

Physician Versus Large Language Model Chatbot Responses to Web-Based Questions From Autistic Patients in Chinese: Cross-Sectional Comparative Analysis
- PMID: 38687566
- PMCID: PMC11094593
- DOI: 10.2196/54706
Physician Versus Large Language Model Chatbot Responses to Web-Based Questions From Autistic Patients in Chinese: Cross-Sectional Comparative Analysis
Abstract
Background: There is a dearth of feasibility assessments regarding using large language models (LLMs) for responding to inquiries from autistic patients within a Chinese-language context. Despite Chinese being one of the most widely spoken languages globally, the predominant research focus on applying these models in the medical field has been on English-speaking populations.
Objective: This study aims to assess the effectiveness of LLM chatbots, specifically ChatGPT-4 (OpenAI) and ERNIE Bot (version 2.2.3; Baidu, Inc), one of the most advanced LLMs in China, in addressing inquiries from autistic individuals in a Chinese setting.
Methods: For this study, we gathered data from DXY-a widely acknowledged, web-based, medical consultation platform in China with a user base of over 100 million individuals. A total of 100 patient consultation samples were rigorously selected from January 2018 to August 2023, amounting to 239 questions extracted from publicly available autism-related documents on the platform. To maintain objectivity, both the original questions and responses were anonymized and randomized. An evaluation team of 3 chief physicians assessed the responses across 4 dimensions: relevance, accuracy, usefulness, and empathy. The team completed 717 evaluations. The team initially identified the best response and then used a Likert scale with 5 response categories to gauge the responses, each representing a distinct level of quality. Finally, we compared the responses collected from different sources.
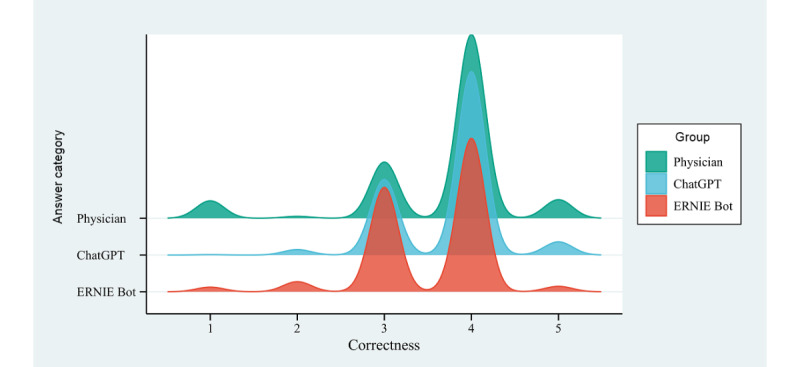
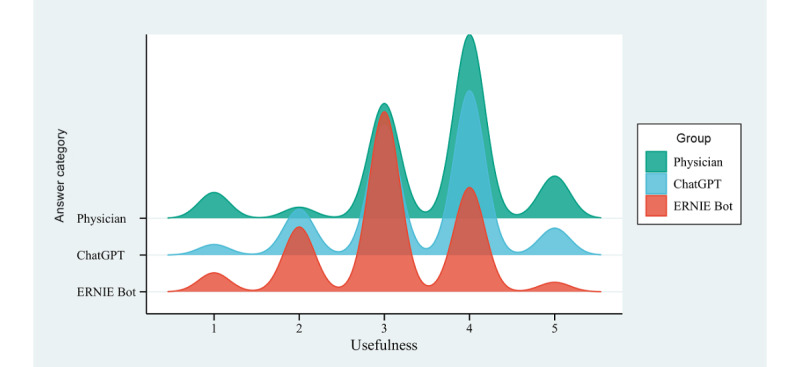
Results: Among the 717 evaluations conducted, 46.86% (95% CI 43.21%-50.51%) of assessors displayed varying preferences for responses from physicians, with 34.87% (95% CI 31.38%-38.36%) of assessors favoring ChatGPT and 18.27% (95% CI 15.44%-21.10%) of assessors favoring ERNIE Bot. The average relevance scores for physicians, ChatGPT, and ERNIE Bot were 3.75 (95% CI 3.69-3.82), 3.69 (95% CI 3.63-3.74), and 3.41 (95% CI 3.35-3.46), respectively. Physicians (3.66, 95% CI 3.60-3.73) and ChatGPT (3.73, 95% CI 3.69-3.77) demonstrated higher accuracy ratings compared to ERNIE Bot (3.52, 95% CI 3.47-3.57). In terms of usefulness scores, physicians (3.54, 95% CI 3.47-3.62) received higher ratings than ChatGPT (3.40, 95% CI 3.34-3.47) and ERNIE Bot (3.05, 95% CI 2.99-3.12). Finally, concerning the empathy dimension, ChatGPT (3.64, 95% CI 3.57-3.71) outperformed physicians (3.13, 95% CI 3.04-3.21) and ERNIE Bot (3.11, 95% CI 3.04-3.18).
Conclusions: In this cross-sectional study, physicians' responses exhibited superiority in the present Chinese-language context. Nonetheless, LLMs can provide valuable medical guidance to autistic patients and may even surpass physicians in demonstrating empathy. However, it is crucial to acknowledge that further optimization and research are imperative prerequisites before the effective integration of LLMs in clinical settings across diverse linguistic environments can be realized.
Trial registration: Chinese Clinical Trial Registry ChiCTR2300074655; https://www.chictr.org.cn/bin/project/edit?pid=199432.
Keywords: ChatGPT; ERNIE Bot; artificial intelligence; autism; chatbot.
©Wenjie He, Wenyan Zhang, Ya Jin, Qiang Zhou, Huadan Zhang, Qing Xia. Originally published in the Journal of Medical Internet Research (https://www.jmir.org), 30.04.2024.
Conflict of interest statement
Conflicts of Interest: None declared.
Figures


Similar articles
-
Comparative performance analysis of global and chinese-domain large language models for myopia.Eye (Lond). 2025 Jul;39(10):2015-2022. doi: 10.1038/s41433-025-03775-5. Epub 2025 Apr 13. Eye (Lond). 2025. PMID: 40223113
-
Comparing the performance of ChatGPT and ERNIE Bot in answering questions regarding liver cancer interventional radiology in Chinese and English contexts: A comparative study.Digit Health. 2025 Jan 23;11:20552076251315511. doi: 10.1177/20552076251315511. eCollection 2025 Jan-Dec. Digit Health. 2025. PMID: 39850627 Free PMC article.
-
The performance of ChatGPT and ERNIE Bot in surgical resident examinations.Int J Med Inform. 2025 Aug;200:105906. doi: 10.1016/j.ijmedinf.2025.105906. Epub 2025 Apr 4. Int J Med Inform. 2025. PMID: 40220627
-
Evaluation of ChatGPT-generated medical responses: A systematic review and meta-analysis.J Biomed Inform. 2024 Mar;151:104620. doi: 10.1016/j.jbi.2024.104620. Epub 2024 Mar 8. J Biomed Inform. 2024. PMID: 38462064
-
Utility of artificial intelligence-based large language models in ophthalmic care.Ophthalmic Physiol Opt. 2024 May;44(3):641-671. doi: 10.1111/opo.13284. Epub 2024 Feb 25. Ophthalmic Physiol Opt. 2024. PMID: 38404172 Review.
Cited by
-
A Comparative Analysis of GPT-4o and ERNIE Bot in a Chinese Radiation Oncology Exam.J Cancer Educ. 2025 May 26. doi: 10.1007/s13187-025-02652-9. Online ahead of print. J Cancer Educ. 2025. PMID: 40418520
-
Large Language Models for Mental Health Applications: Systematic Review.JMIR Ment Health. 2024 Oct 18;11:e57400. doi: 10.2196/57400. JMIR Ment Health. 2024. PMID: 39423368 Free PMC article.
-
Performance of Artificial Intelligence Chatbots on Ultrasound Examinations: Cross-Sectional Comparative Analysis.JMIR Med Inform. 2025 Jan 9;13:e63924. doi: 10.2196/63924. JMIR Med Inform. 2025. PMID: 39814698 Free PMC article.
-
The Applications of Large Language Models in Mental Health: Scoping Review.J Med Internet Res. 2025 May 5;27:e69284. doi: 10.2196/69284. J Med Internet Res. 2025. PMID: 40324177 Free PMC article.
-
MedBot vs RealDoc: efficacy of large language modeling in physician-patient communication for rare diseases.J Am Med Inform Assoc. 2025 May 1;32(5):775-783. doi: 10.1093/jamia/ocaf034. J Am Med Inform Assoc. 2025. PMID: 39998911 Free PMC article.
References
-
- Edelmann A, Wolff T, Montagne D, Bail CA. Computational social science and sociology. Annu Rev Sociol. 2020;46(1):61–81. doi: 10.1146/annurev-soc-121919-054621. https://europepmc.org/abstract/MED/34824489 - DOI - PMC - PubMed
-
- Cheng CY, Chiu IM, Hsu MY, Pan HY, Tsai CM, Lin CHR. Deep learning assisted detection of abdominal free fluid in Morison's pouch during focused assessment with sonography in trauma. Front Med (Lausanne) 2021;8:707437. doi: 10.3389/fmed.2021.707437. https://europepmc.org/abstract/MED/34631730 - DOI - PMC - PubMed
-
- Singhal K, Azizi S, Tu T, Mahdavi SS, Wei J, Chung HW, Scales N, Tanwani A, Cole-Lewis H, Pfohl S, Payne P, Seneviratne M, Gamble P, Kelly C, Babiker A, Schärli N, Chowdhery A, Mansfield P, Demner-Fushman D, Arcas BAY, Webster D, Corrado GS, Matias Y, Chou K, Gottweis J, Tomasev N, Liu Y, Rajkomar A, Barral J, Semturs C, Karthikesalingam A, Natarajan V. Large language models encode clinical knowledge. Nature. 2023;620(7972):172–180. doi: 10.1038/s41586-023-06291-2. https://europepmc.org/abstract/MED/37438534 10.1038/s41586-023-06291-2 - DOI - PMC - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
