

Using ChatGPT-4 to Create Structured Medical Notes From Audio Recordings of Physician-Patient Encounters: Comparative Study
- PMID: 38648636
- PMCID: PMC11074889
- DOI: 10.2196/54419
Using ChatGPT-4 to Create Structured Medical Notes From Audio Recordings of Physician-Patient Encounters: Comparative Study
Abstract
Background: Medical documentation plays a crucial role in clinical practice, facilitating accurate patient management and communication among health care professionals. However, inaccuracies in medical notes can lead to miscommunication and diagnostic errors. Additionally, the demands of documentation contribute to physician burnout. Although intermediaries like medical scribes and speech recognition software have been used to ease this burden, they have limitations in terms of accuracy and addressing provider-specific metrics. The integration of ambient artificial intelligence (AI)-powered solutions offers a promising way to improve documentation while fitting seamlessly into existing workflows.
Objective: This study aims to assess the accuracy and quality of Subjective, Objective, Assessment, and Plan (SOAP) notes generated by ChatGPT-4, an AI model, using established transcripts of History and Physical Examination as the gold standard. We seek to identify potential errors and evaluate the model's performance across different categories.
Methods: We conducted simulated patient-provider encounters representing various ambulatory specialties and transcribed the audio files. Key reportable elements were identified, and ChatGPT-4 was used to generate SOAP notes based on these transcripts. Three versions of each note were created and compared to the gold standard via chart review; errors generated from the comparison were categorized as omissions, incorrect information, or additions. We compared the accuracy of data elements across versions, transcript length, and data categories. Additionally, we assessed note quality using the Physician Documentation Quality Instrument (PDQI) scoring system.
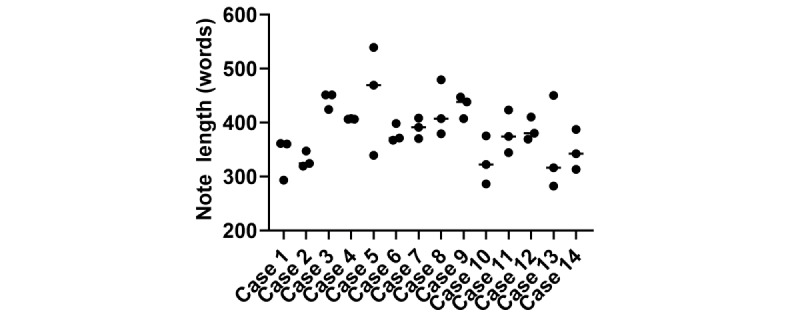
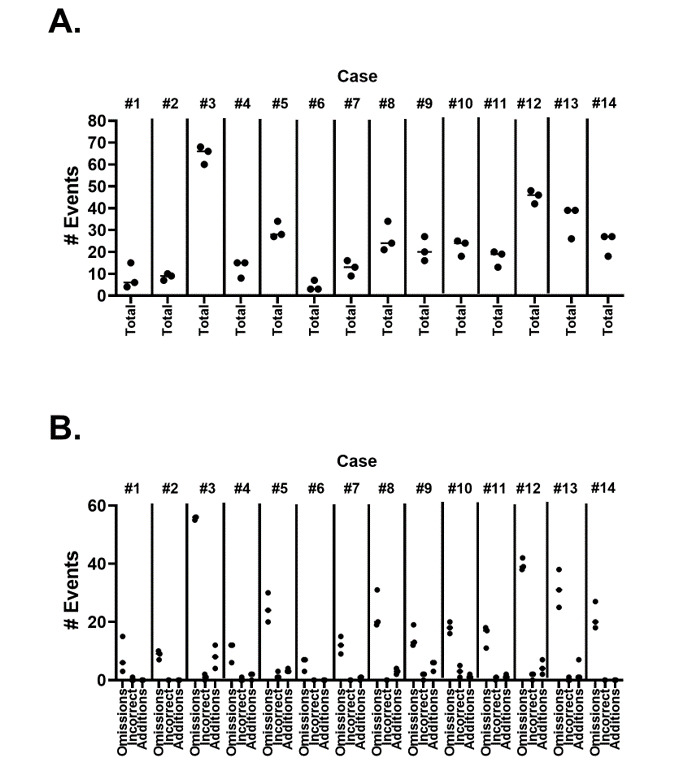
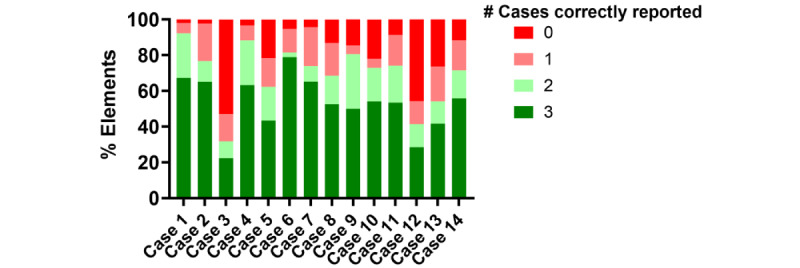
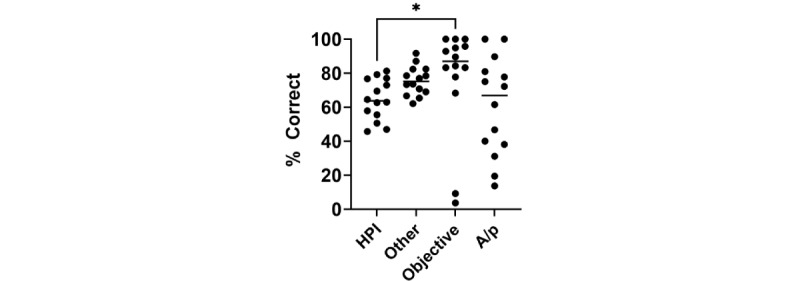
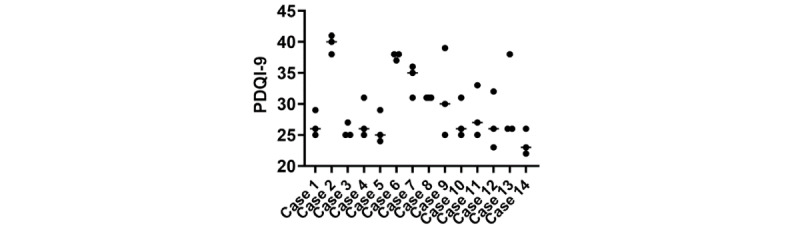
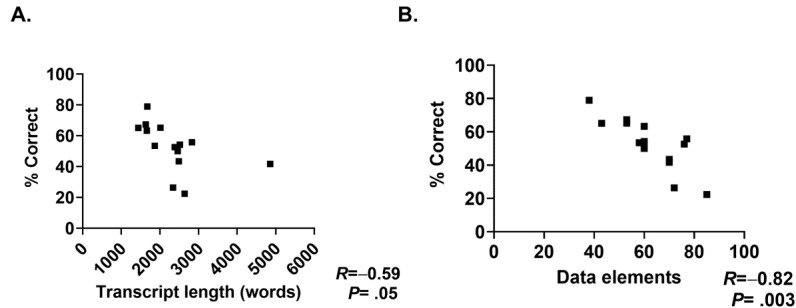
Results: Although ChatGPT-4 consistently generated SOAP-style notes, there were, on average, 23.6 errors per clinical case, with errors of omission (86%) being the most common, followed by addition errors (10.5%) and inclusion of incorrect facts (3.2%). There was significant variance between replicates of the same case, with only 52.9% of data elements reported correctly across all 3 replicates. The accuracy of data elements varied across cases, with the highest accuracy observed in the "Objective" section. Consequently, the measure of note quality, assessed by PDQI, demonstrated intra- and intercase variance. Finally, the accuracy of ChatGPT-4 was inversely correlated to both the transcript length (P=.05) and the number of scorable data elements (P=.05).
Conclusions: Our study reveals substantial variability in errors, accuracy, and note quality generated by ChatGPT-4. Errors were not limited to specific sections, and the inconsistency in error types across replicates complicated predictability. Transcript length and data complexity were inversely correlated with note accuracy, raising concerns about the model's effectiveness in handling complex medical cases. The quality and reliability of clinical notes produced by ChatGPT-4 do not meet the standards required for clinical use. Although AI holds promise in health care, caution should be exercised before widespread adoption. Further research is needed to address accuracy, variability, and potential errors. ChatGPT-4, while valuable in various applications, should not be considered a safe alternative to human-generated clinical documentation at this time.
Keywords: AI; ChatGPT; ChatGPT-4; accuracy; artificial intelligence; clinical documentation; documentation; documentations; generation; generative AI; generative artificial intelligence; large language model; medical documentation; medical note; medical notes; publicly available; quality; reproducibility; simulation; transcript; transcripts.
©Annessa Kernberg, Jeffrey A Gold, Vishnu Mohan. Originally published in the Journal of Medical Internet Research (https://www.jmir.org), 22.04.2024.
Conflict of interest statement
Conflicts of Interest: None declared.
Figures
References
-
- Bell SK, Delbanco T, Elmore JG, Fitzgerald PS, Fossa A, Harcourt K, Leveille SG, Payne TH, Stametz RA, Walker J, DesRoches CM. Frequency and types of patient-reported errors in electronic health record ambulatory care notes. JAMA Netw Open. 2020 Jun 01;3(6):e205867. doi: 10.1001/jamanetworkopen.2020.5867. https://jamanetwork.com/journals/jamanetworkopen/fullarticle/10.1001/jam... 2766834 - DOI - PMC - PubMed
-
- Gaffney A, Woolhandler S, Cai C, Bor D, Himmelstein J, McCormick D, Himmelstein DU. Medical documentation burden among US office-based physicians in 2019: a national study. JAMA Intern Med. 2022 May 01;182(5):564–566. doi: 10.1001/jamainternmed.2022.0372. https://europepmc.org/abstract/MED/35344006 2790396 - DOI - PMC - PubMed
-
- Florig ST, Corby S, Rosson NT, Devara T, Weiskopf NG, Gold JA, Mohan V. Chart completion time of attending physicians while using medical scribes. AMIA Annu Symp Proc. 2021;2021:457–465. https://europepmc.org/abstract/MED/35308986 3577422 - PMC - PubMed
-
- Pranaat R, Mohan V, O'Reilly M, Hirsh M, McGrath K, Scholl G, Woodcock D, Gold JA. Use of simulation based on an electronic health records environment to evaluate the structure and accuracy of notes generated by medical scribes: proof-of-concept study. JMIR Med Inform. 2017 Sep 20;5(3):e30. doi: 10.2196/medinform.7883. https://medinform.jmir.org/2017/3/e30/ v5i3e30 - DOI - PMC - PubMed
-
- Corby S, Whittaker K, Ash JS, Mohan V, Becton J, Solberg N, Bergstrom R, Orwoll B, Hoekstra C, Gold JA. The future of medical scribes documenting in the electronic health record: results of an expert consensus conference. BMC Med Inform Decis Mak. 2021 Jun 29;21(1):204. doi: 10.1186/s12911-021-01560-4. https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-0... 10.1186/s12911-021-01560-4 - DOI - PMC - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
