

This is a preprint.
Efficient storage and regression computation for population-scale genome sequencing studies
- PMID: 38659813
- PMCID: PMC11042230
- DOI: 10.1101/2024.04.11.589062
Efficient storage and regression computation for population-scale genome sequencing studies
Update in
-
Efficient storage and regression computation for population-scale genome sequencing studies.Bioinformatics. 2025 Mar 4;41(3):btaf067. doi: 10.1093/bioinformatics/btaf067. Bioinformatics. 2025. PMID: 39932865 Free PMC article.
Abstract
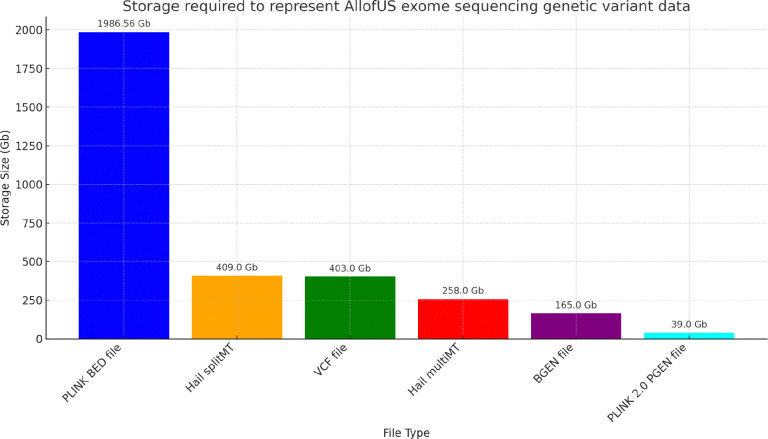
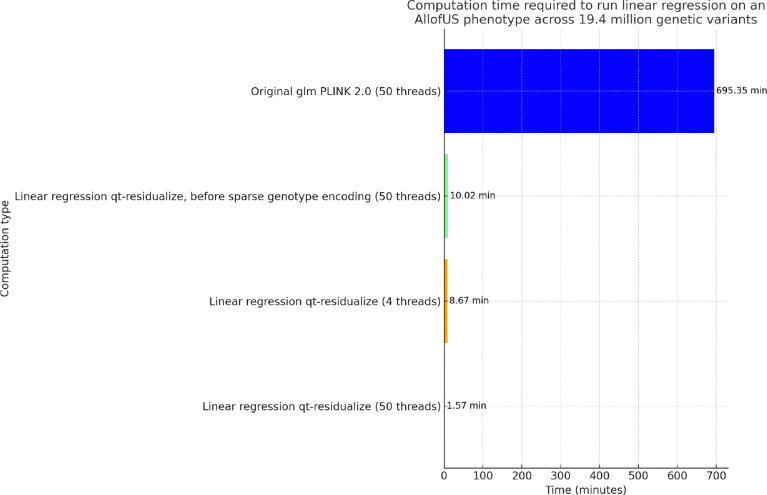
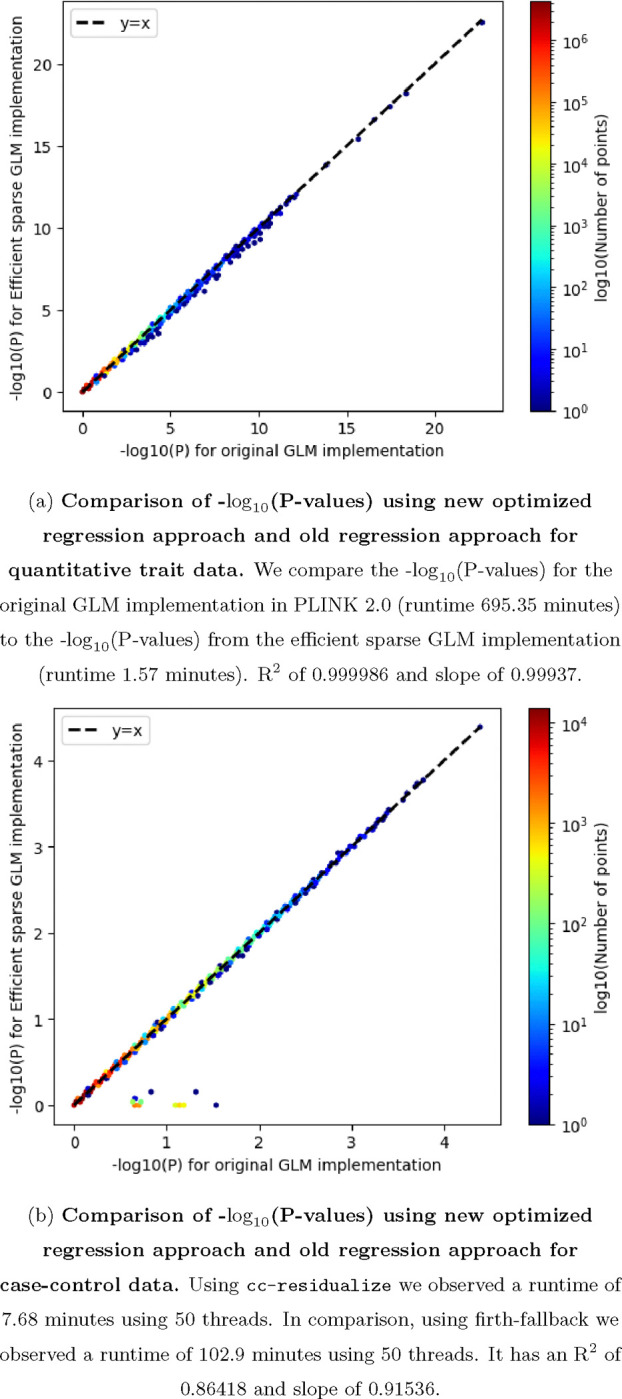
In the era of big data in human genetics, large-scale biobanks aggregating genetic data from diverse populations have emerged as important for advancing our understanding of human health and disease. However, the computational and storage demands of whole genome sequencing (WGS) studies pose significant challenges, especially for researchers from underfunded institutions or developing countries, creating a disparity in research capabilities. We introduce new approaches that significantly enhance computational efficiency and reduce data storage requirements for WGS studies. By developing algorithms for compressed storage of genetic data, focusing particularly on optimizing the representation of rare variants, and designing regression methods tailored for the scale and complexity of WGS data, we significantly lower computational and storage costs. We integrate our approach into PLINK 2.0. The implementation demonstrates considerable reductions in storage space and computational time without compromising analytical accuracy, as evidenced by the application to the AllofUs project data. We optimized the runtime of an exome-wide association analysis involving 19.4 million variants and