

Exome sequence analysis identifies rare coding variants associated with a machine learning-based marker for coronary artery disease
- PMID: 38862854
- PMCID: PMC11781350
- DOI: 10.1038/s41588-024-01791-x
Exome sequence analysis identifies rare coding variants associated with a machine learning-based marker for coronary artery disease
Abstract
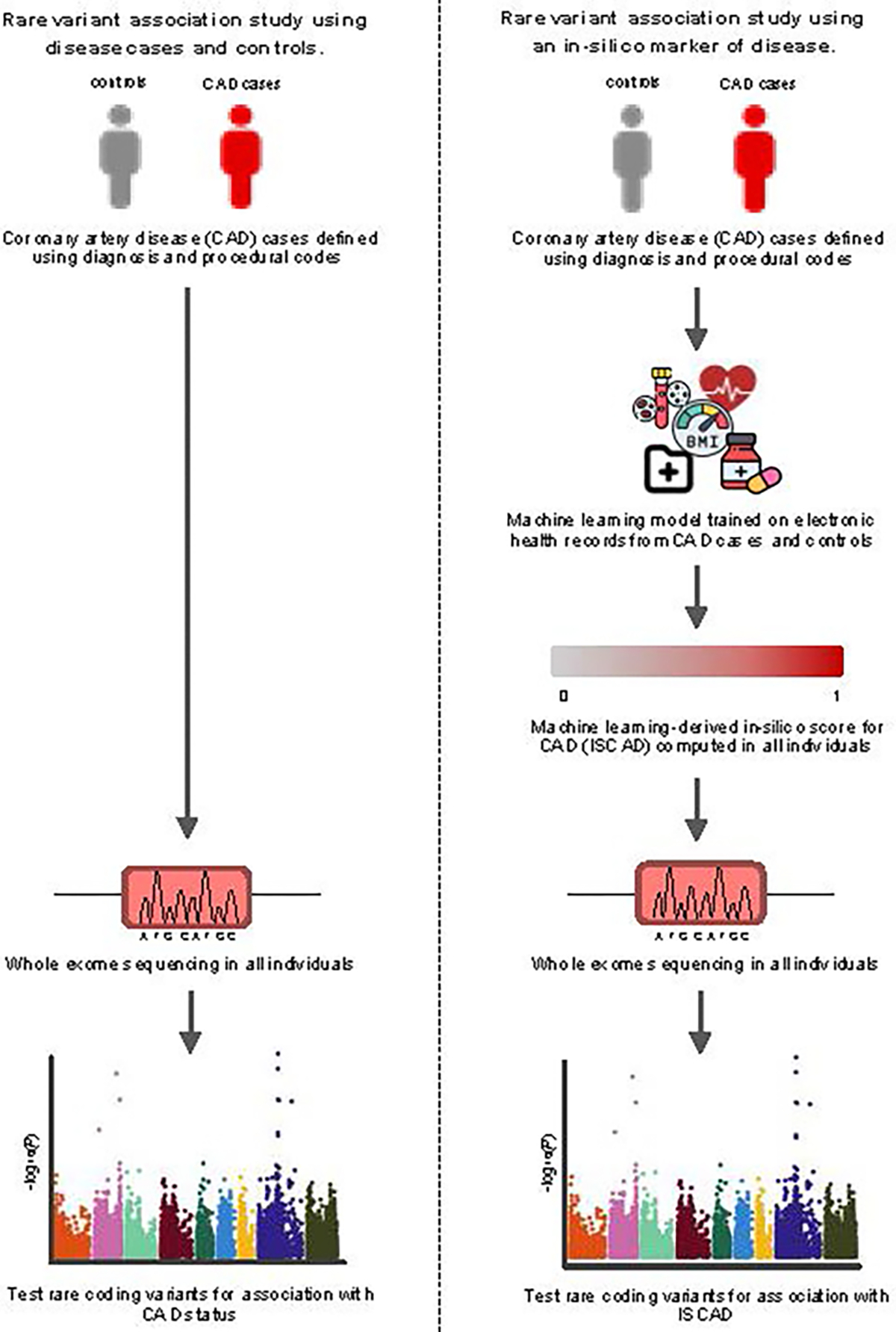
Coronary artery disease (CAD) exists on a spectrum of disease represented by a combination of risk factors and pathogenic processes. An in silico score for CAD built using machine learning and clinical data in electronic health records captures disease progression, severity and underdiagnosis on this spectrum and could enhance genetic discovery efforts for CAD. Here we tested associations of rare and ultrarare coding variants with the in silico score for CAD in the UK Biobank, All of Us Research Program and BioMe Biobank. We identified associations in 17 genes; of these, 14 show at least moderate levels of prior genetic, biological and/or clinical support for CAD. We also observed an excess of ultrarare coding variants in 321 aggregated CAD genes, suggesting more ultrarare variant associations await discovery. These results expand our understanding of the genetic etiology of CAD and illustrate how digital markers can enhance genetic association investigations for complex diseases.
© 2024. The Author(s), under exclusive licence to Springer Nature America, Inc.
Conflict of interest statement
R.D reports being a scientific co-founder, consultant and equity holder for Pensieve Health (pending), and being a consultant for Variant Bio, all not related to this study. R.S.R reports research funding to his institution from Amgen, Arrowhead, Eli Lilly, Merck, NIH, Novartis, Novo Nordisk, Regeneron, and 89Bio, consulting fees from Amgen, Avilar, CRISPER Therapeutics, Editas, Eli Lilly, Lipigon, New Amsterdam, Novartis, Precision Biosciences, Regeneron, UltraGenyx, Verve Therapeutics, non-promotional honoraria from Meda Pharma, royalties from Wolters Kluwer (UpToDate), and stock holding in MediMergent, LLC. He reports patent applications on: Methods and systems for biocellular marker detection and diagnosis using a microfluidic profiling device. EFS ID: 32278349. Application No. (PCT/US2019/026364) (provisional); all unrelated to this study. The remaining authors declare no competing interests.
Figures




References
-
- Chen Z & Schunkert H Genetics of coronary artery disease in the post-GWAS era. Journal of Internal Medicine 290, 980–992 (2021). - PubMed
Methods-only references
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Miscellaneous
