

Vision-language foundation model for echocardiogram interpretation
- PMID: 38689062
- PMCID: PMC11108770
- DOI: 10.1038/s41591-024-02959-y
Vision-language foundation model for echocardiogram interpretation
Abstract
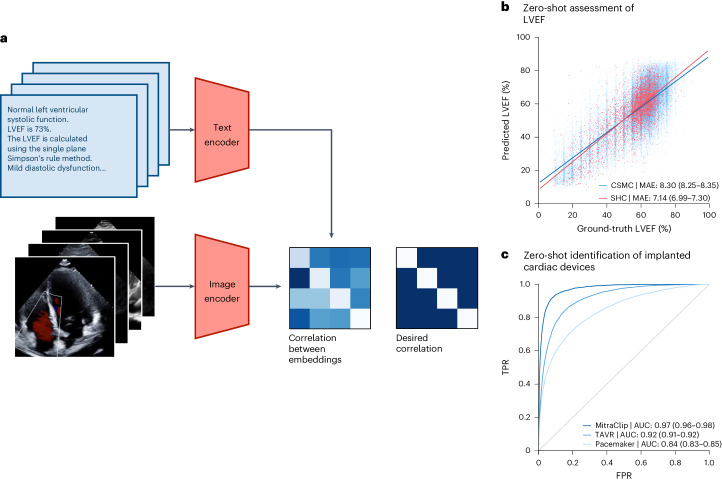
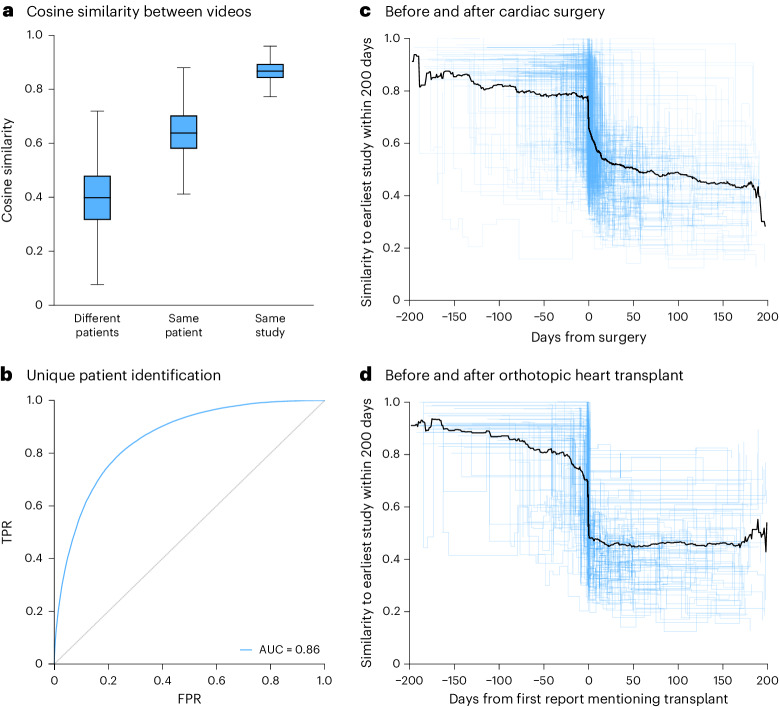
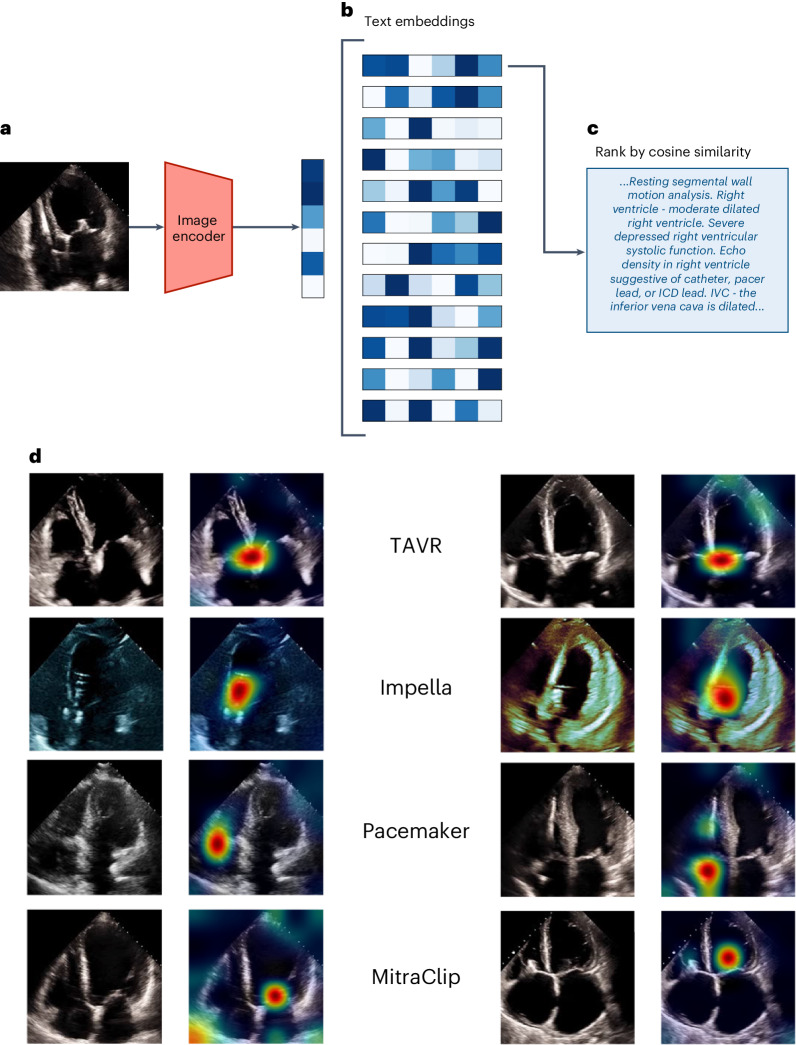
The development of robust artificial intelligence models for echocardiography has been limited by the availability of annotated clinical data. Here, to address this challenge and improve the performance of cardiac imaging models, we developed EchoCLIP, a vision-language foundation model for echocardiography, that learns the relationship between cardiac ultrasound images and the interpretations of expert cardiologists across a wide range of patients and indications for imaging. After training on 1,032,975 cardiac ultrasound videos and corresponding expert text, EchoCLIP performs well on a diverse range of benchmarks for cardiac image interpretation, despite not having been explicitly trained for individual interpretation tasks. EchoCLIP can assess cardiac function (mean absolute error of 7.1% when predicting left ventricular ejection fraction in an external validation dataset) and identify implanted intracardiac devices (area under the curve (AUC) of 0.84, 0.92 and 0.97 for pacemakers, percutaneous mitral valve repair and artificial aortic valves, respectively). We also developed a long-context variant (EchoCLIP-R) using a custom tokenizer based on common echocardiography concepts. EchoCLIP-R accurately identified unique patients across multiple videos (AUC of 0.86), identified clinical transitions such as heart transplants (AUC of 0.79) and cardiac surgery (AUC 0.77) and enabled robust image-to-text search (mean cross-modal retrieval rank in the top 1% of candidate text reports). These capabilities represent a substantial step toward understanding and applying foundation models in cardiovascular imaging for preliminary interpretation of echocardiographic findings.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures


References
-
- Heidenreich PA, et al. 2022 AHA/ACC/HFSA guideline for the management of heart failure: executive summary: a report of the American College of Cardiology/American Heart Association Joint Committee on Clinical Practice Guidelines. Circulation. 2022;145:e876–e894. - PubMed
-
- Al-Khatib SM, et al. 2017 AHA/ACC/HRS guideline for management of patients with ventricular arrhythmias and the prevention of sudden cardiac death: executive summary: a report of the American College of Cardiology/American Heart Association Task Force on Clinical Practice Guidelines and the Heart Rhythm Society. Circulation. 2018;138:e210–e271. - PubMed
