

Comparative Analysis of Artificial Intelligence (AI) Languages in Predicting Sequential Organ Failure Assessment (SOFA) Scores
- PMID: 38836141
- PMCID: PMC11148682
- DOI: 10.7759/cureus.59662
Comparative Analysis of Artificial Intelligence (AI) Languages in Predicting Sequential Organ Failure Assessment (SOFA) Scores
Abstract
Purpose: The Sequential Organ Failure Assessment (SOFA) score plays a crucial role in intensive care units (ICUs) by providing a reliable measure of a patient's organ function or extent of failure. However, the precise assessment is time-consuming, and daily assessment in clinical practice in the ICU can be challenging.
Methods: Realistic scenarios in an ICU setting were created, and the data mining precision of ChatGPT 4.0 Plus, Bard, and Perplexity AI were assessed using Spearman's as well as the intraclass correlation coefficients regarding the accuracy in determining the SOFA score.
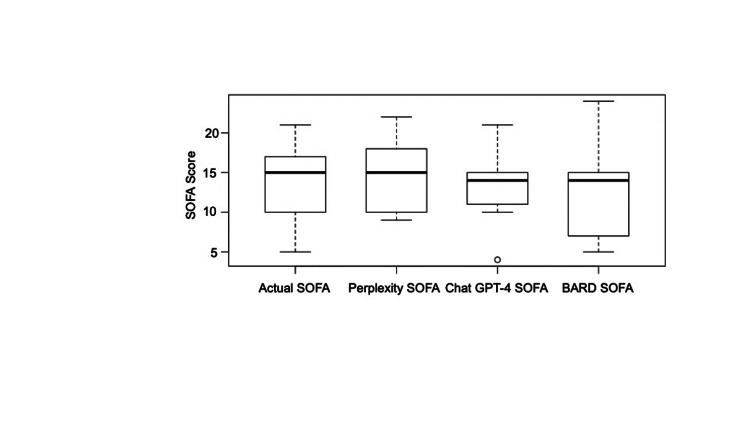
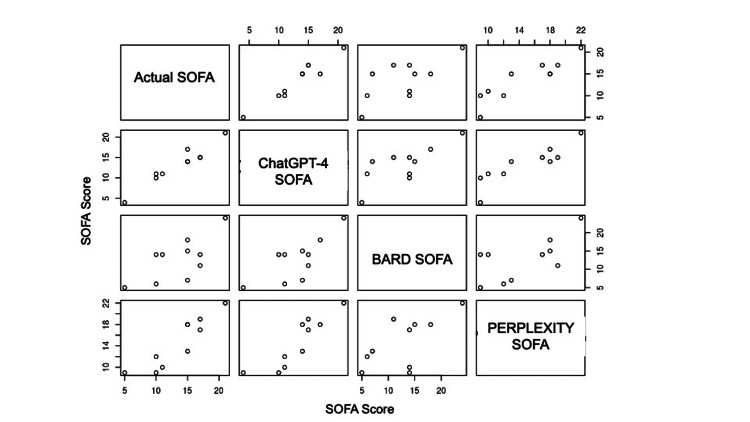
Results: The strongest correlation was observed between the actual SOFA score and the score calculated by ChatGPT 4.0 Plus (r correlation coefficient 0.92) (p<0.001). In contrast, the correlation between the actual SOFA and that calculated by Bard was moderate (r=0.59, p=0.070), while the correlation with Perplexity AI was substantial, at 0.89, with a p<0.001. The interclass correlation coefficient analysis of SOFA with those of ChatGPT 4.0 Plus, Bard, and Perplexity AI was ICC=0.94.
Conclusion: Artificial intelligence (AI) tools, particularly ChatGPT 4.0 Plus, show significant promise in assisting with automated SOFA score calculations via AI data mining in ICU settings. They offer a pathway to reduce the manual workload and increase the efficiency of continuous patient monitoring and assessment. However, further development and validation are necessary to ensure accuracy and reliability in a critical care environment.
Keywords: artificial intelligence; bard; chatgpt; large language models; perplexity; sofa score.
Copyright © 2024, Saner et al.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
Similar articles
-
Assessing the Accuracy of Information on Medication Abortion: A Comparative Analysis of ChatGPT and Google Bard AI.Cureus. 2024 Jan 2;16(1):e51544. doi: 10.7759/cureus.51544. eCollection 2024 Jan. Cureus. 2024. PMID: 38318564 Free PMC article.
-
A Comparative Analysis of AI Models in Complex Medical Decision-Making Scenarios: Evaluating ChatGPT, Claude AI, Bard, and Perplexity.Cureus. 2024 Jan 18;16(1):e52485. doi: 10.7759/cureus.52485. eCollection 2024 Jan. Cureus. 2024. PMID: 38371109 Free PMC article.
-
The development an artificial intelligence algorithm for early sepsis diagnosis in the intensive care unit.Int J Med Inform. 2020 Sep;141:104176. doi: 10.1016/j.ijmedinf.2020.104176. Epub 2020 May 21. Int J Med Inform. 2020. PMID: 32485555
-
Radiologic Decision-Making for Imaging in Pulmonary Embolism: Accuracy and Reliability of Large Language Models-Bing, Claude, ChatGPT, and Perplexity.Indian J Radiol Imaging. 2024 Jul 4;34(4):653-660. doi: 10.1055/s-0044-1787974. eCollection 2024 Oct. Indian J Radiol Imaging. 2024. PMID: 39318561 Free PMC article.
-
Comparative analysis of artificial intelligence chatbot recommendations for urolithiasis management: A study of EAU guideline compliance.Fr J Urol. 2024 Jul;34(7-8):102666. doi: 10.1016/j.fjurol.2024.102666. Epub 2024 Jun 5. Fr J Urol. 2024. PMID: 38849035
Cited by
-
The applications of ChatGPT and other large language models in anesthesiology and critical care: a systematic review.Can J Anaesth. 2025 Jun;72(6):904-922. doi: 10.1007/s12630-025-02973-9. Epub 2025 Jun 16. Can J Anaesth. 2025. PMID: 40524117 English.
-
Critical care studies using large language models based on electronic healthcare records: A technical note.J Intensive Med. 2024 Nov 12;5(2):137-150. doi: 10.1016/j.jointm.2024.09.002. eCollection 2025 Apr. J Intensive Med. 2024. PMID: 40241837 Free PMC article. Review.
References
-
- The SOFA (Sepsis-related Organ Failure Assessment) score to describe organ dysfunction/failure. On behalf of the Working Group on Sepsis-Related Problems of the European Society of Intensive Care Medicine. Vincent JL, Moreno R, Takala J, et al. Intensive Care Med. 1996;22:707–710. - PubMed
-
- Serial evaluation of the SOFA score to predict outcome in critically ill patients. Ferreira FL, Bota DP, Bross A, Mélot C, Vincent JL. JAMA. 2001;286:1754–1758. - PubMed
-
- Artificial intelligence in intensive care medicine. Mamdani M, Slutsky AS. Intensive Care Med. 2021;47:147–149. - PubMed
-
- Validation of prognostic accuracy of the SOFA score, SIRS criteria, and qSOFA score for in-hospital mortality among cardiac-, thoracic-, and vascular-surgery patients admitted to a cardiothoracic intensive care unit. Zhang Y, Luo H, Wang H, Zheng Z, Ooi OC. J Card Surg. 2020;35:118–127. - PubMed
LinkOut - more resources
Full Text Sources