

Physician and Artificial Intelligence Chatbot Responses to Cancer Questions From Social Media
- PMID: 38753317
- PMCID: PMC11099835
- DOI: 10.1001/jamaoncol.2024.0836
Physician and Artificial Intelligence Chatbot Responses to Cancer Questions From Social Media
Abstract
Importance: Artificial intelligence (AI) chatbots pose the opportunity to draft template responses to patient questions. However, the ability of chatbots to generate responses based on domain-specific knowledge of cancer remains to be tested.
Objective: To evaluate the competency of AI chatbots (GPT-3.5 [chatbot 1], GPT-4 [chatbot 2], and Claude AI [chatbot 3]) to generate high-quality, empathetic, and readable responses to patient questions about cancer.
Design, setting, and participants: This equivalence study compared the AI chatbot responses and responses by 6 verified oncologists to 200 patient questions about cancer from a public online forum. Data were collected on May 31, 2023.
Exposures: Random sample of 200 patient questions related to cancer from a public online forum (Reddit r/AskDocs) spanning from January 1, 2018, to May 31, 2023, was posed to 3 AI chatbots.
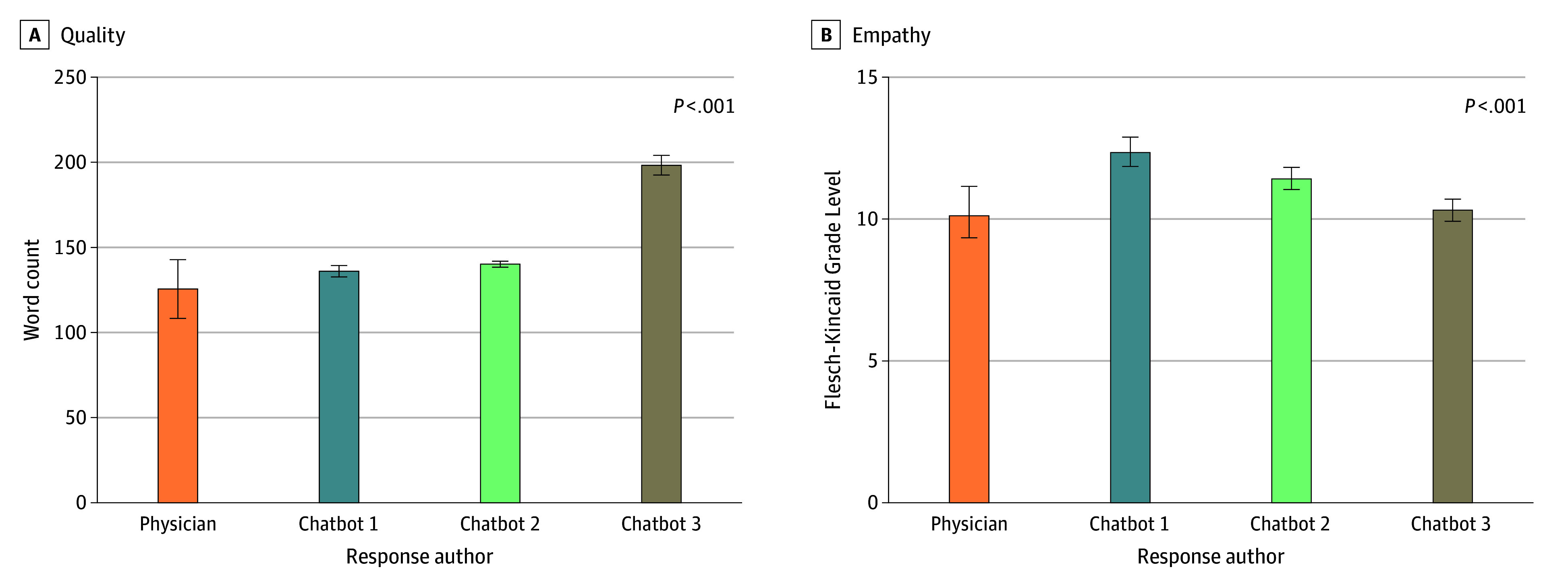
Main outcomes and measures: The primary outcomes were pilot ratings of the quality, empathy, and readability on a Likert scale from 1 (very poor) to 5 (very good). Two teams of attending oncology specialists evaluated each response based on pilot measures of quality, empathy, and readability in triplicate. The secondary outcome was readability assessed using Flesch-Kincaid Grade Level.
Results: Responses to 200 questions generated by chatbot 3, the best-performing AI chatbot, were rated consistently higher in overall measures of quality (mean, 3.56 [95% CI, 3.48-3.63] vs 3.00 [95% CI, 2.91-3.09]; P < .001), empathy (mean, 3.62 [95% CI, 3.53-3.70] vs 2.43 [95% CI, 2.32-2.53]; P < .001), and readability (mean, 3.79 [95% CI, 3.72-3.87] vs 3.07 [95% CI, 3.00-3.15]; P < .001) compared with physician responses. The mean Flesch-Kincaid Grade Level of physician responses (mean, 10.11 [95% CI, 9.21-11.03]) was not significantly different from chatbot 3 responses (mean, 10.31 [95% CI, 9.89-10.72]; P > .99) but was lower than those from chatbot 1 (mean, 12.33 [95% CI, 11.84-12.83]; P < .001) and chatbot 2 (mean, 11.32 [95% CI, 11.05-11.79]; P = .01).
Conclusions and relevance: The findings of this study suggest that chatbots can generate quality, empathetic, and readable responses to patient questions comparable to physician responses sourced from an online forum. Further research is required to assess the scope, process integration, and patient and physician outcomes of chatbot-facilitated interactions.
Conflict of interest statement
Figures

References
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
