

Cortical-striatal brain network distinguishes deepfake from real speaker identity
- PMID: 38862808
- PMCID: PMC11166919
- DOI: 10.1038/s42003-024-06372-6
Cortical-striatal brain network distinguishes deepfake from real speaker identity
Abstract
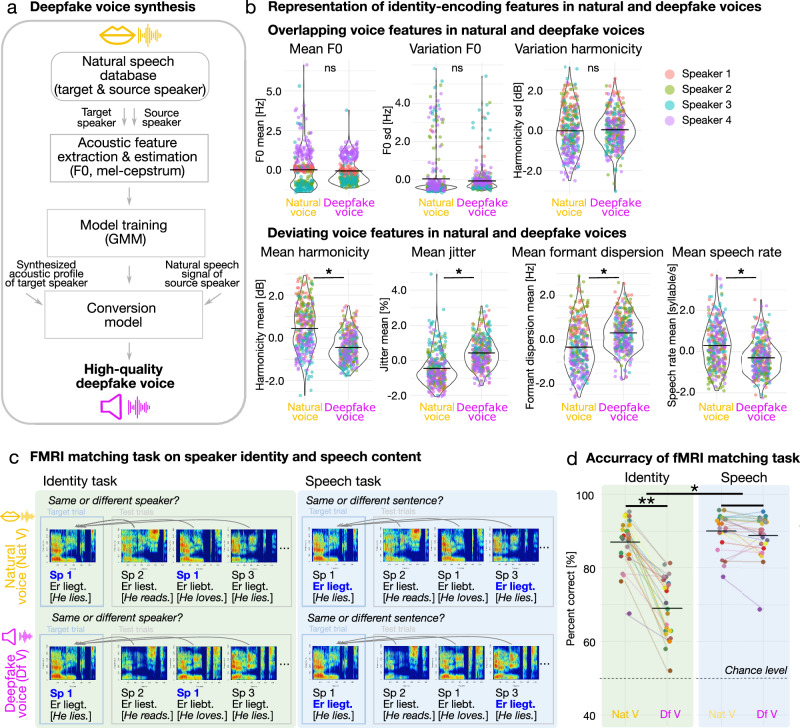
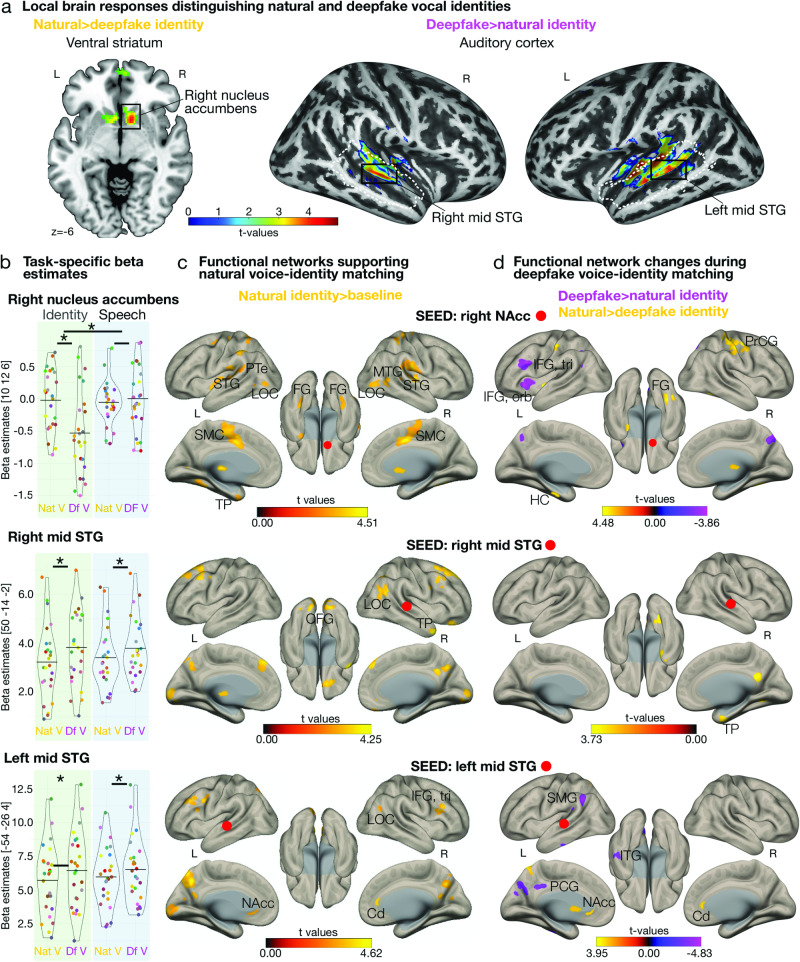
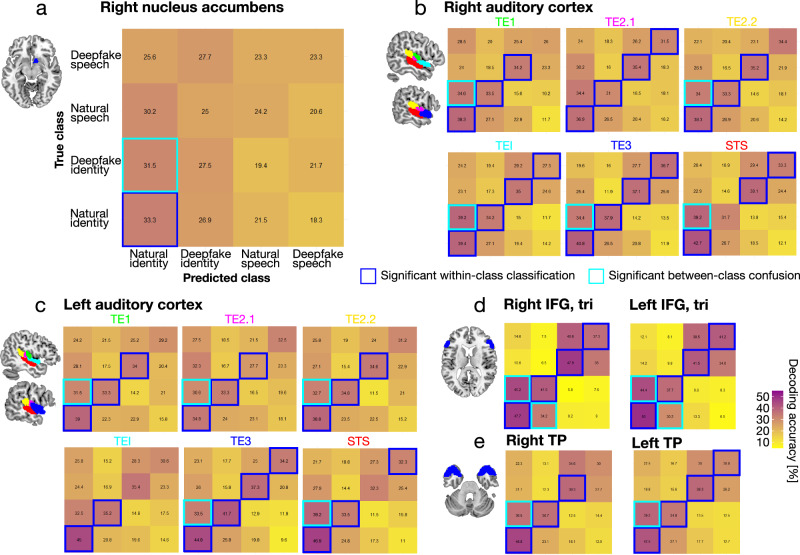
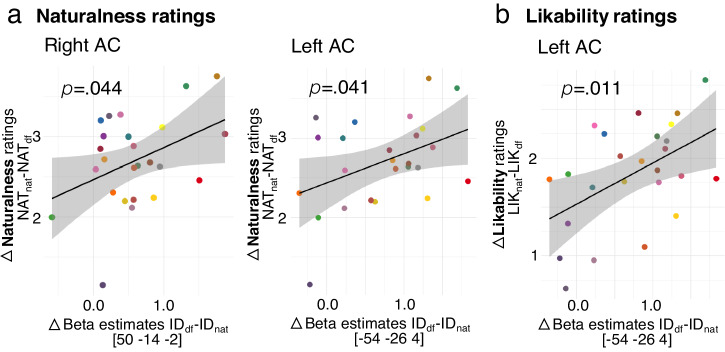
Deepfakes are viral ingredients of digital environments, and they can trick human cognition into misperceiving the fake as real. Here, we test the neurocognitive sensitivity of 25 participants to accept or reject person identities as recreated in audio deepfakes. We generate high-quality voice identity clones from natural speakers by using advanced deepfake technologies. During an identity matching task, participants show intermediate performance with deepfake voices, indicating levels of deception and resistance to deepfake identity spoofing. On the brain level, univariate and multivariate analyses consistently reveal a central cortico-striatal network that decoded the vocal acoustic pattern and deepfake-level (auditory cortex), as well as natural speaker identities (nucleus accumbens), which are valued for their social relevance. This network is embedded in a broader neural identity and object recognition network. Humans can thus be partly tricked by deepfakes, but the neurocognitive mechanisms identified during deepfake processing open windows for strengthening human resilience to fake information.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
Similar articles
-
Exploring the anatomical encoding of voice with a mathematical model of the vocal system.Neuroimage. 2016 Nov 1;141:31-39. doi: 10.1016/j.neuroimage.2016.07.033. Epub 2016 Jul 17. Neuroimage. 2016. PMID: 27436593
-
Deepfakes as a threat to a speaker and facial recognition: An overview of tools and attack vectors.Heliyon. 2023 Apr 3;9(4):e15090. doi: 10.1016/j.heliyon.2023.e15090. eCollection 2023 Apr. Heliyon. 2023. PMID: 37089334 Free PMC article. Review.
-
Task-dependent decoding of speaker and vowel identity from auditory cortical response patterns.J Neurosci. 2014 Mar 26;34(13):4548-57. doi: 10.1523/JNEUROSCI.4339-13.2014. J Neurosci. 2014. PMID: 24672000 Free PMC article.
-
Categorizing human vocal signals depends on an integrated auditory-frontal cortical network.Hum Brain Mapp. 2021 Apr 1;42(5):1503-1517. doi: 10.1002/hbm.25309. Epub 2020 Dec 8. Hum Brain Mapp. 2021. PMID: 33615612 Free PMC article.
-
A Review of Image Processing Techniques for Deepfakes.Sensors (Basel). 2022 Jun 16;22(12):4556. doi: 10.3390/s22124556. Sensors (Basel). 2022. PMID: 35746333 Free PMC article. Review.
Cited by
-
fNIRS experimental study on the impact of AI-synthesized familiar voices on brain neural responses.Sci Rep. 2025 May 15;15(1):16872. doi: 10.1038/s41598-025-92702-5. Sci Rep. 2025. PMID: 40374900 Free PMC article.
References
-
- Vaccari, C. & Chadwick, A. Deepfakes and Disinformation: Exploring the Impact of Synthetic Political Video on Deception, Uncertainty, and Trust in News. Soc. Media Soc. 6, 2056305120903408 (2020).
-
- Thies, J., Zollhofer, M., Stamminger, M., Theobalt, C. & Niebner, M. Face2Face: Real-Time Face Capture and Reenactment of RGB Videos. Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2387–2395 (2016).
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
