

Surprisal From Language Models Can Predict ERPs in Processing Predicate-Argument Structures Only if Enriched by an Agent Preference Principle
- PMID: 38645615
- PMCID: PMC11025647
- DOI: 10.1162/nol_a_00121
Surprisal From Language Models Can Predict ERPs in Processing Predicate-Argument Structures Only if Enriched by an Agent Preference Principle
Abstract
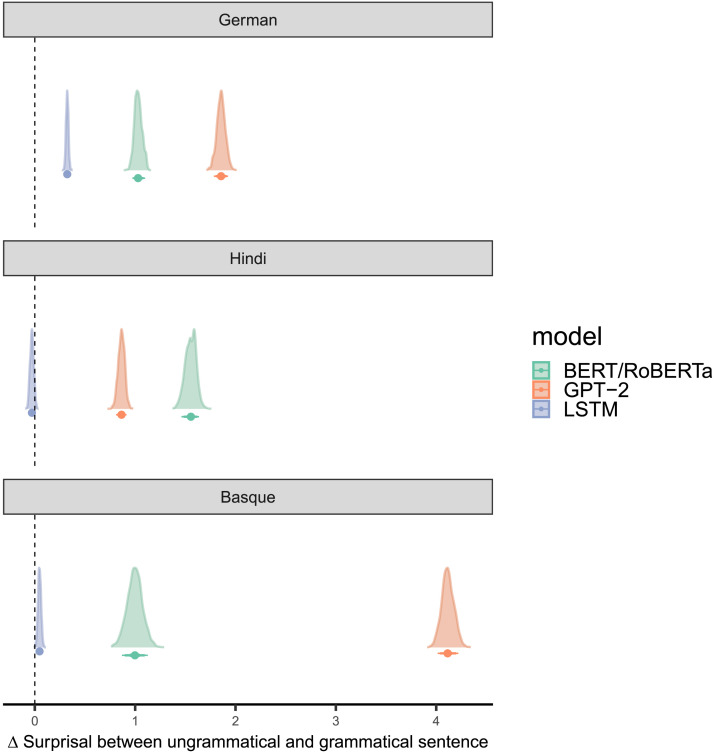
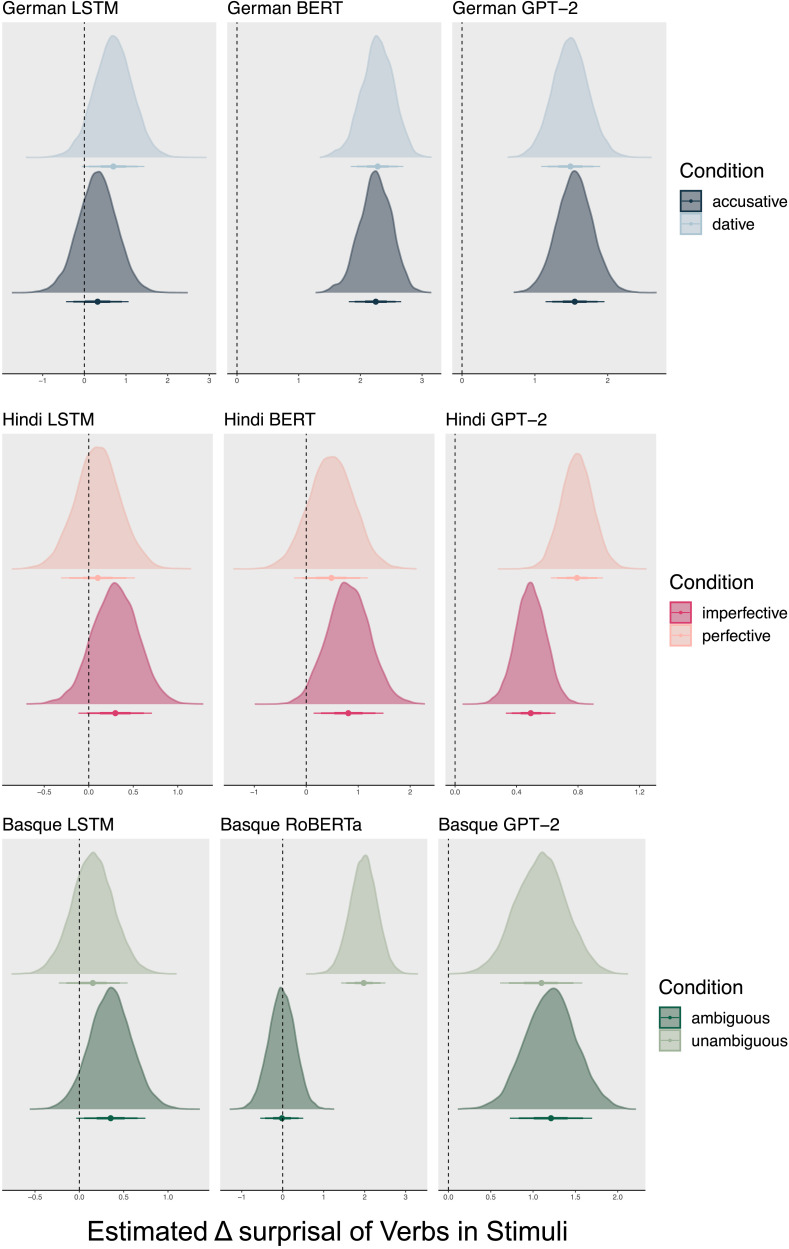
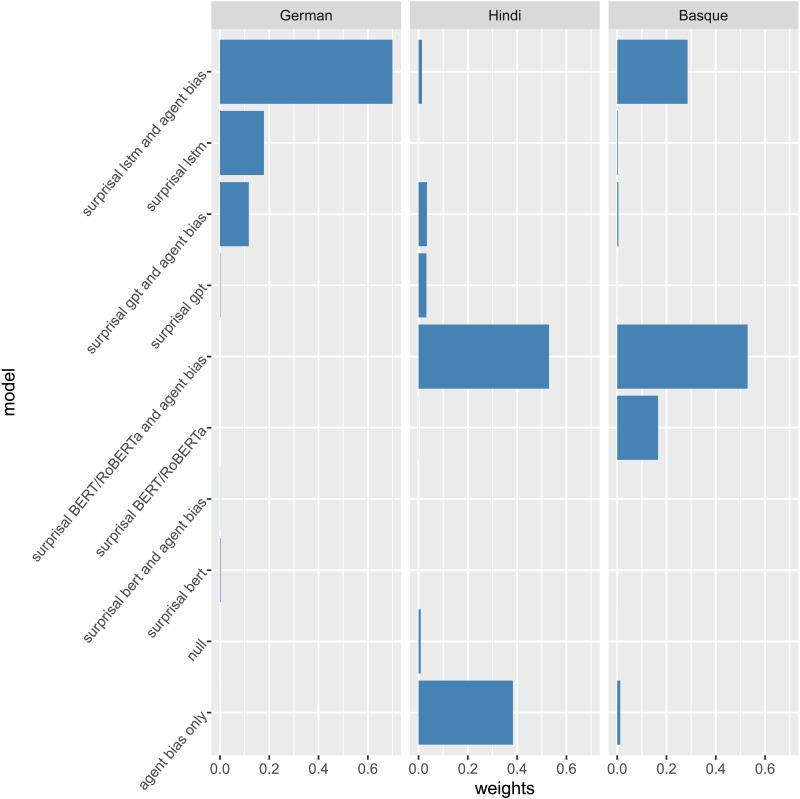
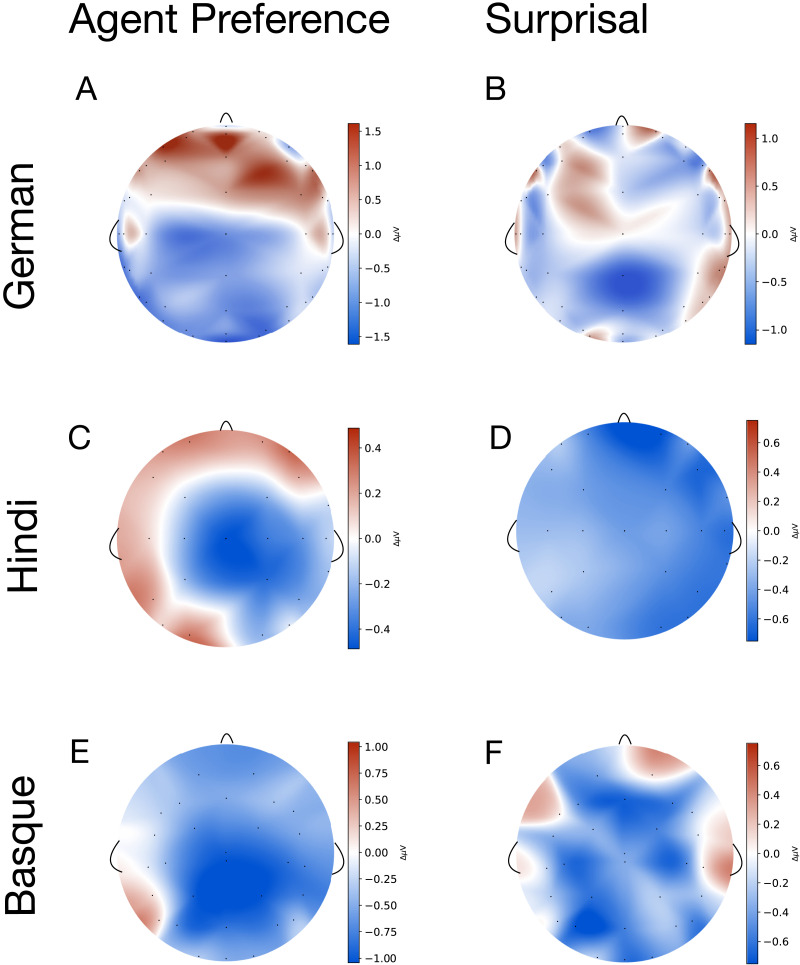
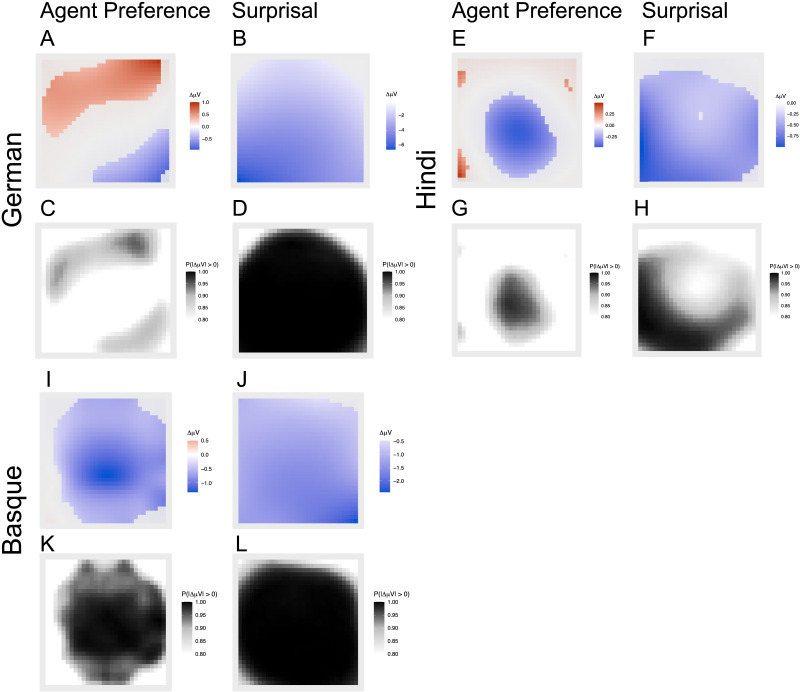
Language models based on artificial neural networks increasingly capture key aspects of how humans process sentences. Most notably, model-based surprisals predict event-related potentials such as N400 amplitudes during parsing. Assuming that these models represent realistic estimates of human linguistic experience, their success in modeling language processing raises the possibility that the human processing system relies on no other principles than the general architecture of language models and on sufficient linguistic input. Here, we test this hypothesis on N400 effects observed during the processing of verb-final sentences in German, Basque, and Hindi. By