

Refining the impact of genetic evidence on clinical success
- PMID: 38632401
- PMCID: PMC11096124
- DOI: 10.1038/s41586-024-07316-0
Refining the impact of genetic evidence on clinical success
Abstract
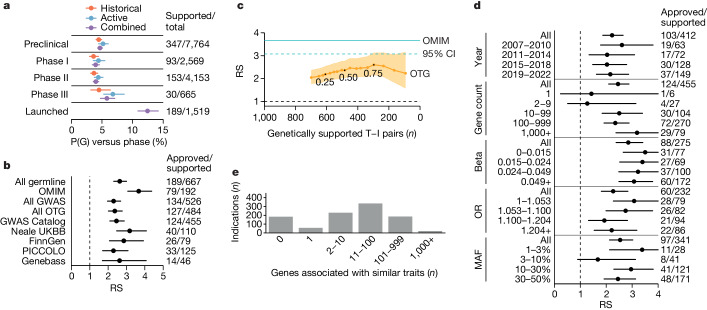
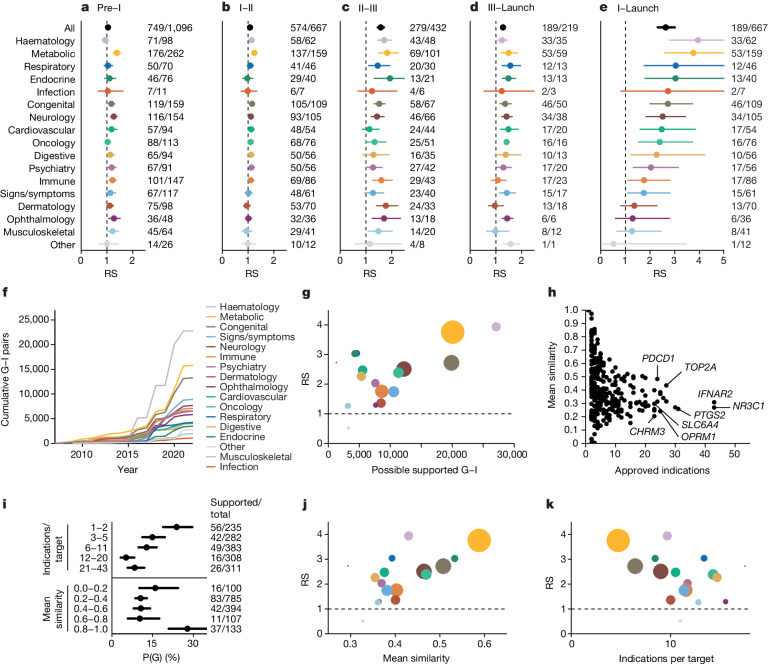
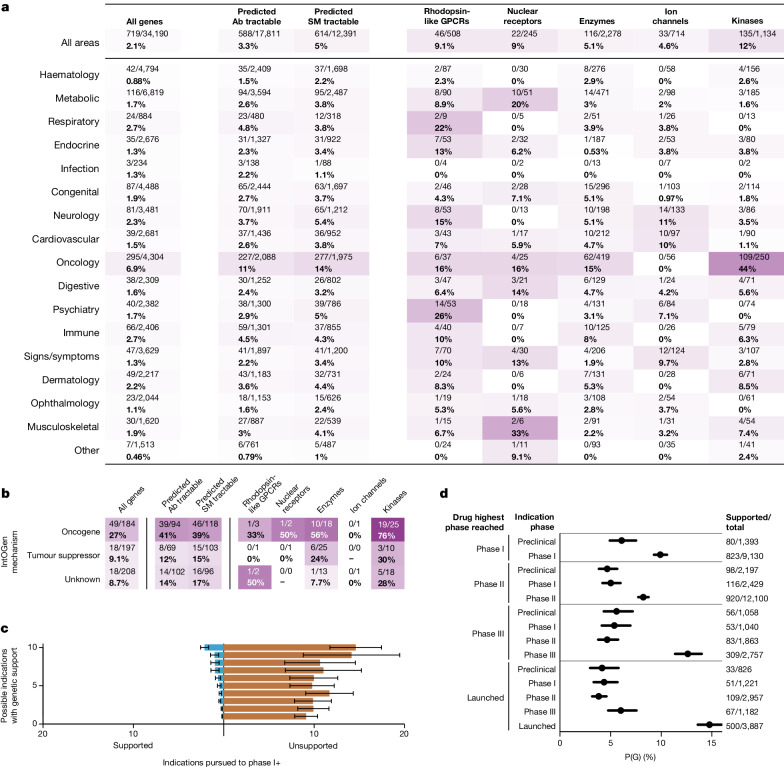
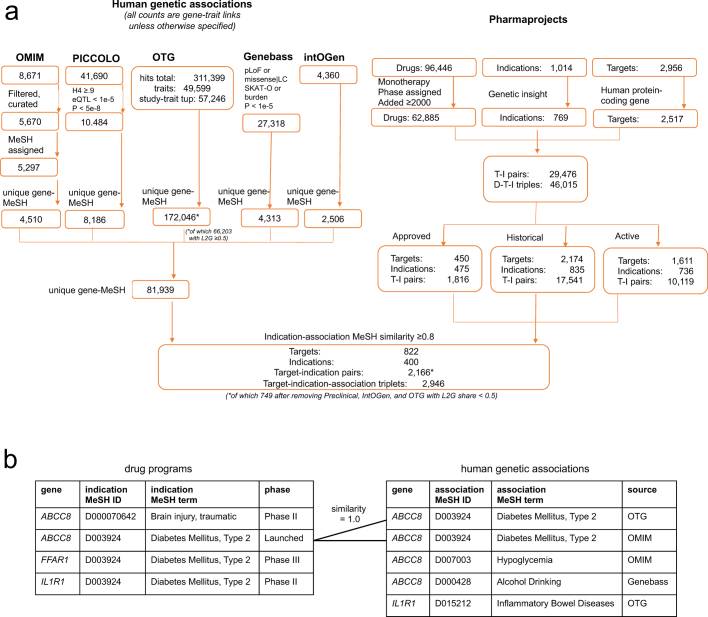
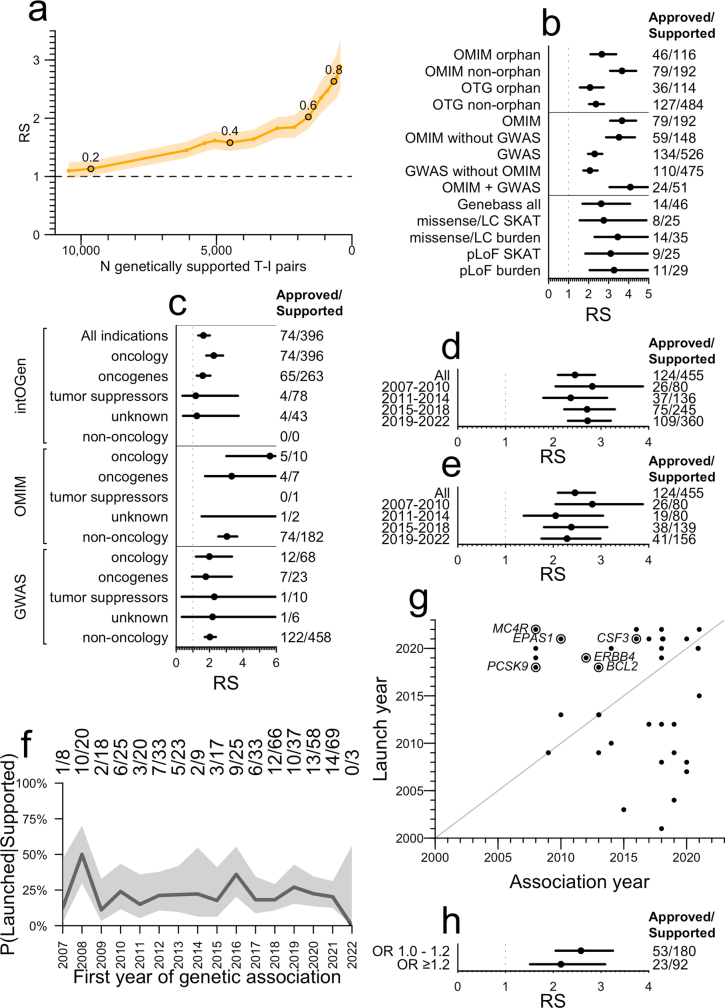
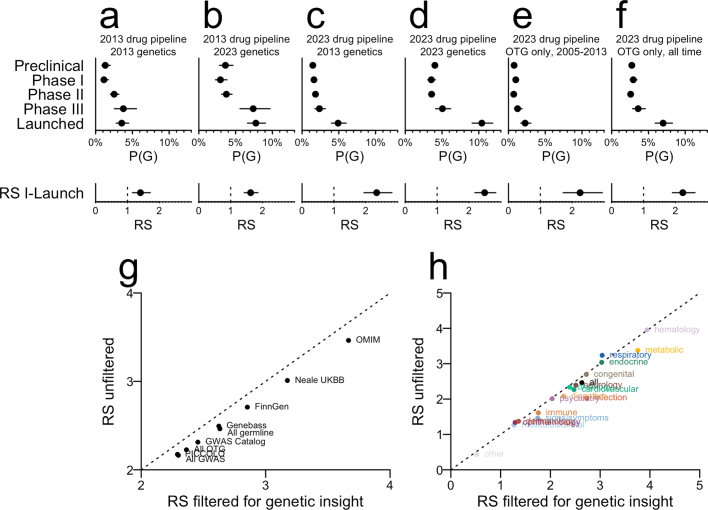
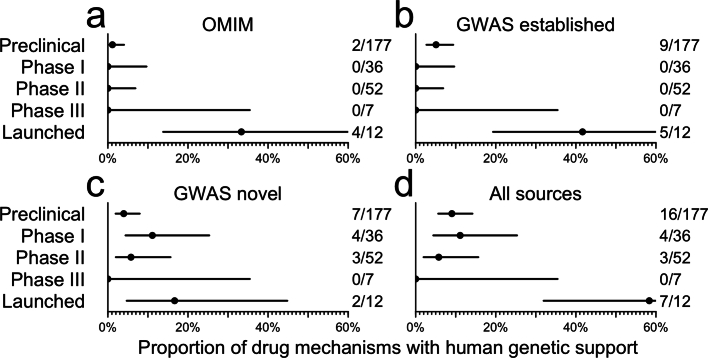
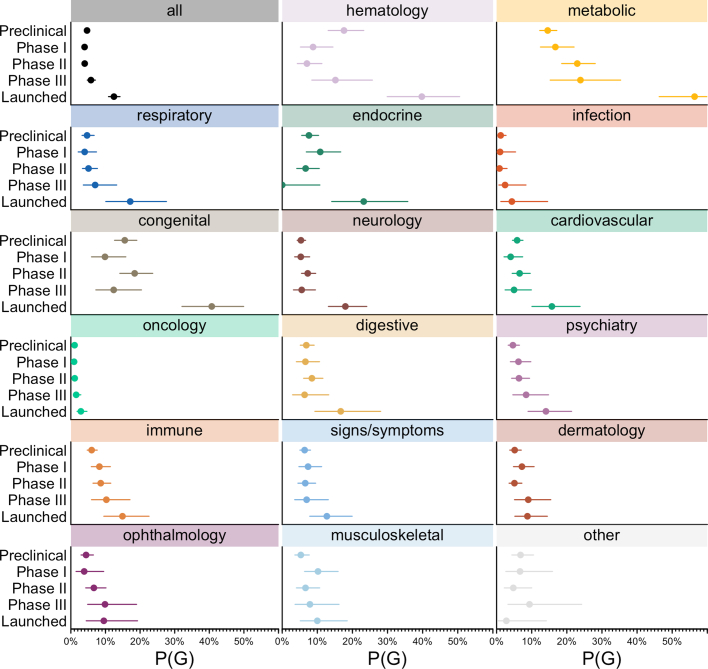
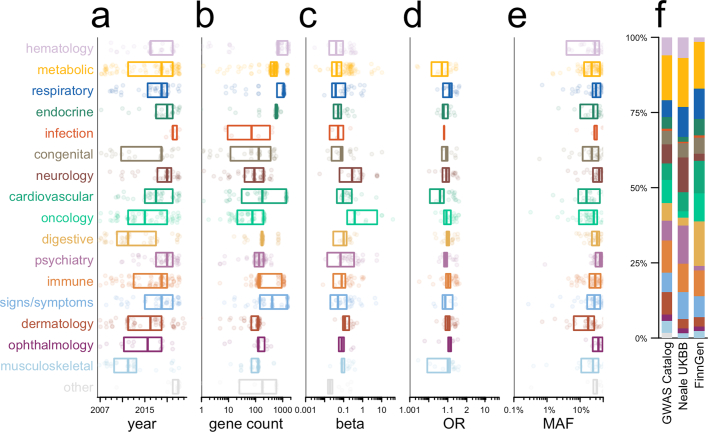
