

A comparison of visual and auditory EEG interfaces for robot multi-stage task control
- PMID: 38783889
- PMCID: PMC11111866
- DOI: 10.3389/frobt.2024.1329270
A comparison of visual and auditory EEG interfaces for robot multi-stage task control
Abstract
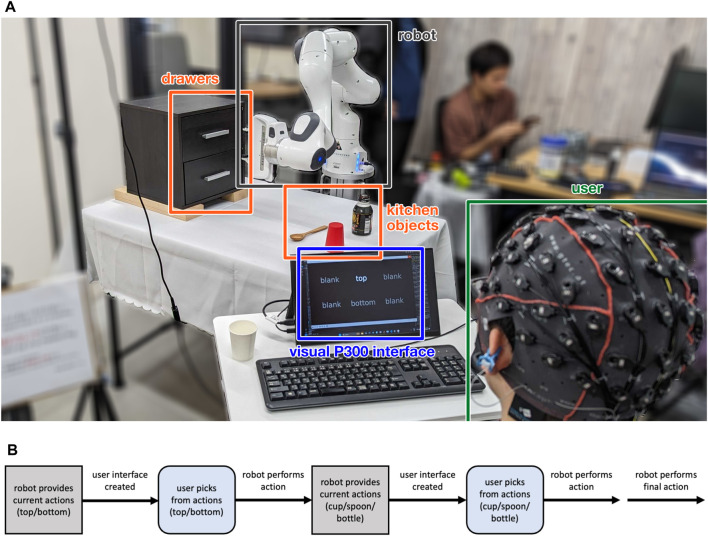
Shared autonomy holds promise for assistive robotics, whereby physically-impaired people can direct robots to perform various tasks for them. However, a robot that is capable of many tasks also introduces many choices for the user, such as which object or location should be the target of interaction. In the context of non-invasive brain-computer interfaces for shared autonomy-most commonly electroencephalography-based-the two most common choices are to provide either auditory or visual stimuli to the user-each with their respective pros and cons. Using the oddball paradigm, we designed comparable auditory and visual interfaces to speak/display the choices to the user, and had users complete a multi-stage robotic manipulation task involving location and object selection. Users displayed differing competencies-and preferences-for the different interfaces, highlighting the importance of considering modalities outside of vision when constructing human-robot interfaces.
Keywords: brain-computer interface; human-robot interaction; imitation learning; multitask learning; shared autonomy.
Copyright © 2024 Arulkumaran, Di Vincenzo, Dossa, Akiyama, Ogawa Lillrank, Sato, Tomeoka and Sasai.
Conflict of interest statement
Authors KA, MD, RJ, SA, DL, MS, KT, and SS were employed by Araya Inc.
Figures



Similar articles
-
EEG-Controlled Wall-Crawling Cleaning Robot Using SSVEP-Based Brain-Computer Interface.J Healthc Eng. 2020 Jan 11;2020:6968713. doi: 10.1155/2020/6968713. eCollection 2020. J Healthc Eng. 2020. PMID: 32399166 Free PMC article.
-
A brain-actuated robotic arm system using non-invasive hybrid brain-computer interface and shared control strategy.J Neural Eng. 2021 May 5;18(4). doi: 10.1088/1741-2552/abf8cb. J Neural Eng. 2021. PMID: 33862607
-
Robot Learning of Assistive Manipulation Tasks by Demonstration via Head Gesture-based Interface.IEEE Int Conf Rehabil Robot. 2019 Jun;2019:1139-1146. doi: 10.1109/ICORR.2019.8779379. IEEE Int Conf Rehabil Robot. 2019. PMID: 31374783
-
Shared autonomy in assistive mobile robots: a review.Disabil Rehabil Assist Technol. 2023 Aug;18(6):827-848. doi: 10.1080/17483107.2021.1928778. Epub 2021 Jun 16. Disabil Rehabil Assist Technol. 2023. PMID: 34133906
-
Robotic and Virtual Reality BCIs Using Spatial Tactile and Auditory Oddball Paradigms.Front Neurorobot. 2016 Dec 6;10:20. doi: 10.3389/fnbot.2016.00020. eCollection 2016. Front Neurorobot. 2016. PMID: 27999538 Free PMC article. Review.
References
-
- Ahn M., Brohan A., Brown N., Chebotar Y., Cortes O., David B., et al. (2022). Do as i can, not as i say: grounding language in robotic affordances. Available at: https://arxiv.org/abs/2204.01691.
-
- Akinola I., Chen B., Koss J., Patankar A., Varley J., Allen P. (2017). “Task level hierarchical system for bci-enabled shared autonomy,” in 2017 IEEE-RAS 17th International Conference on Humanoid Robotics (Humanoids), Birmingham, UK, November, 2017, 219–225.
-
- Akiyama S., Lillrank D. O., Arulkumaran K. (2023). “Fine-grained object detection and manipulation with segmentation-conditioned perceiver-actor,” in ICRA Workshop on Pretraining for Robotics, London, United Kingdom, May, 2023.
-
- Aljalal M., Ibrahim S., Djemal R., Ko W. (2020). Comprehensive review on brain-controlled mobile robots and robotic arms based on electroencephalography signals. Intell. Serv. Robot. 13, 539–563. 10.1007/s11370-020-00328-5 - DOI
-
- Ao J., Wang R., Zhou L., Wang C., Ren S., Wu Y., et al. (2022). “Speecht5: unified-modal encoder-decoder pre-training for spoken language processing,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, May, 2022, 5723–5738.
LinkOut - more resources
Full Text Sources
Miscellaneous