the body mass index phenotype of 125,077 individuals, reducing it from 695.35 minutes (approximately 11.5 hours) on a single machine to just 1.57 minutes using 30 GB of memory and 50 threads (or 8.67 minutes with 4 threads). Additionally, we extended this approach to support multi-phenotype analyses. We anticipate that our approach will enable researchers across the globe to unlock the potential of population biobanks, accelerating the pace of discoveries that can improve our understanding of human health and disease.
Figures
Similar articles
-
Efficient storage and regression computation for population-scale genome sequencing studies.Bioinformatics. 2025 Mar 4;41(3):btaf067. doi: 10.1093/bioinformatics/btaf067. Bioinformatics. 2025. PMID: 39932865 Free PMC article.
-
Lessons from national biobank projects utilizing whole-genome sequencing for population-scale genomics.Genomics Inform. 2025 Mar 6;23(1):8. doi: 10.1186/s44342-025-00040-9. Genomics Inform. 2025. PMID: 40050991 Free PMC article. Review.
-
Distributed hybrid-indexing of compressed pan-genomes for scalable and fast sequence alignment.PLoS One. 2021 Aug 3;16(8):e0255260. doi: 10.1371/journal.pone.0255260. eCollection 2021. PLoS One. 2021. PMID: 34343181 Free PMC article.
-
Challenges in medical applications of whole exome/genome sequencing discoveries.Trends Cardiovasc Med. 2012 Nov;22(8):219-23. doi: 10.1016/j.tcm.2012.08.001. Epub 2012 Aug 24. Trends Cardiovasc Med. 2012. PMID: 22921985 Free PMC article. Review.
-
Organizational Aspects of the Implementation and Use of Whole Genome Sequencing and Whole Exome Sequencing in the Pediatric Population in Italy: Results of a Survey.J Pers Med. 2023 May 26;13(6):899. doi: 10.3390/jpm13060899. J Pers Med. 2023. PMID: 37373888 Free PMC article.
References
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources