

This is a preprint.
Large Language Models for Social Determinants of Health Information Extraction from Clinical Notes - A Generalizable Approach across Institutions
- PMID: 38826441
- PMCID: PMC11142292
- DOI: 10.1101/2024.05.21.24307726
Large Language Models for Social Determinants of Health Information Extraction from Clinical Notes - A Generalizable Approach across Institutions
Update in
-
Social determinants of health extraction from clinical notes across institutions using large language models.NPJ Digit Med. 2025 May 17;8(1):287. doi: 10.1038/s41746-025-01645-8. NPJ Digit Med. 2025. PMID: 40379919 Free PMC article.
Abstract
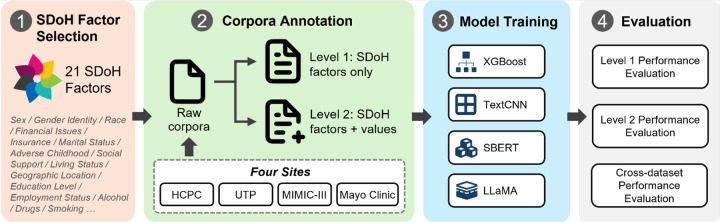
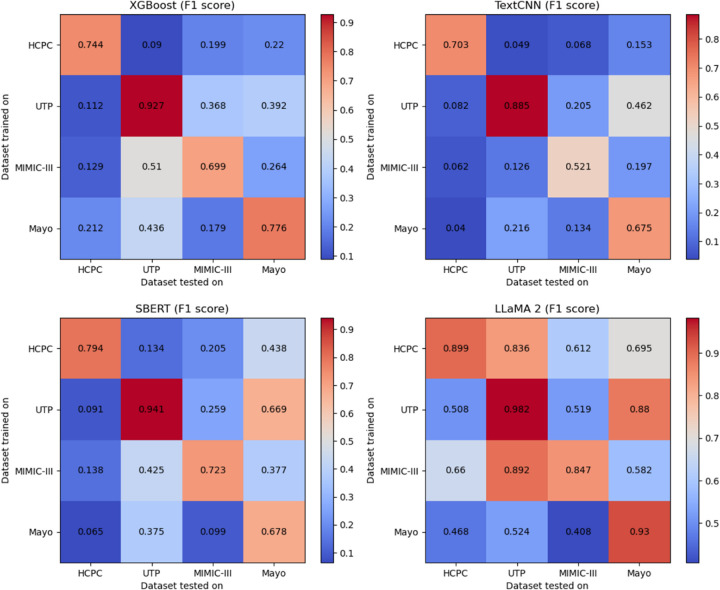
The consistent and persuasive evidence illustrating the influence of social determinants on health has prompted a growing realization throughout the health care sector that enhancing health and health equity will likely depend, at least to some extent, on addressing detrimental social determinants. However, detailed social determinants of health (SDoH) information is often buried within clinical narrative text in electronic health records (EHRs), necessitating natural language processing (NLP) methods to automatically extract these details. Most current NLP efforts for SDoH extraction have been limited, investigating on limited types of SDoH elements, deriving data from a single institution, focusing on specific patient cohorts or note types, with reduced focus on generalizability. This study aims to address these issues by creating cross-institutional corpora spanning different note types and healthcare systems, and developing and evaluating the generalizability of classification models, including novel large language models (LLMs), for detecting SDoH factors from diverse types of notes from four institutions: Harris County Psychiatric Center, University of Texas Physician Practice, Beth Israel Deaconess Medical Center, and Mayo Clinic. Four corpora of deidentified clinical notes were annotated with 21 SDoH factors at two levels: level 1 with SDoH factor types only and level 2 with SDoH factors along with associated values. Three traditional classification algorithms (XGBoost, TextCNN, Sentence BERT) and an instruction tuned LLM-based approach (LLaMA) were developed to identify multiple SDoH factors. Substantial variation was noted in SDoH documentation practices and label distributions based on patient cohorts, note types, and hospitals. The LLM achieved top performance with micro-averaged F1 scores over 0.9 on level 1 annotated corpora and an F1 over 0.84 on level 2 annotated corpora. While models performed well when trained and tested on individual datasets, cross-dataset generalization highlighted remaining obstacles. To foster collaboration, access to partial annotated corpora and models trained by merging all annotated datasets will be made available on the PhysioNet repository.
Keywords: Social determinants of health; electronic health records; large language models; multi-label classification.
Conflict of interest statement
Competing interests All authors declare no financial or non-financial competing interests.
Figures


Similar articles
-
Social determinants of health extraction from clinical notes across institutions using large language models.NPJ Digit Med. 2025 May 17;8(1):287. doi: 10.1038/s41746-025-01645-8. NPJ Digit Med. 2025. PMID: 40379919 Free PMC article.
-
Classifying social determinants of health from unstructured electronic health records using deep learning-based natural language processing.J Biomed Inform. 2022 Mar;127:103984. doi: 10.1016/j.jbi.2021.103984. Epub 2022 Jan 7. J Biomed Inform. 2022. PMID: 35007754
-
Identifying social determinants of health from clinical narratives: A study of performance, documentation ratio, and potential bias.J Biomed Inform. 2024 May;153:104642. doi: 10.1016/j.jbi.2024.104642. Epub 2024 Apr 14. J Biomed Inform. 2024. PMID: 38621641 Free PMC article.
-
Extracting social determinants of health from electronic health records using natural language processing: a systematic review.J Am Med Inform Assoc. 2021 Nov 25;28(12):2716-2727. doi: 10.1093/jamia/ocab170. J Am Med Inform Assoc. 2021. PMID: 34613399 Free PMC article.
-
Realizing the potential of social determinants data in EHR systems: A scoping review of approaches for screening, linkage, extraction, analysis, and interventions.J Clin Transl Sci. 2024 Oct 10;8(1):e147. doi: 10.1017/cts.2024.571. eCollection 2024. J Clin Transl Sci. 2024. PMID: 39478779 Free PMC article.
References
-
- Marmot M, Friel S, Bell R, Houweling TA, Taylor S, Health CoSDo. Closing the gap in a generation: health equity through action on the social determinants of health. The lancet 2008;372(9650):1661–69 - PubMed
-
- Singh GK, Siahpush M, Kogan MD. Neighborhood socioeconomic conditions, built environments, and childhood obesity. Health affairs 2010;29(3):503–12 - PubMed
-
- Felitti VJ, Anda RF, Nordenberg D, et al. Relationship of childhood abuse and household dysfunction to many of the leading causes of death in adults: The Adverse Childhood Experiences (ACE) Study. American journal of preventive medicine 1998;14(4):245–58 - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources