

This is a preprint.
Prediction of neural activity in connectome-constrained recurrent networks
- PMID: 38854115
- PMCID: PMC11160579
- DOI: 10.1101/2024.02.22.581667
Prediction of neural activity in connectome-constrained recurrent networks
Abstract
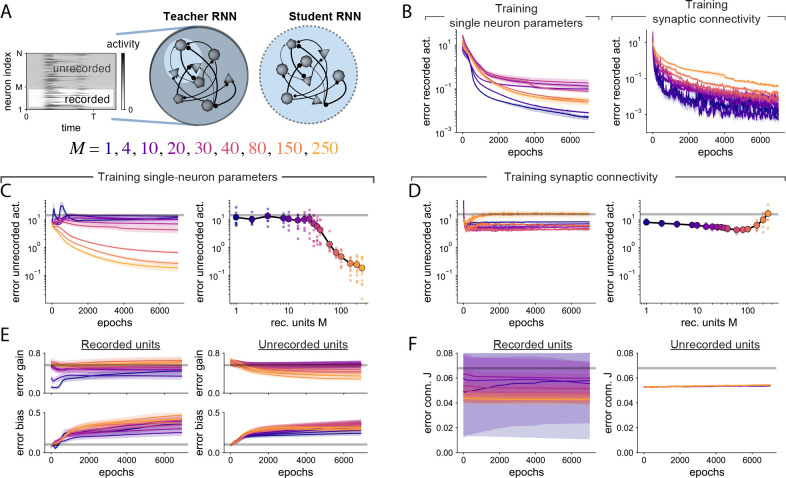
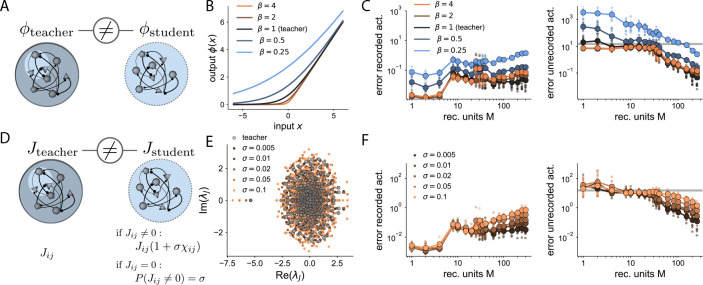
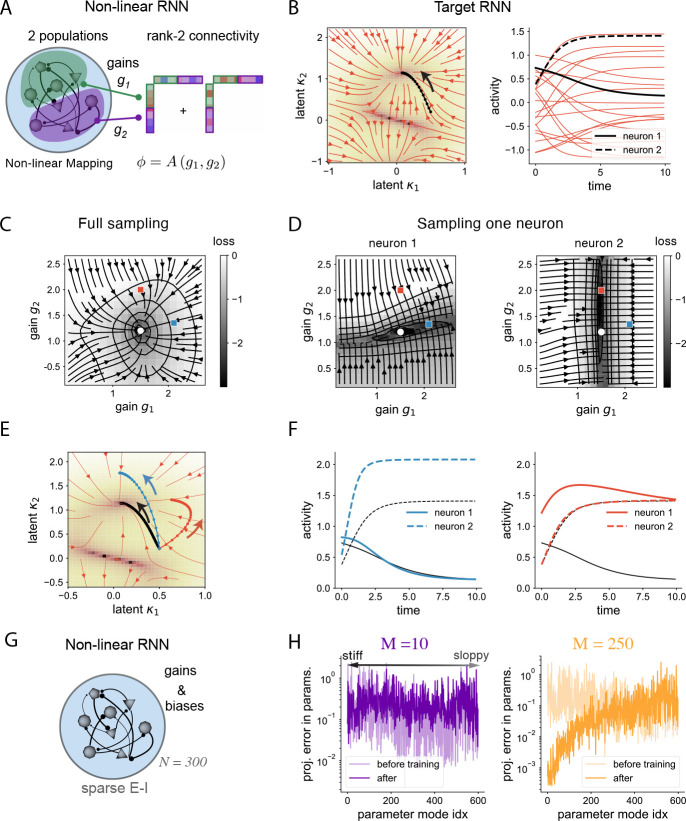
We develop a theory of connectome-constrained neural networks in which a "student" network is trained to reproduce the activity of a ground-truth "teacher," representing a neural system for which a connectome is available. Unlike standard paradigms with unconstrained connectivity, here the two networks have the same connectivity but different biophysical parameters, reflecting uncertainty in neuronal and synaptic properties. We find that a connectome is often insufficient to constrain the dynamics of networks that perform a specific task, illustrating the difficulty of inferring function from connectivity alone. However, recordings from a small subset of neurons can remove this degeneracy, producing dynamics in the student that agree with the teacher. Our theory can also prioritize which neurons to record from to most efficiently predict unmeasured network activity. Our analysis shows that the solution spaces of connectome-constrained and unconstrained models are qualitatively different and provides a framework to determine when such models yield consistent dynamics.
Figures




References
-
- Das A., Fiete I. R., Systematic errors in connectivity inferred from activity in strongly recurrent networks, Nature Neuroscience 2020 23:10 23 (10) (2020) 1286–1296. - PubMed
-
- Haber A., Schneidman E., Learning the Architectural Features That Predict Functional Similarity of Neural Networks (2022).
-
- Levina A., Priesemann V., Zierenberg J., Tackling the subsampling problem to infer collective properties from limited data, Nature Reviews Physics 2022 4:12 4 (12) (2022) 770–784.
-
- Liang T., Brinkman B. A. W., Statistically inferred neuronal connections in subsampled neural networks strongly correlate with spike train covariance, bioRxiv (2023) 2023.02.01.526673. - PubMed
-
- Dinc F., Shai A., Schnitzer M., Tanaka H., CORNN: Convex optimization of recurrent neural networks for rapid inference of neural dynamics (nov 2023). arXiv:2311.10200.
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources