

This is a preprint.
Me-LLaMA: Foundation Large Language Models for Medical Applications
- PMID: 38826372
- PMCID: PMC11142305
- DOI: 10.21203/rs.3.rs-4240043/v1
Me-LLaMA: Foundation Large Language Models for Medical Applications
Abstract
Recent advancements in large language models (LLMs) such as ChatGPT and LLaMA have hinted at their potential to revolutionize medical applications, yet their application in clinical settings often reveals limitations due to a lack of specialized training on medical-specific data. In response to this challenge, this study introduces Me-LLaMA, a novel medical LLM family that includes foundation models - Me-LLaMA 13/70B, along with their chat-enhanced versions - Me-LLaMA 13/70B-chat, developed through continual pre-training and instruction tuning of LLaMA2 using large medical datasets. Our methodology leverages a comprehensive domain-specific data suite, including a large-scale, continual pre-training dataset with 129B tokens, an instruction tuning dataset with 214k samples, and a new medical evaluation benchmark (MIBE) across six critical medical tasks with 12 datasets. Our extensive evaluation using the MIBE shows that Me-LLaMA models achieve overall better performance than existing open-source medical LLMs in zero-shot, few-shot and supervised learning abilities. With task-specific instruction tuning, Me-LLaMA models outperform ChatGPT on 7 out of 8 datasets and GPT-4 on 5 out of 8 datasets. In addition, we investigated the catastrophic forgetting problem, and our results show that Me-LLaMA models outperform other open-source medical LLMs in mitigating this issue. Me-LLaMA is one of the largest open-source medical foundation LLMs that use both biomedical and clinical data. It exhibits superior performance across both general and medical tasks compared to other open-source medical LLMs, rendering it an attractive choice for medical AI applications. We release our models, datasets, and evaluation scripts at: https://github.com/BIDS-Xu-Lab/Me-LLaMA.
Conflict of interest statement
COMPETING INTEREST The authors have no financial or non-financial conflicts of interest to disclose.
Figures
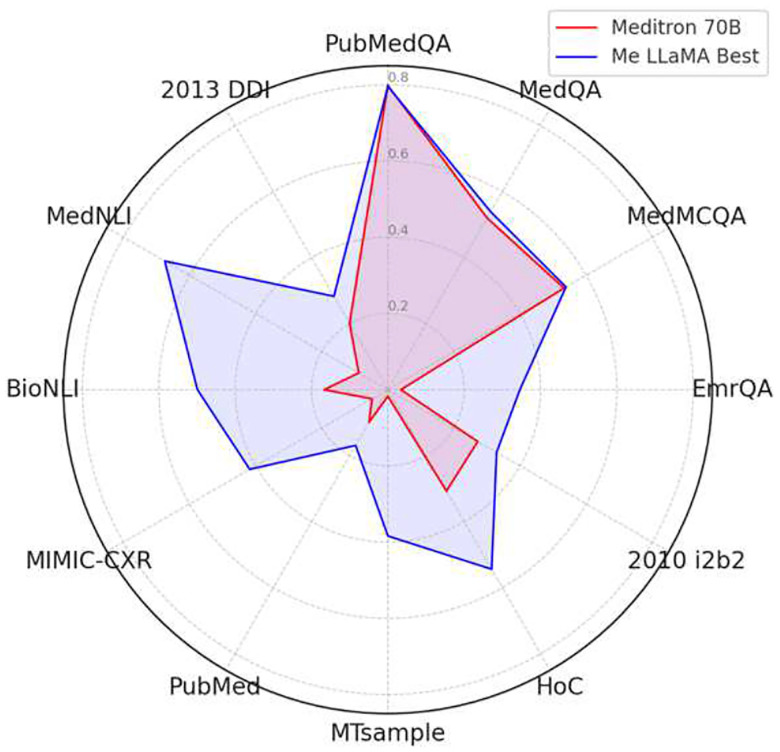
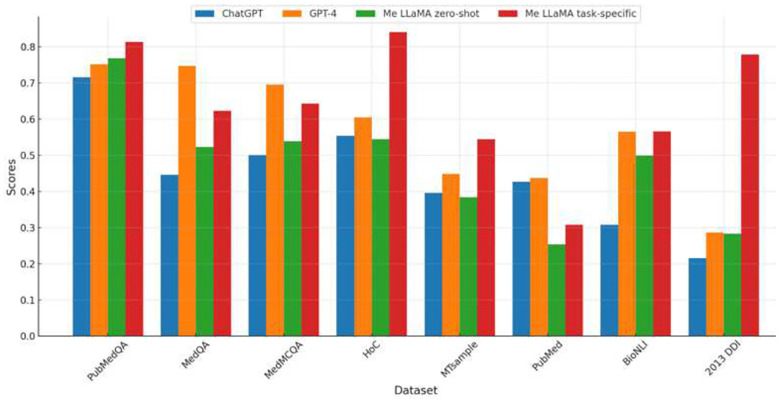
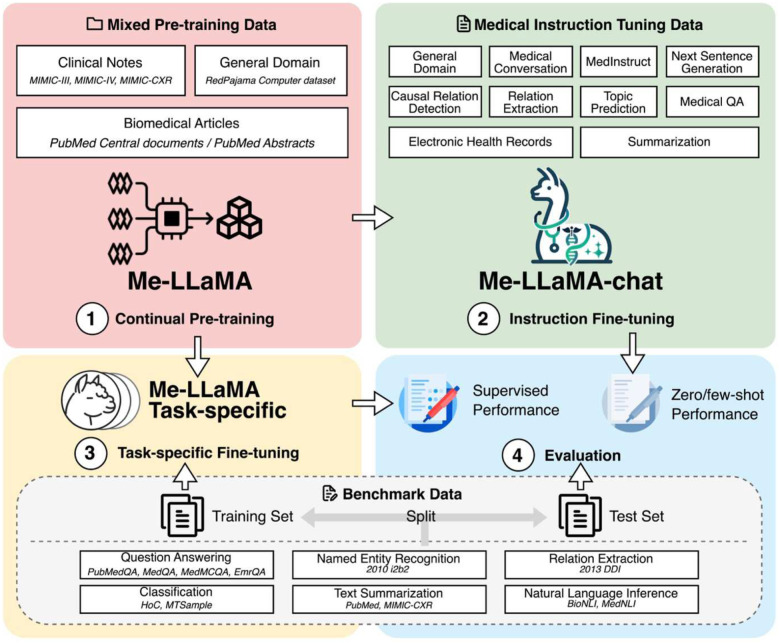
References
-
- Wei J. et al. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682 (2022).
-
- Bubeck S. et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712 (2023).
-
- Nori H., King N., McKinney S. M., Carignan D. & Horvitz E. Capabilities of gpt-4 on medical challenge problems. arXiv preprint arXiv:2303.13375 (2023).
-
- Bengio Y., Ducharme R. & Vincent P. A neural probabilistic language model. Advances neural information processing systems 13 (2000).
-
- Brown T. et al. Language models are few-shot learners. Advances neural information processing systems 33, 1877–1901 (2020).
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
