

DREAMER: a computational framework to evaluate readiness of datasets for machine learning
- PMID: 38831432
- PMCID: PMC11149315
- DOI: 10.1186/s12911-024-02544-w
DREAMER: a computational framework to evaluate readiness of datasets for machine learning
Abstract
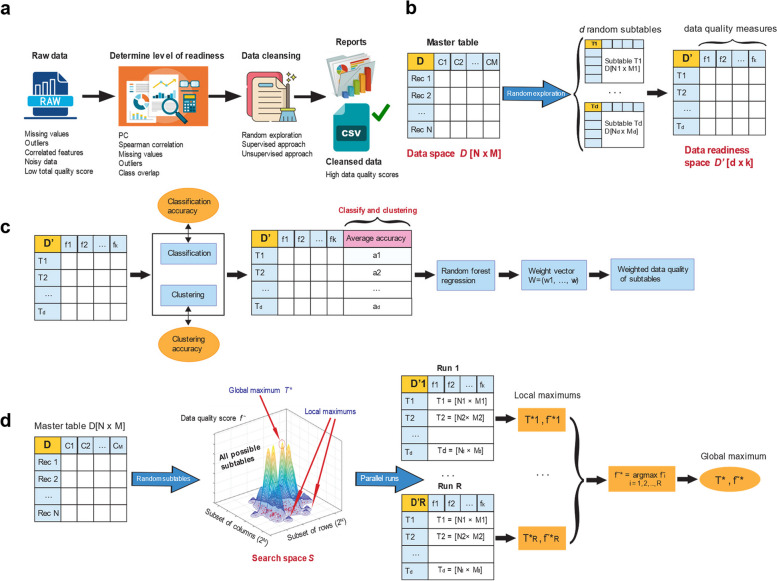
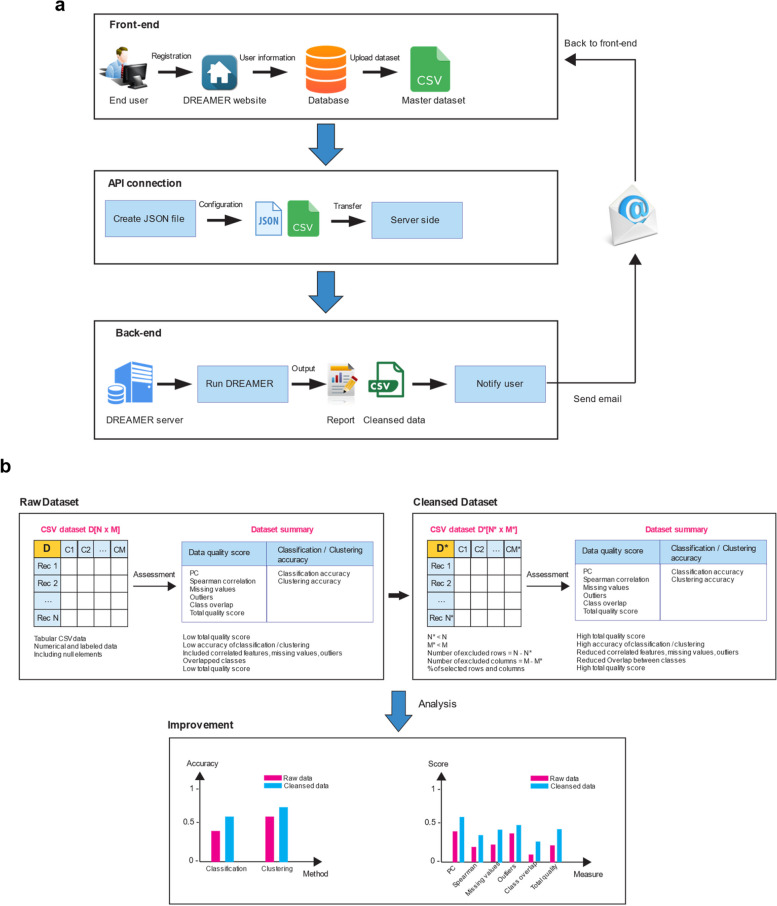
Background: Machine learning (ML) has emerged as the predominant computational paradigm for analyzing large-scale datasets across diverse domains. The assessment of dataset quality stands as a pivotal precursor to the successful deployment of ML models. In this study, we introduce DREAMER (Data REAdiness for MachinE learning Research), an algorithmic framework leveraging supervised and unsupervised machine learning techniques to autonomously evaluate the suitability of tabular datasets for ML model development. DREAMER is openly accessible as a tool on GitHub and Docker, facilitating its adoption and further refinement within the research community..
