

Representational drift as a result of implicit regularization
- PMID: 38695551
- PMCID: PMC11065423
- DOI: 10.7554/eLife.90069
Representational drift as a result of implicit regularization
Abstract
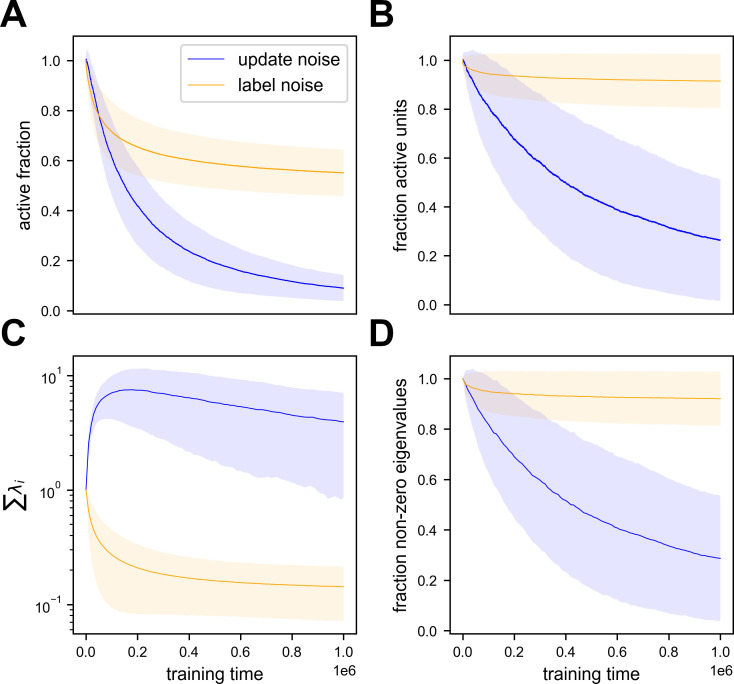
Recent studies show that, even in constant environments, the tuning of single neurons changes over time in a variety of brain regions. This representational drift has been suggested to be a consequence of continuous learning under noise, but its properties are still not fully understood. To investigate the underlying mechanism, we trained an artificial network on a simplified navigational task. The network quickly reached a state of high performance, and many units exhibited spatial tuning. We then continued training the network and noticed that the activity became sparser with time. Initial learning was orders of magnitude faster than ensuing sparsification. This sparsification is consistent with recent results in machine learning, in which networks slowly move within their solution space until they reach a flat area of the loss function. We analyzed four datasets from different labs, all demonstrating that CA1 neurons become sparser and more spatially informative with exposure to the same environment. We conclude that learning is divided into three overlapping phases: (i) Fast familiarity with the environment; (ii) slow implicit regularization; and (iii) a steady state of null drift. The variability in drift dynamics opens the possibility of inferring learning algorithms from observations of drift statistics.
Keywords: CA1; artificial neural network; mouse; neuroscience; noise; regularization; representational drift; theoretical neuroscience.
© 2023, Ratzon et al.
Conflict of interest statement
AR, DD, OB No competing interests declared
Figures








Update of
-
Representational drift as a result of implicit regularization.bioRxiv [Preprint]. 2024 Feb 7:2023.05.04.539512. doi: 10.1101/2023.05.04.539512. bioRxiv. 2024. Update in: Elife. 2024 May 02;12:RP90069. doi: 10.7554/eLife.90069. PMID: 38370656 Free PMC article. Updated. Preprint.
Similar articles
-
Representational drift as a result of implicit regularization.bioRxiv [Preprint]. 2024 Feb 7:2023.05.04.539512. doi: 10.1101/2023.05.04.539512. bioRxiv. 2024. Update in: Elife. 2024 May 02;12:RP90069. doi: 10.7554/eLife.90069. PMID: 38370656 Free PMC article. Updated. Preprint.
-
The geometry of representational drift in natural and artificial neural networks.PLoS Comput Biol. 2022 Nov 28;18(11):e1010716. doi: 10.1371/journal.pcbi.1010716. eCollection 2022 Nov. PLoS Comput Biol. 2022. PMID: 36441762 Free PMC article.
-
RatInABox, a toolkit for modelling locomotion and neuronal activity in continuous environments.Elife. 2024 Feb 9;13:e85274. doi: 10.7554/eLife.85274. Elife. 2024. PMID: 38334473 Free PMC article.
-
Representations and generalization in artificial and brain neural networks.Proc Natl Acad Sci U S A. 2024 Jul 2;121(27):e2311805121. doi: 10.1073/pnas.2311805121. Epub 2024 Jun 24. Proc Natl Acad Sci U S A. 2024. PMID: 38913896 Free PMC article. Review.
-
Representational drift as a window into neural and behavioural plasticity.Curr Opin Neurobiol. 2023 Aug;81:102746. doi: 10.1016/j.conb.2023.102746. Epub 2023 Jun 29. Curr Opin Neurobiol. 2023. PMID: 37392671 Review.
Cited by
-
Aligned and oblique dynamics in recurrent neural networks.Elife. 2024 Nov 27;13:RP93060. doi: 10.7554/eLife.93060. Elife. 2024. PMID: 39601404 Free PMC article.
-
Representational drift and learning-induced stabilization in the piriform cortex.Proc Natl Acad Sci U S A. 2025 Jul 22;122(29):e2501811122. doi: 10.1073/pnas.2501811122. Epub 2025 Jul 16. Proc Natl Acad Sci U S A. 2025. PMID: 40668830
-
Representational drift without synaptic plasticity.bioRxiv [Preprint]. 2025 Jul 29:2025.07.23.666352. doi: 10.1101/2025.07.23.666352. bioRxiv. 2025. PMID: 40766535 Free PMC article. Preprint.
-
Time Makes Space: Emergence of Place Fields in Networks Encoding Temporally Continuous Sensory Experiences.ArXiv [Preprint]. 2025 Jul 9:arXiv:2408.05798v3. ArXiv. 2025. PMID: 39975441 Free PMC article. Preprint.
-
Representational drift as the consequence of ongoing memory storage.Sci Rep. 2025 Jul 30;15(1):27746. doi: 10.1038/s41598-025-11102-x. Sci Rep. 2025. PMID: 40739304 Free PMC article.
References
-
- Aviv-Ratzon Driftreg. swh:1:rev:cb83d928b66401405c26500ab93b4b98ef7b3b67Software Heritage. 2024 https://archive.softwareheritage.org/swh:1:dir:b6b2c3944401b7c73209f6d47...
-
- Bengio Y, Lee DH, Bornschein J, Mesnard T, Lin Z. Towards Biologically Plausible Deep Learning. arXiv. 2015 https://arxiv.org/abs/1502.04156
-
- Blanc G, Gupta N, Valiant G, Valiant P. Implicit regularization for deep neural networks driven by an ornstein-uhlenbeck like process. Conference on learning theory.2020.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
