

Accuracy, readability, and understandability of large language models for prostate cancer information to the public
- PMID: 38744934
- PMCID: PMC12106072
- DOI: 10.1038/s41391-024-00826-y
Accuracy, readability, and understandability of large language models for prostate cancer information to the public
Abstract
Background: Generative Pretrained Model (GPT) chatbots have gained popularity since the public release of ChatGPT. Studies have evaluated the ability of different GPT models to provide information about medical conditions. To date, no study has assessed the quality of ChatGPT outputs to prostate cancer related questions from both the physician and public perspective while optimizing outputs for patient consumption.
Methods: Nine prostate cancer-related questions, identified through Google Trends (Global), were categorized into diagnosis, treatment, and postoperative follow-up. These questions were processed using ChatGPT 3.5, and the responses were recorded. Subsequently, these responses were re-inputted into ChatGPT to create simplified summaries understandable at a sixth-grade level. Readability of both the original ChatGPT responses and the layperson summaries was evaluated using validated readability tools. A survey was conducted among urology providers (urologists and urologists in training) to rate the original ChatGPT responses for accuracy, completeness, and clarity using a 5-point Likert scale. Furthermore, two independent reviewers evaluated the layperson summaries on correctness trifecta: accuracy, completeness, and decision-making sufficiency. Public assessment of the simplified summaries' clarity and understandability was carried out through Amazon Mechanical Turk (MTurk). Participants rated the clarity and demonstrated their understanding through a multiple-choice question.
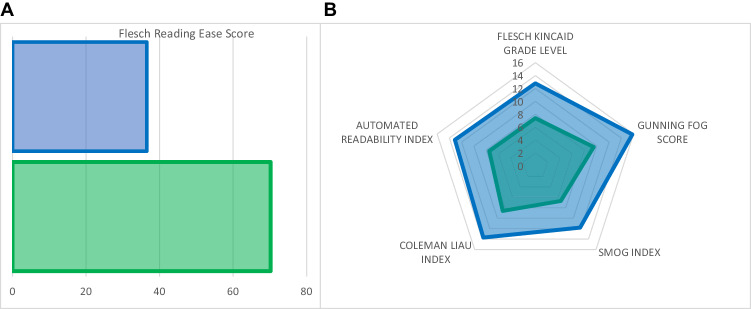
Results: GPT-generated output was deemed correct by 71.7% to 94.3% of raters (36 urologists, 17 urology residents) across 9 scenarios. GPT-generated simplified layperson summaries of this output was rated as accurate in 8 of 9 (88.9%) scenarios and sufficient for a patient to make a decision in 8 of 9 (88.9%) scenarios. Mean readability of layperson summaries was higher than original GPT outputs ([original ChatGPT v. simplified ChatGPT, mean (SD), p-value] Flesch Reading Ease: 36.5(9.1) v. 70.2(11.2), <0.0001; Gunning Fog: 15.8(1.7) v. 9.5(2.0), p < 0.0001; Flesch Grade Level: 12.8(1.2) v. 7.4(1.7), p < 0.0001; Coleman Liau: 13.7(2.1) v. 8.6(2.4), 0.0002; Smog index: 11.8(1.2) v. 6.7(1.8), <0.0001; Automated Readability Index: 13.1(1.4) v. 7.5(2.1), p < 0.0001). MTurk workers (n = 514) rated the layperson summaries as correct (89.5-95.7%) and correctly understood the content (63.0-87.4%).
Conclusion: GPT shows promise for correct patient education for prostate cancer-related contents, but the technology is not designed for delivering patients information. Prompting the model to respond with accuracy, completeness, clarity and readability may enhance its utility when used for GPT-powered medical chatbots.
© 2024. The Author(s).
Conflict of interest statement
Competing interests: The authors declare no competing interests.
Figures

References
-
- Cacciamani GE, Dell’Oglio P, Cocci A, Russo GI, De Castro Abreu A, Gill IS, et al. Asking “Dr. Google” for a second opinion: the devil is in the details. Eur Urol Focus. 2021;7:479–81. - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