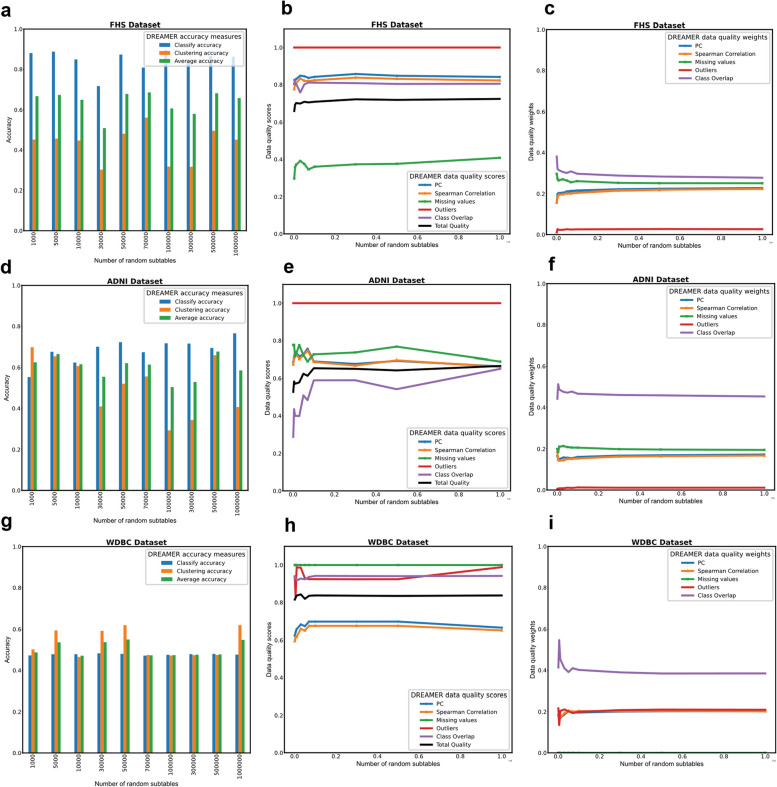
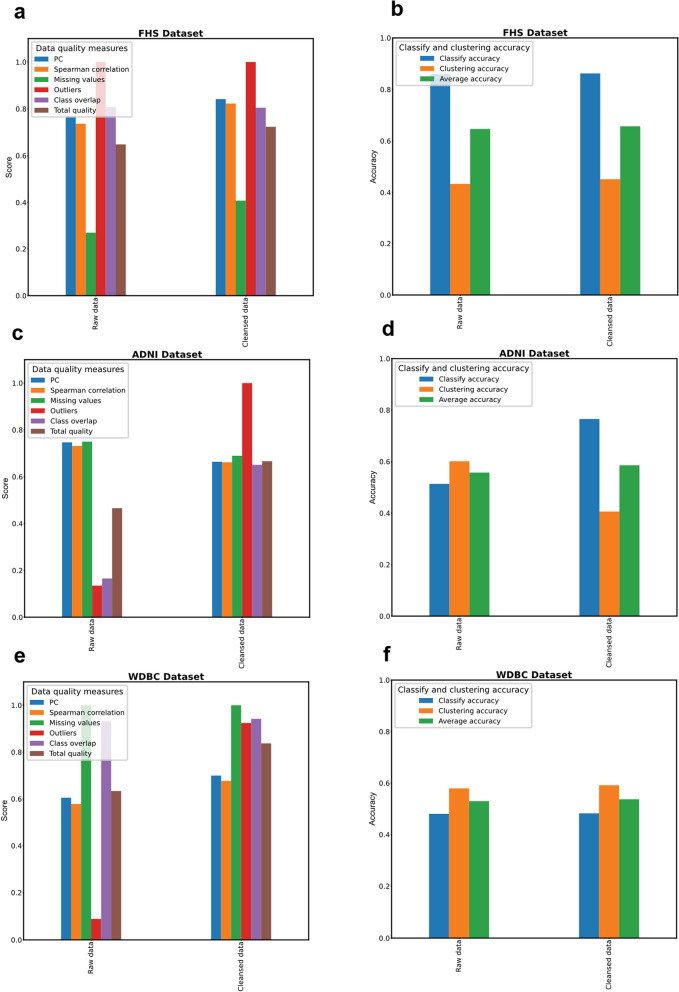
Results: The proposed model in this study was applied to three distinct tabular datasets, resulting in notable enhancements in their quality with respect to readiness for ML tasks, as assessed through established data quality metrics. Our findings demonstrate the efficacy of the framework in substantially augmenting the original dataset quality, achieved through the elimination of extraneous features and rows. This refinement yielded improved accuracy across both supervised and unsupervised learning methodologies.
Conclusion: Our software presents an automated framework for data readiness, aimed at enhancing the integrity of raw datasets to facilitate robust utilization within ML pipelines. Through our proposed framework, we streamline the original dataset, resulting in enhanced accuracy and efficiency within the associated ML algorithms.
Keywords: Data quality measure; Data readiness; Feature engineering; Machine learning.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures

References
-
- Lawrence ND. Data readiness levels. arXiv preprint arXiv:170502245. 2017.
-
- Austin CC. A path to big data readiness. In: 2018 IEEE International Conference on Big Data (Big Data). IEEE; 2018. pp. 4844–53.
-
- Barham H, Daim T. The use of readiness assessment for big data projects. Sustain Cities Soc. 2020;60:102233. doi: 10.1016/j.scs.2020.102233. - DOI
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
