

Optimization of hepatological clinical guidelines interpretation by large language models: a retrieval augmented generation-based framework
- PMID: 38654102
- PMCID: PMC11039454
- DOI: 10.1038/s41746-024-01091-y
Optimization of hepatological clinical guidelines interpretation by large language models: a retrieval augmented generation-based framework
Abstract
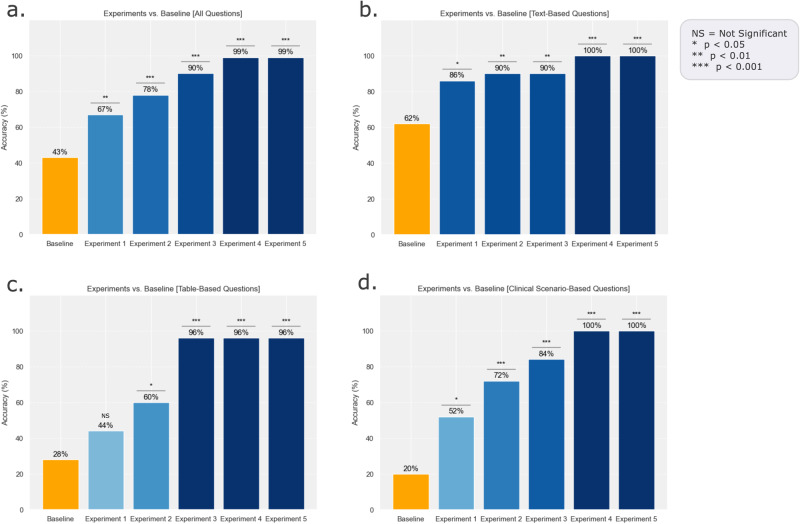
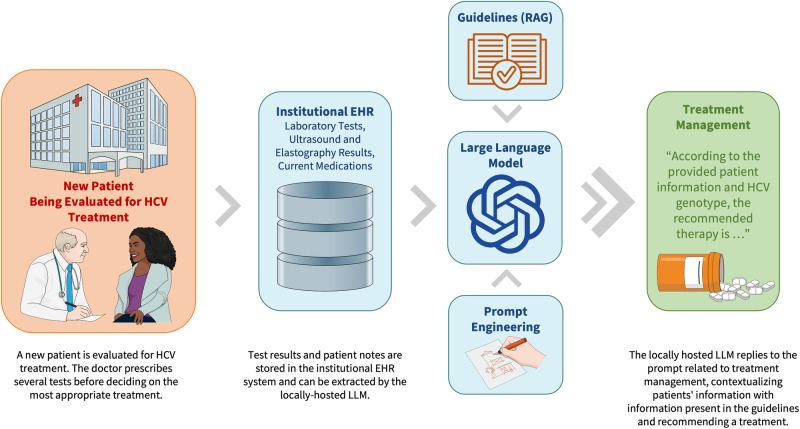
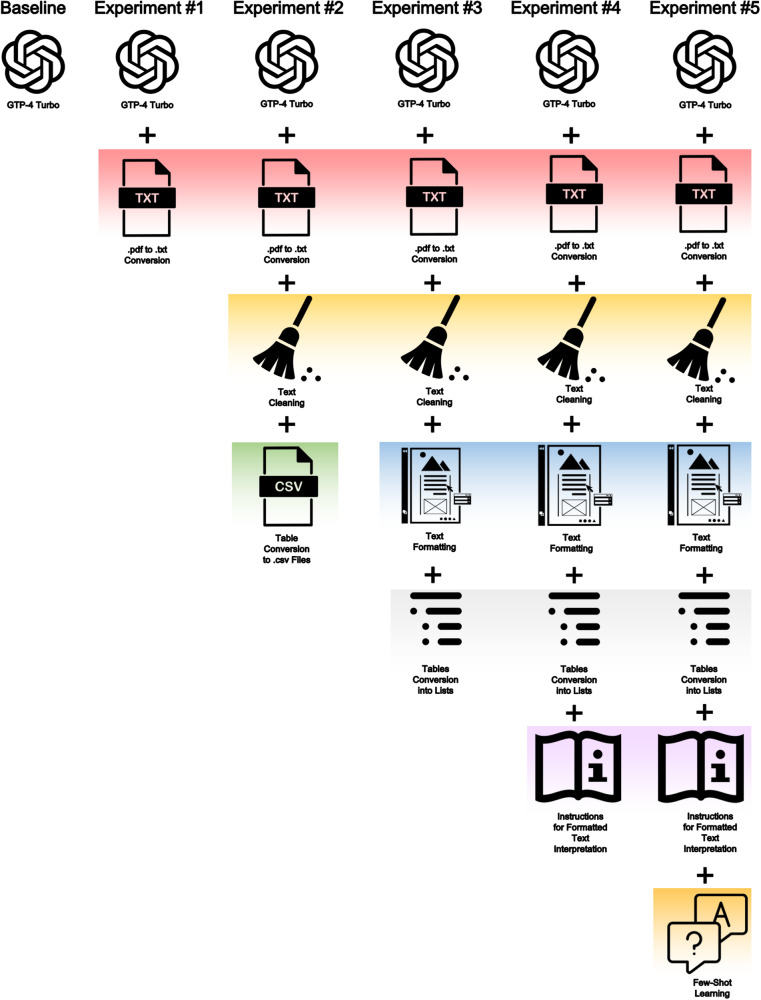
Large language models (LLMs) can potentially transform healthcare, particularly in providing the right information to the right provider at the right time in the hospital workflow. This study investigates the integration of LLMs into healthcare, specifically focusing on improving clinical decision support systems (CDSSs) through accurate interpretation of medical guidelines for chronic Hepatitis C Virus infection management. Utilizing OpenAI's GPT-4 Turbo model, we developed a customized LLM framework that incorporates retrieval augmented generation (RAG) and prompt engineering. Our framework involved guideline conversion into the best-structured format that can be efficiently processed by LLMs to provide the most accurate output. An ablation study was conducted to evaluate the impact of different formatting and learning strategies on the LLM's answer generation accuracy. The baseline GPT-4 Turbo model's performance was compared against five experimental setups with increasing levels of complexity: inclusion of in-context guidelines, guideline reformatting, and implementation of few-shot learning. Our primary outcome was the qualitative assessment of accuracy based on expert review, while secondary outcomes included the quantitative measurement of similarity of LLM-generated responses to expert-provided answers using text-similarity scores. The results showed a significant improvement in accuracy from 43 to 99% (p < 0.001), when guidelines were provided as context in a coherent corpus of text and non-text sources were converted into text. In addition, few-shot learning did not seem to improve overall accuracy. The study highlights that structured guideline reformatting and advanced prompt engineering (data quality vs. data quantity) can enhance the efficacy of LLM integrations to CDSSs for guideline delivery.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
References
Grants and funding
LinkOut - more resources
Full Text Sources
