

Assessing the Efficacy of Large Language Models in Health Literacy: A Comprehensive Cross-Sectional Study
- PMID: 38559461
- PMCID: PMC10964816
- DOI: 10.59249/ZTOZ1966
Assessing the Efficacy of Large Language Models in Health Literacy: A Comprehensive Cross-Sectional Study
Abstract
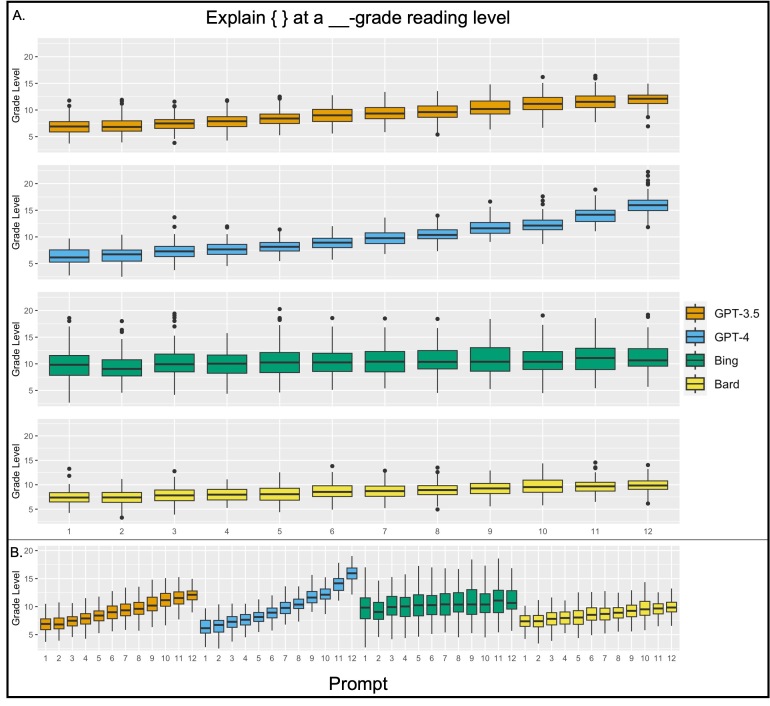
Enhanced health literacy in children has been empirically linked to better health outcomes over the long term; however, few interventions have been shown to improve health literacy. In this context, we investigate whether large language models (LLMs) can serve as a medium to improve health literacy in children. We tested pediatric conditions using 26 different prompts in ChatGPT-3.5, ChatGPT-4, Microsoft Bing, and Google Bard (now known as Google Gemini). The primary outcome measurement was the reading grade level (RGL) of output as assessed by Gunning Fog, Flesch-Kincaid Grade Level, Automated Readability Index, and Coleman-Liau indices. Word counts were also assessed. Across all models, output for basic prompts such as "Explain" and "What is (are)," were at, or exceeded, the tenth-grade RGL. When prompts were specified to explain conditions from the first- to twelfth-grade level, we found that LLMs had varying abilities to tailor responses based on grade level. ChatGPT-3.5 provided responses that ranged from the seventh-grade to college freshmen RGL while ChatGPT-4 outputted responses from the tenth-grade to the college senior RGL. Microsoft Bing provided responses from the ninth- to eleventh-grade RGL while Google Bard provided responses from the seventh- to tenth-grade RGL. LLMs face challenges in crafting outputs below a sixth-grade RGL. However, their capability to modify outputs above this threshold, provides a potential mechanism for adolescents to explore, understand, and engage with information regarding their health conditions, spanning from simple to complex terms. Future studies are needed to verify the accuracy and efficacy of these tools.
Keywords: Artificial Intelligence; ChatGPT; Google Bard; Google Gemini; Health Literacy; Large Language Models; Microsoft Bing; Pediatrics; Reading Grade Level.
Copyright ©2024, Yale Journal of Biology and Medicine.
Figures


Similar articles
-
Proficiency, Clarity, and Objectivity of Large Language Models Versus Specialists' Knowledge on COVID-19's Impacts in Pregnancy: Cross-Sectional Pilot Study.JMIR Form Res. 2025 Feb 5;9:e56126. doi: 10.2196/56126. JMIR Form Res. 2025. PMID: 39794312 Free PMC article.
-
Assessing the Readability of Patient Education Materials on Cardiac Catheterization From Artificial Intelligence Chatbots: An Observational Cross-Sectional Study.Cureus. 2024 Jul 4;16(7):e63865. doi: 10.7759/cureus.63865. eCollection 2024 Jul. Cureus. 2024. PMID: 39099896 Free PMC article.
-
Assessing the Application of Large Language Models in Generating Dermatologic Patient Education Materials According to Reading Level: Qualitative Study.JMIR Dermatol. 2024 May 16;7:e55898. doi: 10.2196/55898. JMIR Dermatol. 2024. PMID: 38754096 Free PMC article.
-
Appropriateness and readability of Google Bard and ChatGPT-3.5 generated responses for surgical treatment of glaucoma.Rom J Ophthalmol. 2024 Jul-Sep;68(3):243-248. doi: 10.22336/rjo.2024.45. Rom J Ophthalmol. 2024. PMID: 39464759 Free PMC article.
-
Large language models: a new frontier in paediatric cataract patient education.Br J Ophthalmol. 2024 Sep 20;108(10):1470-1476. doi: 10.1136/bjo-2024-325252. Br J Ophthalmol. 2024. PMID: 39174290
Cited by
-
Comparative performance analysis of large language models: ChatGPT-3.5, ChatGPT-4 and Google Gemini in glucocorticoid-induced osteoporosis.J Orthop Surg Res. 2024 Sep 18;19(1):574. doi: 10.1186/s13018-024-04996-2. J Orthop Surg Res. 2024. PMID: 39289734 Free PMC article.
-
ChatGPT 4.0's efficacy in the self-diagnosis of non-traumatic hand conditions.J Hand Microsurg. 2025 Jan 23;17(3):100217. doi: 10.1016/j.jham.2025.100217. eCollection 2025 May. J Hand Microsurg. 2025. PMID: 40007763
-
From Data to Decisions: Leveraging Retrieval-Augmented Generation to Balance Citation Bias in Burn Management Literature.Eur Burn J. 2025 Jun 2;6(2):28. doi: 10.3390/ebj6020028. Eur Burn J. 2025. PMID: 40558623 Free PMC article.
-
Development, optimization, and preliminary evaluation of a novel artificial intelligence tool to promote patient health literacy in radiology reports: The Rads-Lit tool.PLoS One. 2025 Sep 3;20(9):e0331368. doi: 10.1371/journal.pone.0331368. eCollection 2025. PLoS One. 2025. PMID: 40901830 Free PMC article.
-
Unlocking Health Literacy: The Ultimate Guide to Hypertension Education From ChatGPT Versus Google Gemini.Cureus. 2024 May 8;16(5):e59898. doi: 10.7759/cureus.59898. eCollection 2024 May. Cureus. 2024. PMID: 38721479 Free PMC article.
References
MeSH terms
LinkOut - more resources
Full Text Sources
Medical