

A practical guide to the implementation of AI in orthopaedic research, Part 6: How to evaluate the performance of AI research?
- PMID: 38826500
- PMCID: PMC11141501
- DOI: 10.1002/jeo2.12039
A practical guide to the implementation of AI in orthopaedic research, Part 6: How to evaluate the performance of AI research?
Abstract
Artificial intelligence's (AI) accelerating progress demands rigorous evaluation standards to ensure safe, effective integration into healthcare's high-stakes decisions. As AI increasingly enables prediction, analysis and judgement capabilities relevant to medicine, proper evaluation and interpretation are indispensable. Erroneous AI could endanger patients; thus, developing, validating and deploying medical AI demands adhering to strict, transparent standards centred on safety, ethics and responsible oversight. Core considerations include assessing performance on diverse real-world data, collaborating with domain experts, confirming model reliability and limitations, and advancing interpretability. Thoughtful selection of evaluation metrics suited to the clinical context along with testing on diverse data sets representing different populations improves generalisability. Partnering software engineers, data scientists and medical practitioners ground assessment in real needs. Journals must uphold reporting standards matching AI's societal impacts. With rigorous, holistic evaluation frameworks, AI can progress towards expanding healthcare access and quality.
Level of evidence: Level V.
Keywords: AI; ML; digitalization; healthcare; performance metrics.
© 2024 The Author(s). Journal of Experimental Orthopaedics published by John Wiley & Sons Ltd on behalf of European Society of Sports Traumatology, Knee Surgery and Arthroscopy.
Conflict of interest statement
The authors declare no conflict of interest.
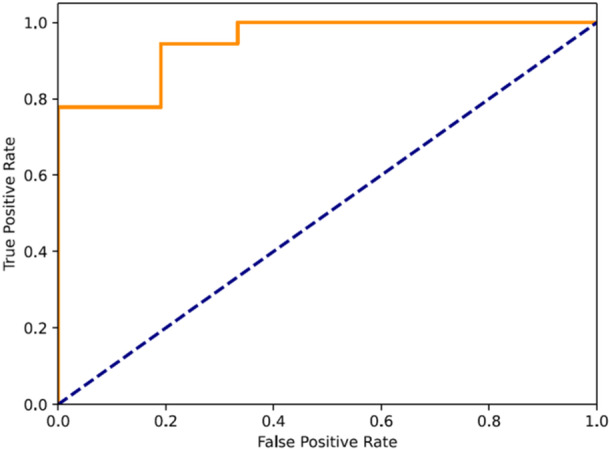
Figures
References
-
- Abdar, M. , Pourpanah, F. , Hussain, S. , Rezazadegan, D. , Liu, L. , Ghavamzadeh, M. et al. (2021) A review of uncertainty quantification in deep learning: techniques, applications and challenges. Information Fusion, 76, 243–297. Available from: 10.1016/j.inffus.2021.05.008 - DOI
-
- Box, G.E.P. (1976) Science and statistics. Journal of the American Statistical Association, 71, 791–799. Available from: 10.1080/01621459.1976.10480949 - DOI
-
- Chen, A. , Stanovsky, G. , Singh, S. & Gardner, M. (2019) Evaluating question answering evaluation. Proceedings of the 2nd Workshop on Machine Reading for Question Answering, 1 January 2019. Hong Kong, China: Association for Computational Linguistics, pp. 119–124. Available from: 10.18653/v1/D19-5817 - DOI
Publication types
LinkOut - more resources
Full Text Sources
Research Materials