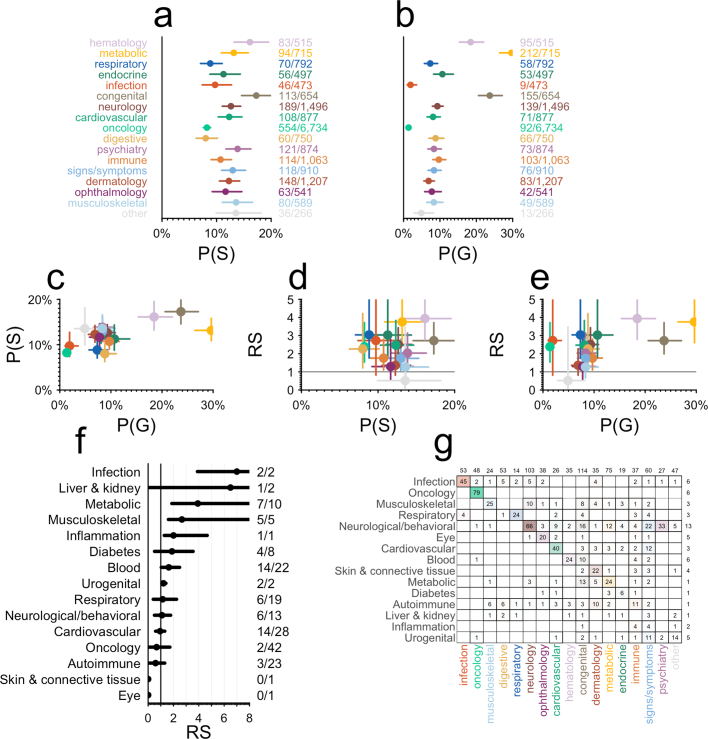
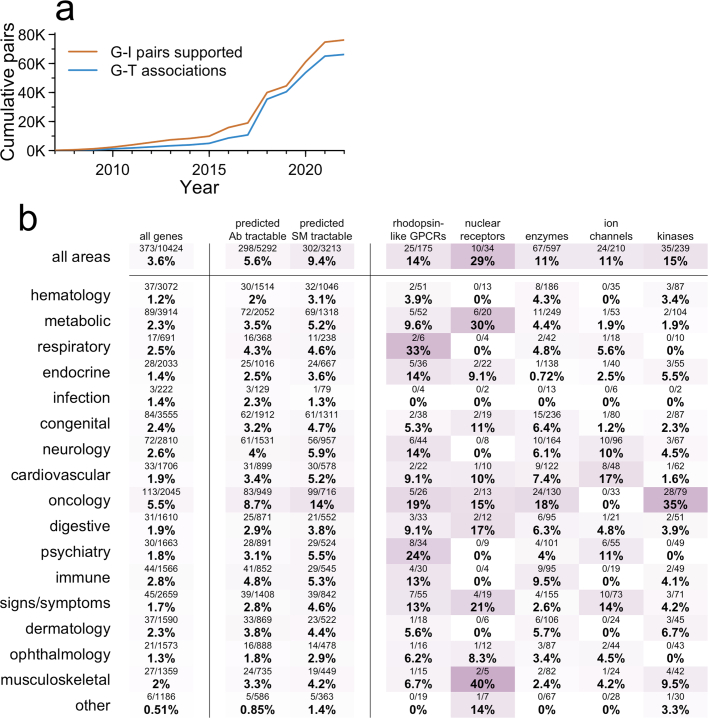
The cost of drug discovery and development is driven primarily by failure1, with only about 10% of clinical programmes eventually receiving approval2-4. We previously estimated that human genetic evidence doubles the success rate from clinical development to approval5. In this study we leverage the growth in genetic evidence over the past decade to better understand the characteristics that distinguish clinical success and failure. We estimate the probability of success for drug mechanisms with genetic support is 2.6 times greater than those without. This relative success varies among therapy areas and development phases, and improves with increasing confidence in the causal gene, but is largely unaffected by genetic effect size, minor allele frequency or year of discovery. These results indicate we are far from reaching peak genetic insights to aid the discovery of targets for more effective drugs.
© 2024. The Author(s).
Conflict of interest statement
M.R.N. is an employee of Deerfield and Genscience. C.C.D. is an employee of Deerfield. E.V.M. and J.L.P. are consultants to Deerfield. Unrelated to the current work, E.V.M. acknowledges speaking fees from Eli Lilly, consulting fees from Alnylam and research support from Ionis, Gate, Sangamo and Eli Lilly.
Figures
References
-
- Thomas D. et al. Clinical Development Success Rates and Contributing Factors 2011–2020 (Biotechnology Innovation Organization, 2021); https://go.bio.org/rs/490-EHZ-999/images/ClinicalDevelopmentSuccessRates...
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous
