

Comparing the Performance of Popular Large Language Models on the National Board of Medical Examiners Sample Questions
- PMID: 38606229
- PMCID: PMC11007479
- DOI: 10.7759/cureus.55991
Comparing the Performance of Popular Large Language Models on the National Board of Medical Examiners Sample Questions
Abstract
Introduction: Large language models (LLMs) have transformed various domains in medicine, aiding in complex tasks and clinical decision-making, with OpenAI's GPT-4, GPT-3.5, Google's Bard, and Anthropic's Claude among the most widely used. While GPT-4 has demonstrated superior performance in some studies, comprehensive comparisons among these models remain limited. Recognizing the significance of the National Board of Medical Examiners (NBME) exams in assessing the clinical knowledge of medical students, this study aims to compare the accuracy of popular LLMs on NBME clinical subject exam sample questions.
Methods: The questions used in this study were multiple-choice questions obtained from the official NBME website and are publicly available. Questions from the NBME subject exams in medicine, pediatrics, obstetrics and gynecology, clinical neurology, ambulatory care, family medicine, psychiatry, and surgery were used to query each LLM. The responses from GPT-4, GPT-3.5, Claude, and Bard were collected in October 2023. The response by each LLM was compared to the answer provided by the NBME and checked for accuracy. Statistical analysis was performed using one-way analysis of variance (ANOVA).
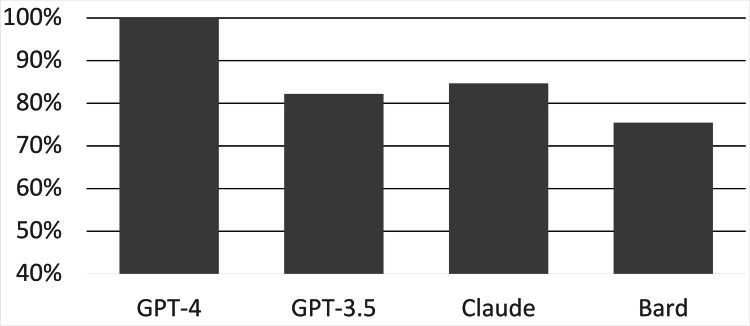
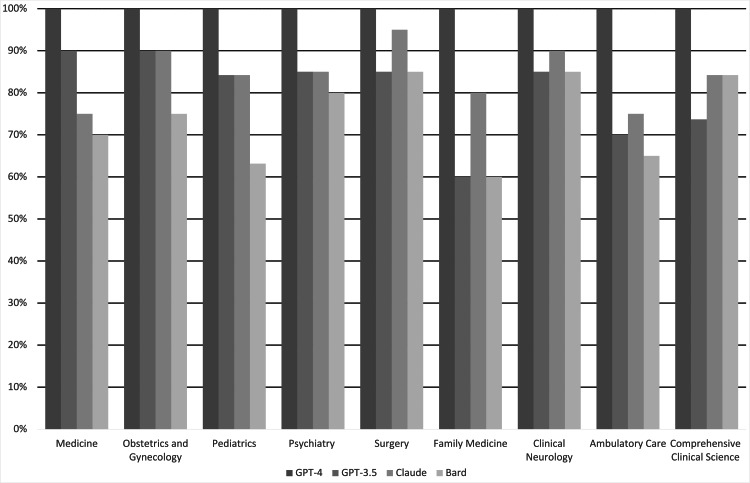
Results: A total of 163 questions were queried by each LLM. GPT-4 scored 163/163 (100%), GPT-3.5 scored 134/163 (82.2%), Bard scored 123/163 (75.5%), and Claude scored 138/163 (84.7%). The total performance of GPT-4 was statistically superior to that of GPT-3.5, Claude, and Bard by 17.8%, 15.3%, and 24.5%, respectively. The total performance of GPT-3.5, Claude, and Bard was not significantly different. GPT-4 significantly outperformed Bard in specific subjects, including medicine, pediatrics, family medicine, and ambulatory care, and GPT-3.5 in ambulatory care and family medicine. Across all LLMs, the surgery exam had the highest average score (18.25/20), while the family medicine exam had the lowest average score (3.75/5). Conclusion: GPT-4's superior performance on NBME clinical subject exam sample questions underscores its potential in medical education and practice. While LLMs exhibit promise, discernment in their application is crucial, considering occasional inaccuracies. As technological advancements continue, regular reassessments and refinements are imperative to maintain their reliability and relevance in medicine.
Keywords: artificial intelligence (ai); artificial intelligence and education; artificial intelligence in medicine; chatgpt; claude; google's bard; gpt-4; large language model; nbme subject exam; united states medical licensing examination (usmle).
Copyright © 2024, Abbas et al.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
Similar articles
-
Artificial Intelligence for Anesthesiology Board-Style Examination Questions: Role of Large Language Models.J Cardiothorac Vasc Anesth. 2024 May;38(5):1251-1259. doi: 10.1053/j.jvca.2024.01.032. Epub 2024 Feb 1. J Cardiothorac Vasc Anesth. 2024. PMID: 38423884 Review.
-
Evaluating Large Language Models for the National Premedical Exam in India: Comparative Analysis of GPT-3.5, GPT-4, and Bard.JMIR Med Educ. 2024 Feb 21;10:e51523. doi: 10.2196/51523. JMIR Med Educ. 2024. PMID: 38381486 Free PMC article.
-
Evidence-based potential of generative artificial intelligence large language models in orthodontics: a comparative study of ChatGPT, Google Bard, and Microsoft Bing.Eur J Orthod. 2024 Apr 13:cjae017. doi: 10.1093/ejo/cjae017. Online ahead of print. Eur J Orthod. 2024. PMID: 38613510
-
Comparitive performance of artificial intelligence-based large language models on the orthopedic in-training examination.J Orthop Surg (Hong Kong). 2025 Jan-Apr;33(1):10225536241268789. doi: 10.1177/10225536241268789. J Orthop Surg (Hong Kong). 2025. PMID: 40028745
-
Large language models are changing landscape of academic publications. A positive transformation?Cas Lek Cesk. 2024;162(7-8):294-297. Cas Lek Cesk. 2024. PMID: 38981715 Review. English.
Cited by
-
Evaluating accuracy and reproducibility of large language model performance on critical care assessments in pharmacy education.Front Artif Intell. 2025 Jan 9;7:1514896. doi: 10.3389/frai.2024.1514896. eCollection 2024. Front Artif Intell. 2025. PMID: 39850846 Free PMC article.
-
Large Language Models in Biochemistry Education: Comparative Evaluation of Performance.JMIR Med Educ. 2025 Apr 10;11:e67244. doi: 10.2196/67244. JMIR Med Educ. 2025. PMID: 40209205 Free PMC article.
-
Enhancing responses from large language models with role-playing prompts: a comparative study on answering frequently asked questions about total knee arthroplasty.BMC Med Inform Decis Mak. 2025 May 23;25(1):196. doi: 10.1186/s12911-025-03024-5. BMC Med Inform Decis Mak. 2025. PMID: 40410756 Free PMC article.
-
Evaluating large language model workflows in clinical decision support for triage and referral and diagnosis.NPJ Digit Med. 2025 May 9;8(1):263. doi: 10.1038/s41746-025-01684-1. NPJ Digit Med. 2025. PMID: 40346344 Free PMC article.
-
Can ChatGPT-4o Really Pass Medical Science Exams? A Pragmatic Analysis Using Novel Questions.Med Sci Educ. 2025 Feb 4;35(2):721-729. doi: 10.1007/s40670-025-02293-z. eCollection 2025 Apr. Med Sci Educ. 2025. PMID: 40352979 Free PMC article.
References
-
- Artificial intelligence: the future for diabetes care. Ellahham S. Am J Med. 2020;133:895–900. - PubMed
-
- A comprehensive overview of large language models. Naveed H, Khan AU, Qiu S, et al. arXiv. 2023
LinkOut - more resources
Full Text Sources
Research Materials