

Enhancing drug and cell line representations via contrastive learning for improved anti-cancer drug prioritization
- PMID: 38762647
- PMCID: PMC11102516
- DOI: 10.1038/s41698-024-00589-8
Enhancing drug and cell line representations via contrastive learning for improved anti-cancer drug prioritization
Abstract
Due to cancer's complex nature and variable response to therapy, precision oncology informed by omics sequence analysis has become the current standard of care. However, the amount of data produced for each patient makes it difficult to quickly identify the best treatment regimen. Moreover, limited data availability has hindered computational methods' abilities to learn patterns associated with effective drug-cell line pairs. In this work, we propose the use of contrastive learning to improve learned drug and cell line representations by preserving relationship structures associated with drug mechanisms of action and cell line cancer types. In addition to achieving enhanced performance relative to a state-of-the-art method, we find that classifiers using our learned representations exhibit a more balanced reliance on drug- and cell line-derived features when making predictions. This facilitates more personalized drug prioritizations that are informed by signals related to drug resistance.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
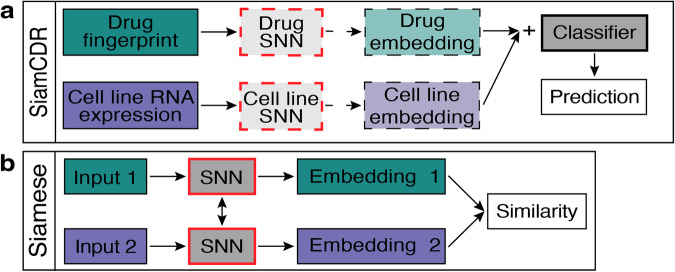
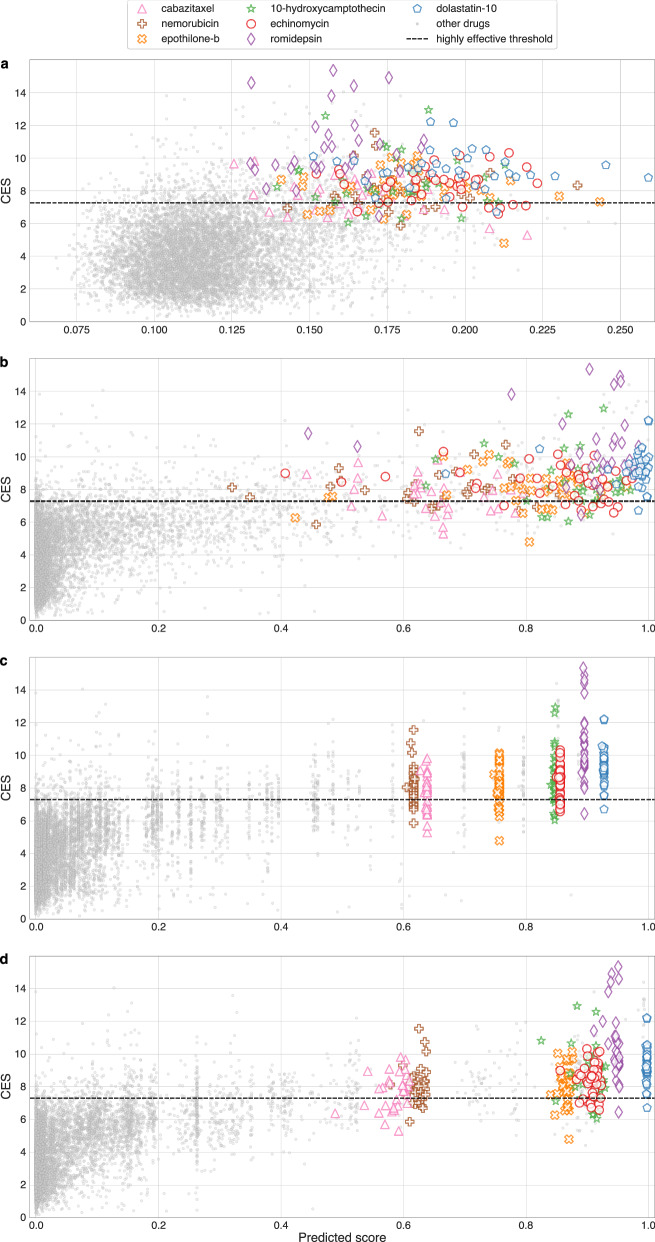
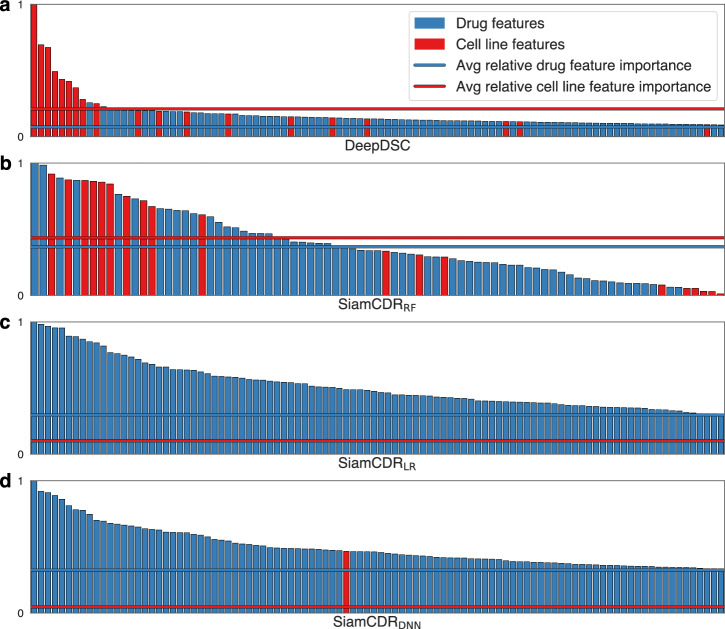
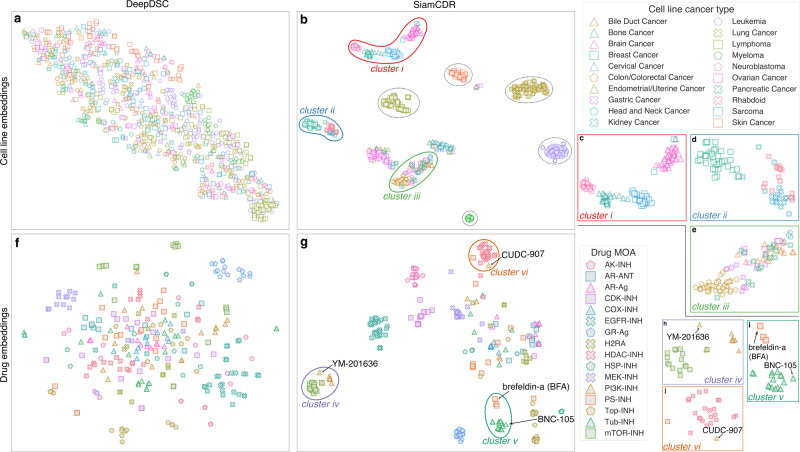
References
-
- Zou H, Hastie T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B: Stat. Methodol. 2005;67:301–320. doi: 10.1111/j.1467-9868.2005.00503.x. - DOI
-
- Morgan HL. The generation of a unique machine description for chemical structures-a technique developed at chemical abstracts service. J. Chem. Doc. 1965;5:107–113. doi: 10.1021/c160017a018. - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
