

MolScore: a scoring, evaluation and benchmarking framework for generative models in de novo drug design
- PMID: 38816825
- PMCID: PMC11141043
- DOI: 10.1186/s13321-024-00861-w
MolScore: a scoring, evaluation and benchmarking framework for generative models in de novo drug design
Abstract
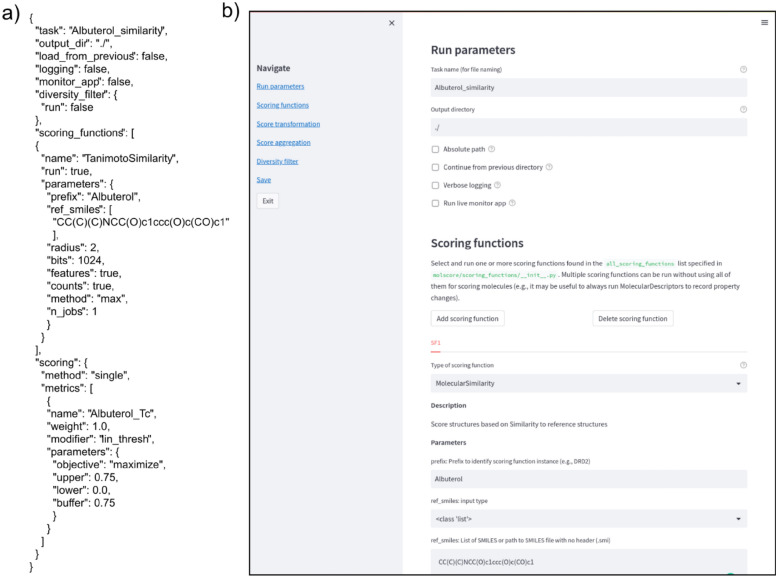
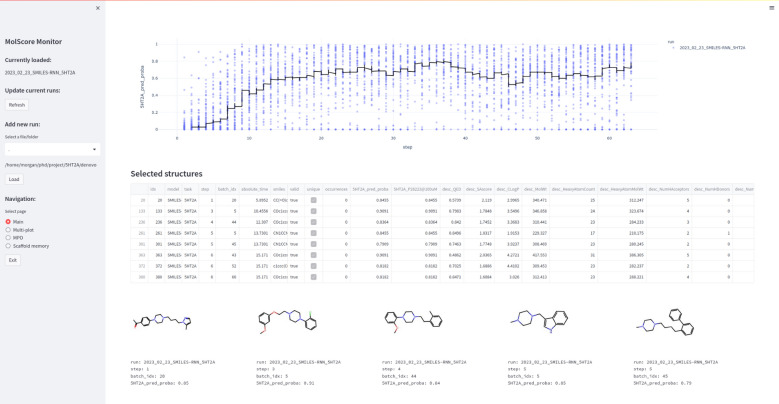
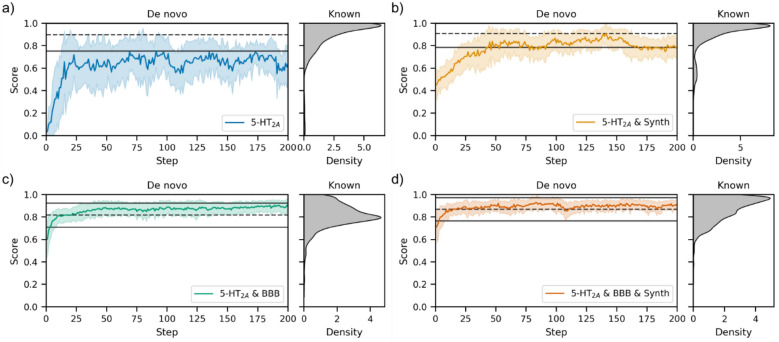
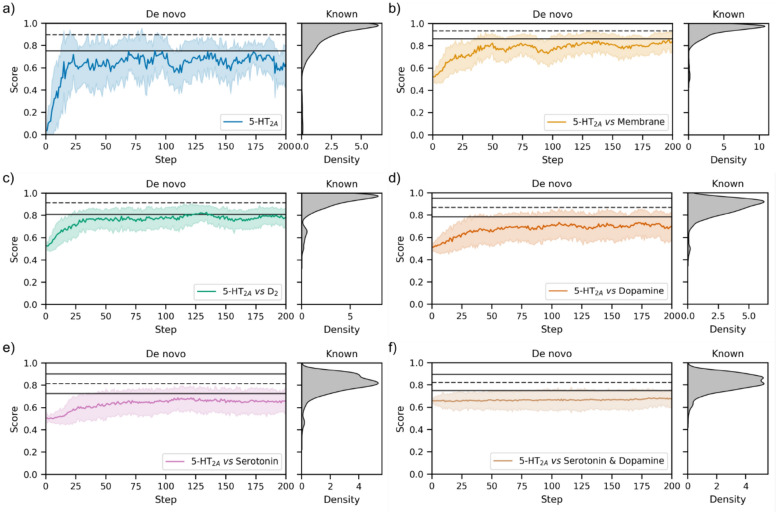
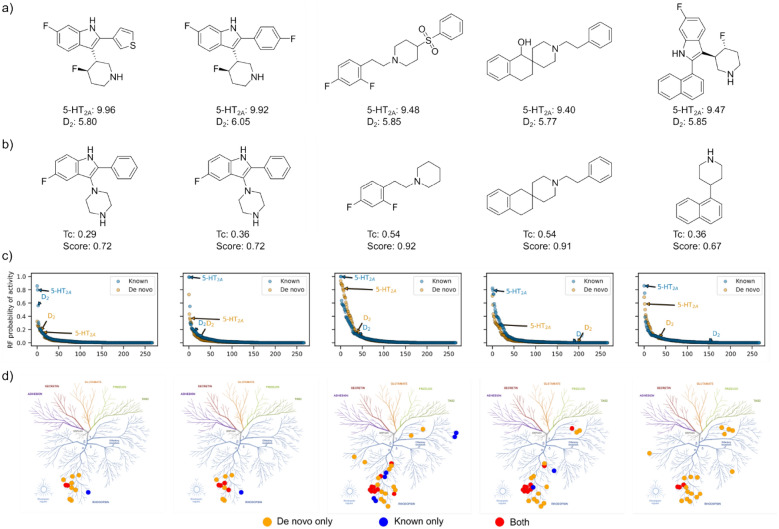
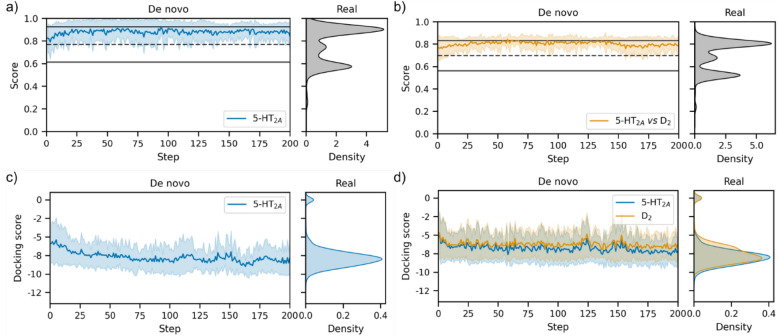
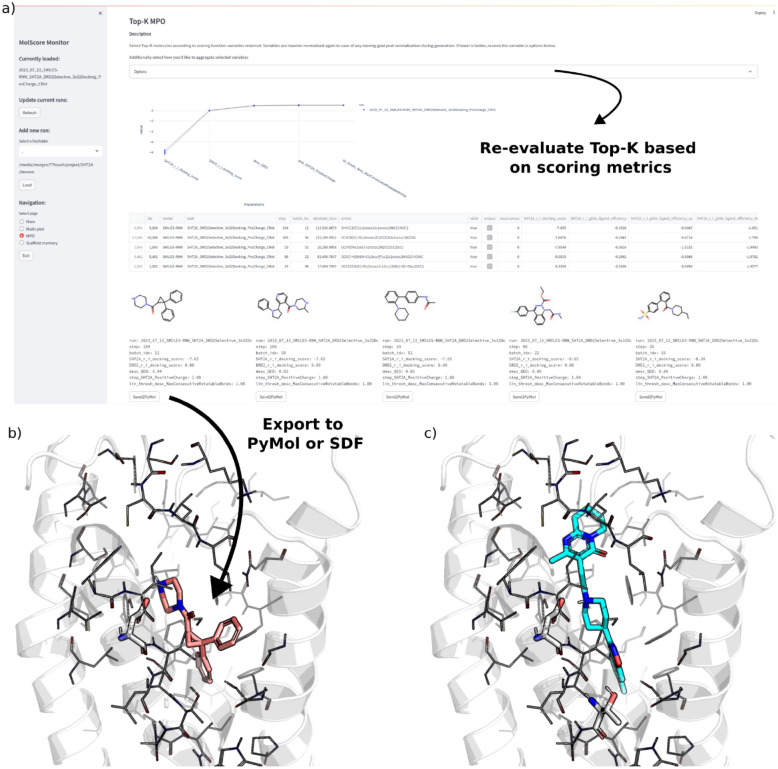
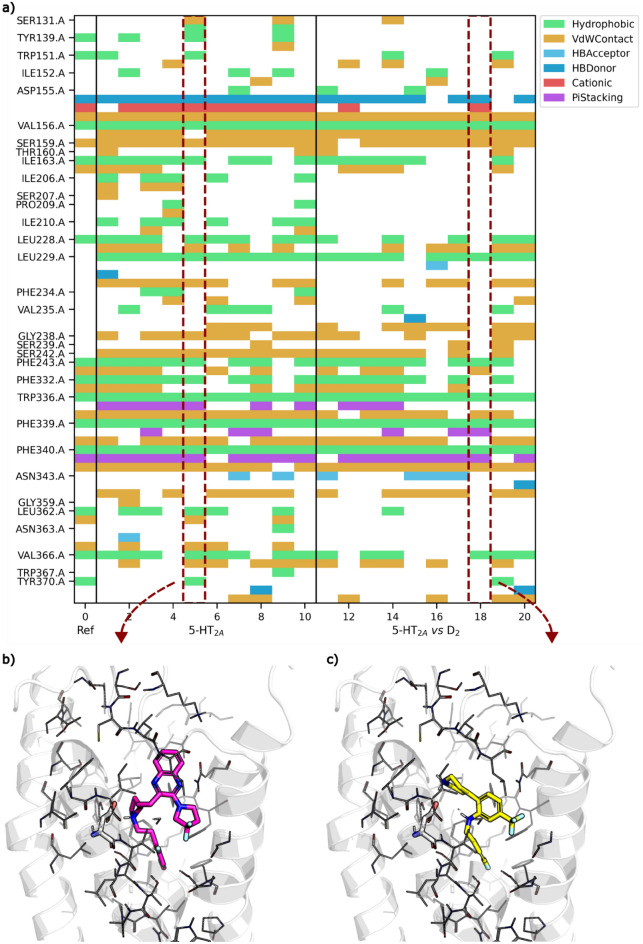
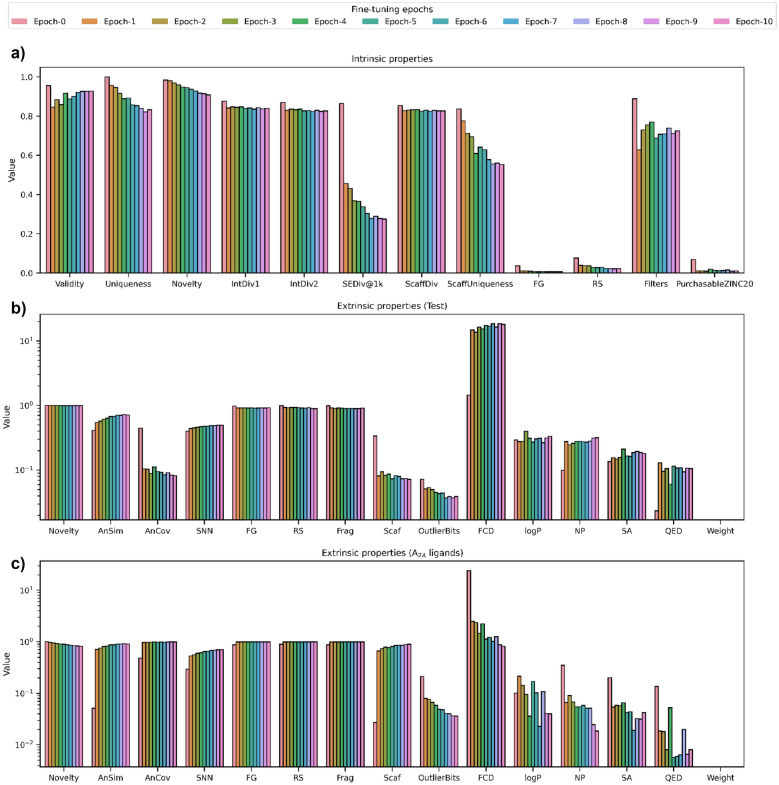
Generative models are undergoing rapid research and application to de novo drug design. To facilitate their application and evaluation, we present MolScore. MolScore already contains many drug-design-relevant scoring functions commonly used in benchmarks