

Enhancing the diagnosis of functionally relevant coronary artery disease with machine learning
- PMID: 38866791
- PMCID: PMC11169272
- DOI: 10.1038/s41467-024-49390-y
Enhancing the diagnosis of functionally relevant coronary artery disease with machine learning
Abstract
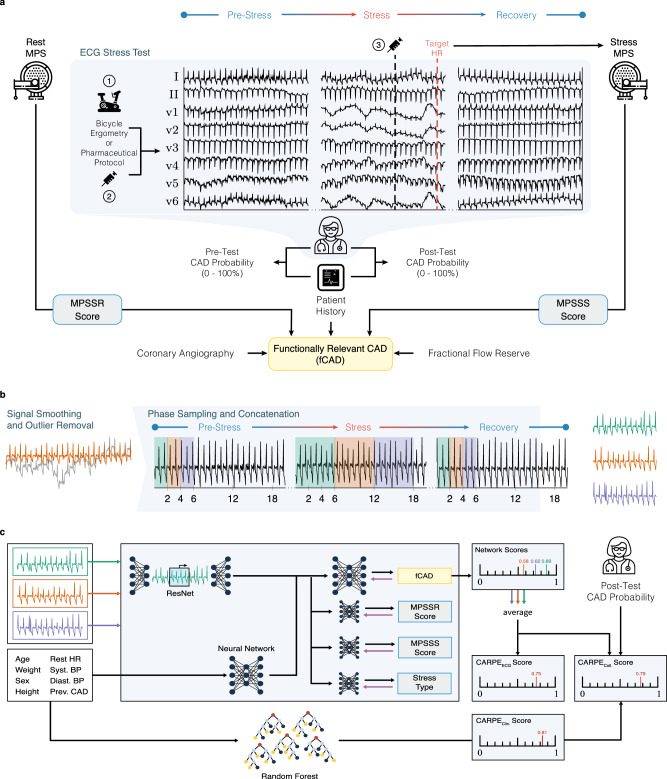
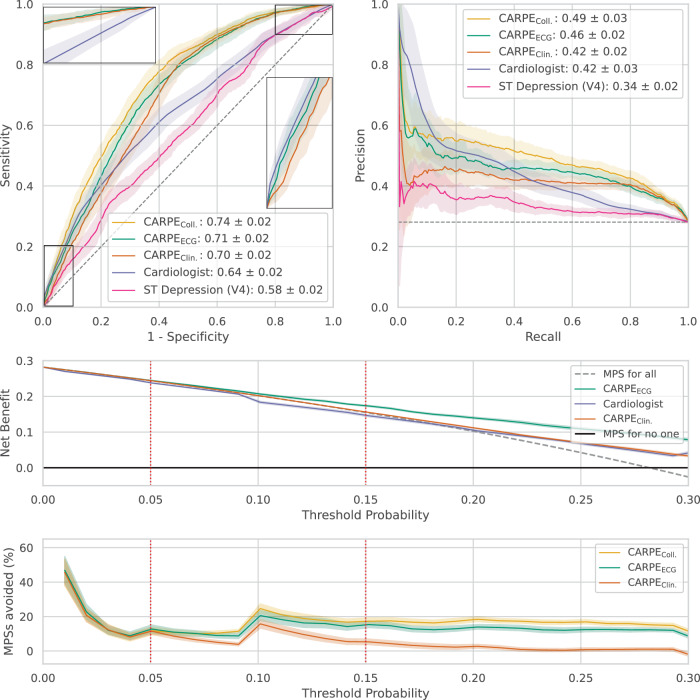
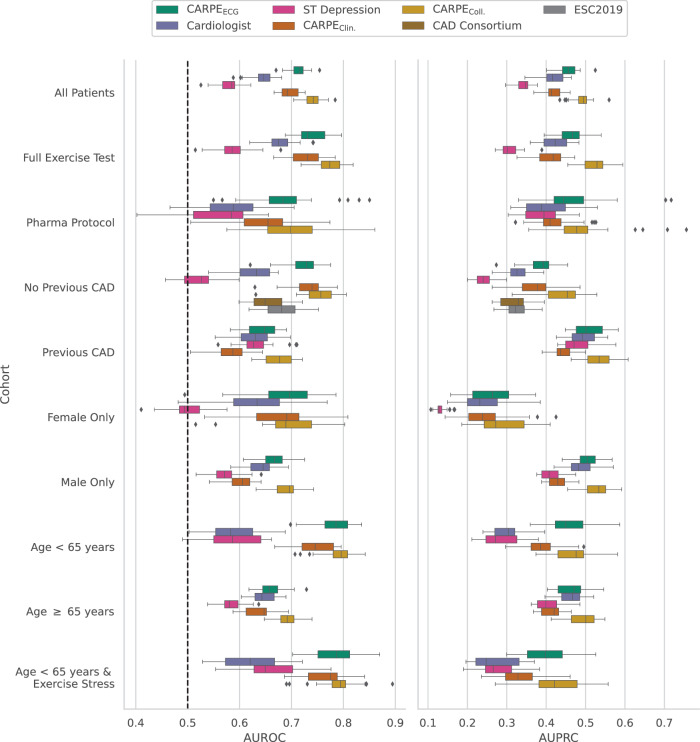
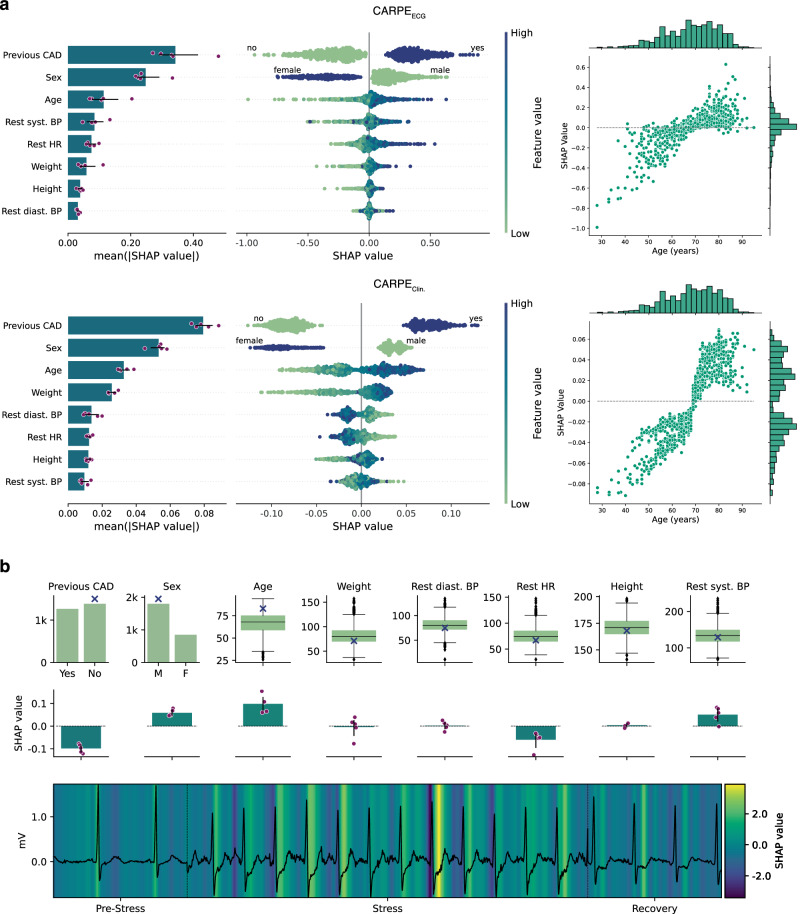
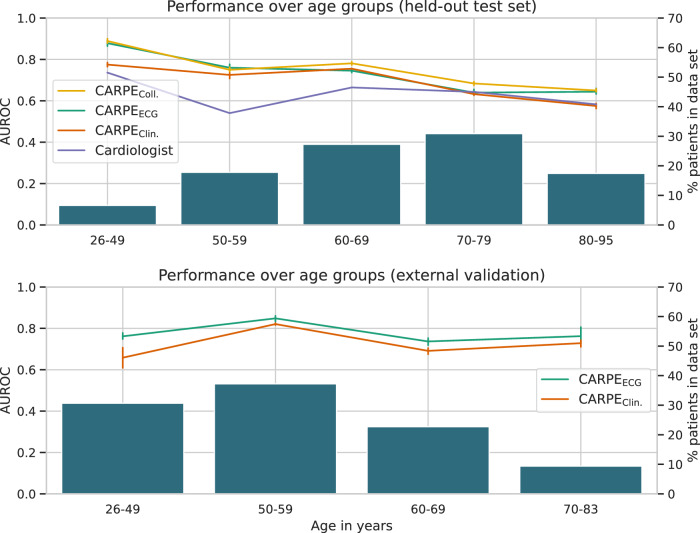
Functionally relevant coronary artery disease (fCAD) can result in premature death or nonfatal acute myocardial infarction. Its early detection is a fundamentally important task in medicine. Classical detection approaches suffer from limited diagnostic accuracy or expose patients to possibly harmful radiation. Here we show how machine learning (ML) can outperform cardiologists in predicting the presence of stress-induced fCAD in terms of area under the receiver operating characteristic (AUROC: 0.71 vs. 0.64, p = 4.0E-13). We present two ML approaches, the first using eight static clinical variables, whereas the second leverages electrocardiogram signals from exercise stress testing. At a target post-test probability for fCAD of <15%, ML facilitates a potential reduction of imaging procedures by 15-17% compared to the cardiologist's judgement. Predictive performance is validated on an internal temporal data split as well as externally. We also show that combining clinical judgement with conventional ML and deep learning using logistic regression results in a mean AUROC of 0.74.
© 2024. The Author(s).
Conflict of interest statement
J.E.W. has no conflict of interest to declare regarding this project and reports grants from Swiss Heart Foundation (FF19097 and F18111) and from the Swiss Academy Medical Sciences. C.M. has no conflict of interest to declare regarding this project and received research support from the Swiss National Science Foundation, the Swiss Heart Foundation, the KTI, the University of Basel, the University Hospital Basel, Abbott, Beckman Coulter, Brahms, Idorsia, Novartis, Ortho Clinical Diagnostics, Quidel, Roche, Siemens, Singulex, and Sphingotec as well as speaker honoraria/consulting honoraria from Amgen, AstraZeneca, Bayer, Beckman Coulter, Boehringer Ingelheim, BMS, Idorsia, Novartis, Osler, Roche, Sanofi, Siemens, and Singulex. The other authors declare no competing interests.
Figures
References
-
- Writing Group Members, et al. Heart disease and stroke statistics-2016 update: a report from the American Heart Association. Circulation. 2016;133:e38–e360. - PubMed
-
- GBD 2017 Disease and Injury Incidence and Prevalence Collaborators. Global, regional, and national incidence, prevalence, and years lived with disability for 354 diseases and injuries for 195 countries and territories, 1990–2017: a systematic analysis for the global burden of disease study 2017. Lancet392, 1789–1858 (2018). - PMC - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