stacking Bayesian generalised additive models, we show that, in each language, N400 amplitudes and topographies in the region of the verb are best predicted when model-based surprisals are complemented by an Agent Preference principle that transiently interprets initial role-ambiguous noun phrases as agents, leading to reanalysis when this interpretation fails. Our findings demonstrate the need for this principle independently of usage frequencies and structural differences between languages. The principle has an unequal force, however. Compared to surprisal, its effect is weakest in German, stronger in Hindi, and still stronger in Basque. This gradient is correlated with the extent to which grammars allow unmarked NPs to be patients, a structural feature that boosts reanalysis effects. We conclude that language models gain more neurobiological plausibility by incorporating an Agent Preference. Conversely, theories of human processing profit from incorporating surprisal estimates in addition to principles like the Agent Preference, which arguably have distinct evolutionary roots.
Keywords: ERP; artificial neural networks; computational modeling; event cognition; large language models (LLMs); sentence processing; surprisal.
© 2023 Massachusetts Institute of Technology.
Conflict of interest statement
Competing Interests: The authors have declared that no competing interests exist.
Figures
References
-
- Agerri, R., San Vicente, I., Campos, J. A., Barrena, A., Saralegi, X., Soroa, A., & Agirre, E. (2020). Give your text representation models some love: The case for Basque. In Proceedings of the twelfth language resources and evaluation conference (pp. 4781–4788). European Language Resources Association.
-
- Arehalli, S., Dillon, B., & Linzen, T. (2022). Syntactic surprisal from neural models predicts, but underestimates, human processing difficulty from syntactic ambiguities. In Proceedings of the 26th conference on computational natural language learning (CoNLL). Association for Computational Linguistics. 10.18653/v1/2022.conll-1.20 - DOI
-
- Arehalli, S., & Linzen, T. (2020). Neural language models capture some, but not all, agreement attraction effects. PsyArXiv. 10.31234/osf.io/97qcg - DOI
-
- Aurnhammer, C., & Frank, S. L. (2019). Comparing gated and simple recurrent neural network architectures as models of human sentence processing. PsyArXiv. 10.31234/osf.io/wec74 - DOI
LinkOut - more resources
Full Text Sources