such as, molecular similarity, molecular docking, predictive models, synthesizability, and more. In addition, providing performance metrics to evaluate generative model performance based on the chemistry generated. With this unification of functionality, MolScore re-implements commonly used benchmarks in the field (such as GuacaMol, MOSES, and MolOpt). Moreover, new benchmarks can be created trivially. We demonstrate this by testing a chemical language model with reinforcement learning on three new tasks of increasing complexity related to the design of 5-HT2a ligands that utilise either molecular descriptors, 266 pre-trained QSAR models, or dual molecular docking. Lastly, MolScore can be integrated into an existing Python script with just three lines of code. This framework is a step towards unifying generative model application and evaluation as applied to drug design for both practitioners and researchers. The framework can be found on GitHub and downloaded directly from the Python Package Index.Scientific ContributionMolScore is an open-source platform to facilitate generative molecular design and evaluation thereof for application in drug design. This platform takes important steps towards unifying existing benchmarks, providing a platform to share new benchmarks, and improves customisation, flexibility and usability for practitioners over existing solutions.
Keywords: Benchmarking; De novo molecule generation; Drug design; Generative model; Scoring functions.
© 2024. The Author(s).
Conflict of interest statement
The authors declare that they have no competing interests.
Figures



References
-
- Gao W, Fu T, Sun J, Coley CW. Sample efficiency matters: a benchmark for practical molecular optimization. arxiv. 2022 doi: 10.8550/arxiv.2206.12411. - DOI
LinkOut - more resources
Full Text Sources
