

An open source knowledge graph ecosystem for the life sciences
- PMID: 38605048
- PMCID: PMC11009265
- DOI: 10.1038/s41597-024-03171-w
An open source knowledge graph ecosystem for the life sciences
Abstract
Translational research requires data at multiple scales of biological organization. Advancements in sequencing and multi-omics technologies have increased the availability of these data, but researchers face significant integration challenges. Knowledge graphs (KGs) are used to model complex phenomena, and methods exist to construct them automatically. However, tackling complex biomedical integration problems requires flexibility in the way knowledge is modeled. Moreover, existing KG construction methods provide robust tooling at the cost of fixed or limited choices among knowledge representation models. PheKnowLator (Phenotype Knowledge Translator) is a semantic ecosystem for automating the FAIR (Findable, Accessible, Interoperable, and Reusable) construction of ontologically grounded KGs with fully customizable knowledge representation. The ecosystem includes KG construction resources (e.g., data preparation APIs), analysis tools (e.g., SPARQL endpoint resources and abstraction algorithms), and benchmarks (e.g., prebuilt KGs). We evaluated the ecosystem by systematically comparing it to existing open-source KG construction methods and by analyzing its computational performance when used to construct 12 different large-scale KGs. With flexible knowledge representation, PheKnowLator enables fully customizable KGs without compromising performance or usability.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
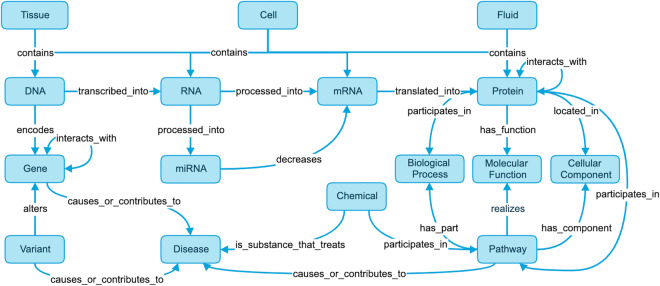
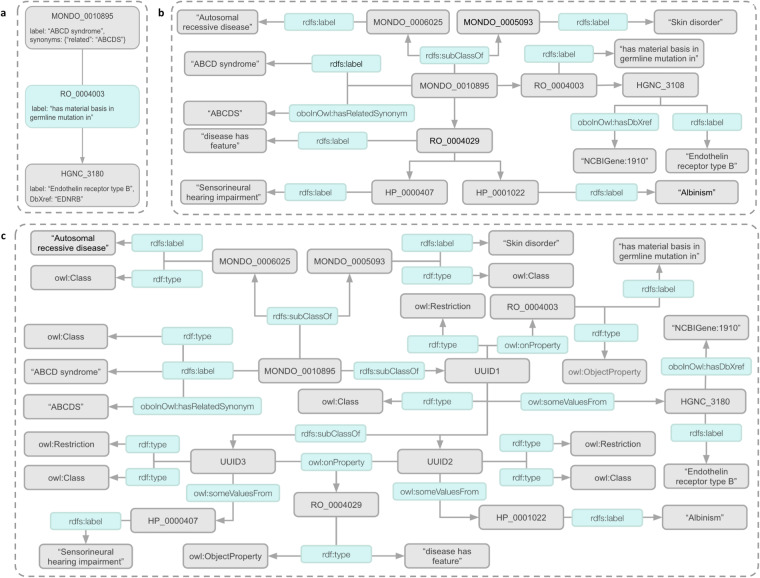






References
-
- Gupta, N. & Verma, V. K. Next-Generation Sequencing and Its Application: Empowering in Public Health Beyond Reality. in Microbial Technology for the Welfare of Society (ed. Arora, P. K.) 313–341 (Springer Singapore, Singapore, 2019).
Publication types
MeSH terms
Grants and funding
- OT2 OD026675/OD/NIH HHS/United States
- R00 LM013367/LM/NLM NIH HHS/United States
- T15 LM007079/LM/NLM NIH HHS/United States
- T15 LM009451/LM/NLM NIH HHS/United States
- K99 LM013367/LM/NLM NIH HHS/United States
- U54 AT008909/AT/NCCIH NIH HHS/United States
- R01 LM008111/LM/NLM NIH HHS/United States
- R01 LM013400/LM/NLM NIH HHS/United States
- U24 CA268108/CA/NCI NIH HHS/United States
- L70 LM014128/LM/NLM NIH HHS/United States
- R01 LM006910/LM/NLM NIH HHS/United States
- OT2 OD033759/OD/NIH HHS/United States
- U24 HG011449/HG/NHGRI NIH HHS/United States
- OT2 OD030545/OD/NIH HHS/United States
