

Reinforcement learning for closed-loop regulation of cardiovascular system with vagus nerve stimulation: a computational study
- PMID: 38718787
- PMCID: PMC11145940
- DOI: 10.1088/1741-2552/ad48bb
Reinforcement learning for closed-loop regulation of cardiovascular system with vagus nerve stimulation: a computational study
Abstract
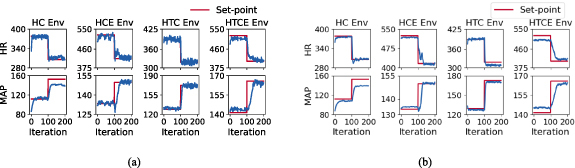
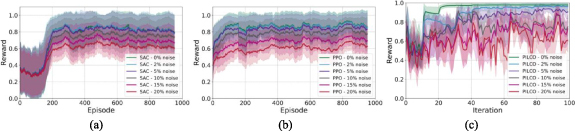
Objective. Vagus nerve stimulation (VNS) is being investigated as a potential therapy for cardiovascular diseases including heart failure, cardiac arrhythmia, and hypertension. The lack of a systematic approach for controlling and tuning the VNS parameters poses a significant challenge. Closed-loop VNS strategies combined with artificial intelligence (AI) approaches offer a framework for systematically learning and adapting the optimal stimulation parameters. In this study, we presented an interactive AI framework using reinforcement learning (RL) for automated data-driven design of closed-loop VNS control systems in a computational study.Approach.Multiple simulation environments with a standard application programming interface were developed to facilitate the design and evaluation of the automated data-driven closed-loop VNS control systems. These environments simulate the hemodynamic response to multi-location VNS using biophysics-based computational models of healthy and hypertensive rat cardiovascular systems in resting and exercise states. We designed and implemented the RL-based closed-loop VNS control frameworks in the context of controlling the heart rate and the mean arterial pressure for a set point tracking task. Our experimental design included two approaches; a general policy using deep RL algorithms and a sample-efficient adaptive policy using probabilistic inference for learning and control.Main results.Our simulation results demonstrated the capabilities of the closed-loop RL-based approaches to learn optimal VNS control policies and to adapt to variations in the target set points and the underlying dynamics of the cardiovascular system. Our findings highlighted the trade-off between sample-efficiency and generalizability, providing insights for proper algorithm selection. Finally, we demonstrated that transfer learning improves the sample efficiency of deep RL algorithms allowing the development of more efficient and personalized closed-loop VNS systems.Significance.We demonstrated the capability of RL-based closed-loop VNS systems. Our approach provided a systematic adaptable framework for learning control strategies without requiring prior knowledge about the underlying dynamics.
Keywords: closed-loop VNS; intelligent systems; neuromodulation; reinforcement learning.
Creative Commons Attribution license.
Figures











References
-
- Mozaffarian D, et al. Heart disease and stroke statistics—2016 update: a report from the American heart association. Circulation. 2016;133:e38–360. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources