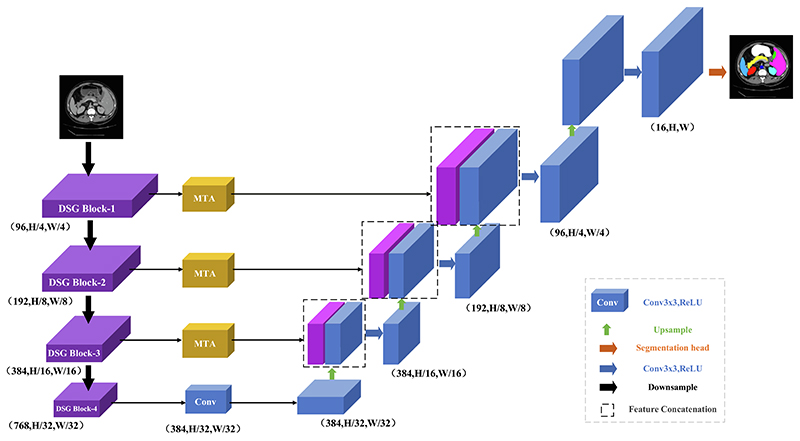
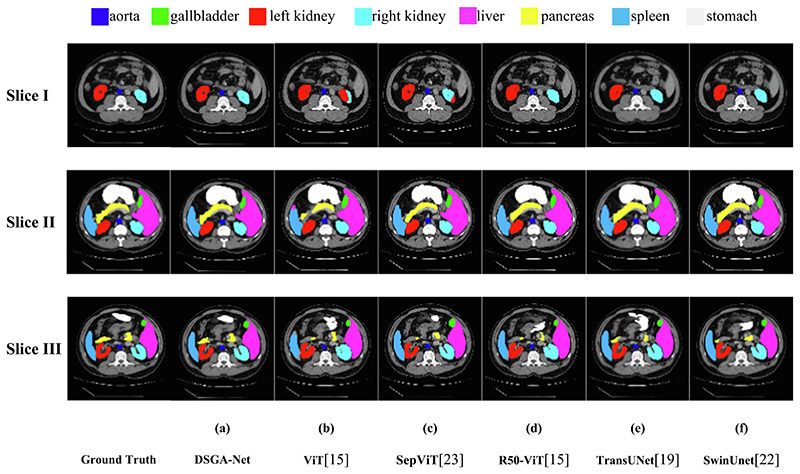
To address the problems of under-segmentation and over-segmentation of small organs in medical image segmentation. We present a novel medical image segmentation network model with Depth Separable Gating Transformer and a Three-branch Attention module (DSGA-Net). Firstly, the model adds a Depth Separable Gated Visual Transformer (DSG-ViT) module into its Encoder to enhance (i) the contextual links among global, local, and channels and (ii) the sensitivity to location information. Secondly, a Mixed Three-branch Attention (MTA) module is proposed to increase the number of features in the up-sampling process. Meanwhile, the loss of feature information is reduced when restoring the feature image to the original image size. By validating Synapse, BraTs2020, and ACDC public datasets, the Dice Similarity Coefficient (DSC) of the results of DSGA-Net reached 81.24%,85.82%, and 91.34%, respectively. Moreover, the Hausdorff Score (HD) decreased to 20.91% and 5.27% on the Synapse and BraTs2020. There are 10.78% and 0.69% decreases compared to the Baseline TransUNet. The experimental results indicate that DSGA-Net achieves better segmentation than most advanced methods.
Keywords: Depth separable; Gated attention mechanism; Medical image segmentation; Transformer.
Conflict of interest statement
Declaration of Competing Interest The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Figures
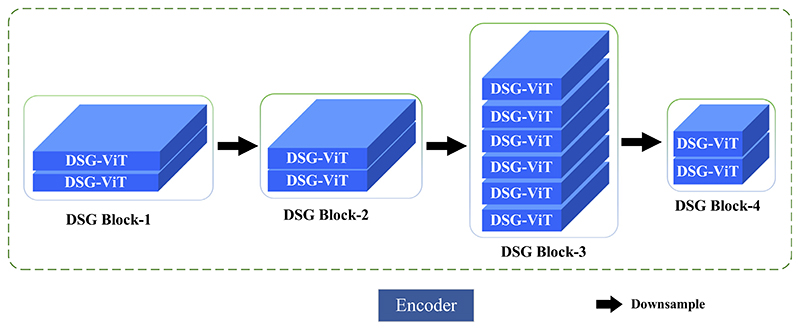
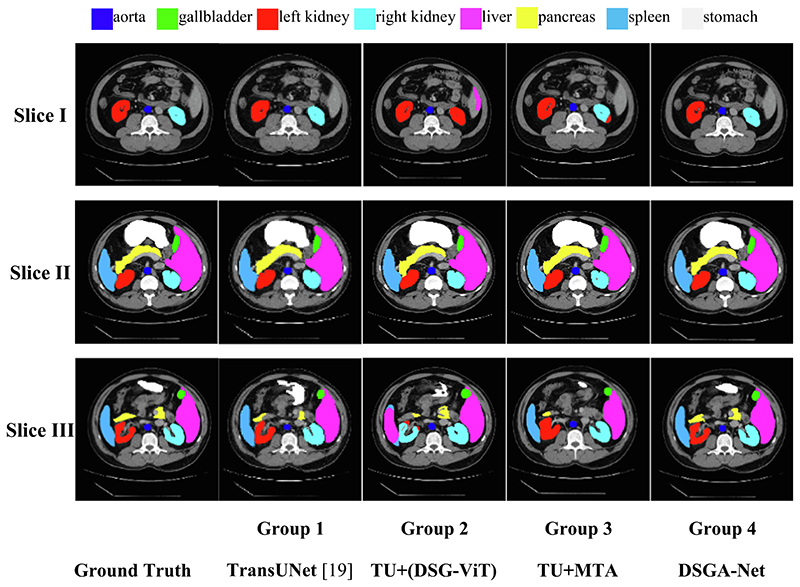
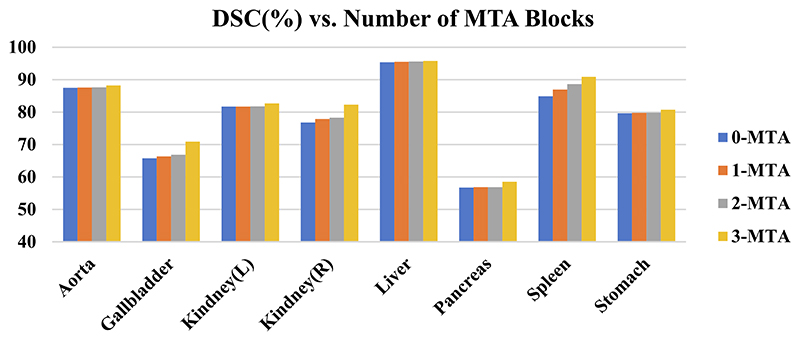
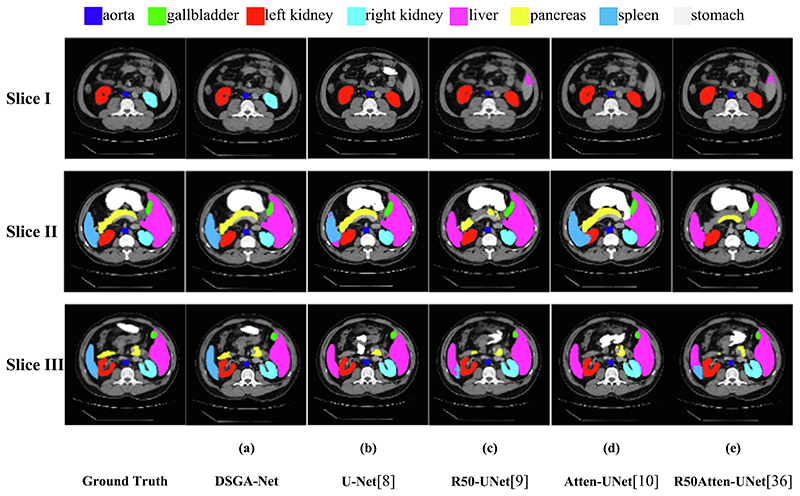
References
-
- Bitter C, Elizondo DA, Yang Y. Natural language processing: a prolog perspective. Artif Intell Rev. 2010;33(1-2):151.
-
- Cao H, Wang Y, Chen J, Jiang D, Zhang X, Tian Q, Wang M. Swin-unet: Unet-like pure transformer for medical image segmentation; Computer Vision–ECCV 2022 Workshops: Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part III; Cham. 2023. Feb, pp. 205–218.
-
- Chen J, Lu Y, Yu Q, Luo X, Adeli E, Wang Y, et al. Zhou Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv preprint. 2021:arXiv:2102.04306
-
- Chen B, Liu Y, Zhang Z, Lu G, Kong AWK. Transattunet: Multi-level attention-guided u-net with transformer for medical image segmentation. arXiv preprint. 2021:arXiv:2107.05274
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous