

Distinct brain morphometry patterns revealed by deep learning improve prediction of post-stroke aphasia severity
- PMID: 38866977
- PMCID: PMC11169346
- DOI: 10.1038/s43856-024-00541-8
Distinct brain morphometry patterns revealed by deep learning improve prediction of post-stroke aphasia severity
Abstract
Background: Emerging evidence suggests that post-stroke aphasia severity depends on the integrity of the brain beyond the lesion. While measures of lesion anatomy and brain integrity combine synergistically to explain aphasic symptoms, substantial interindividual variability remains unaccounted. One explanatory factor may be the spatial distribution of morphometry beyond the lesion (e.g., atrophy), including not just specific brain areas, but distinct three-dimensional patterns.
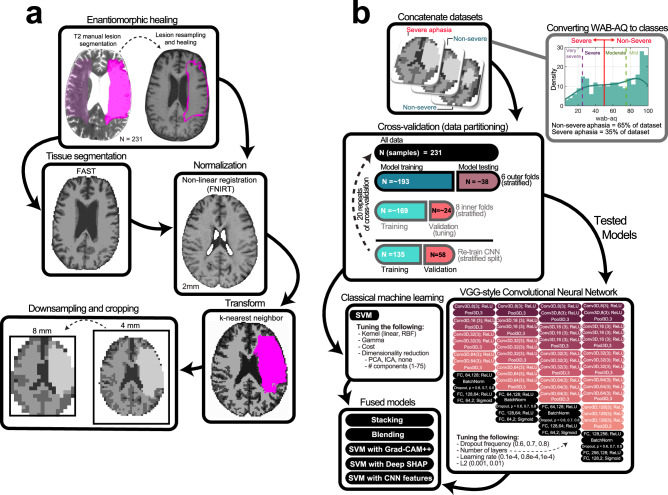
Methods: Here, we test whether deep learning with Convolutional Neural Networks (CNNs) on whole brain morphometry (i.e., segmented tissue volumes) and lesion anatomy better predicts chronic stroke individuals with severe aphasia (N = 231) than classical machine learning (Support Vector Machines; SVMs), evaluating whether encoding spatial dependencies identifies uniquely predictive patterns.
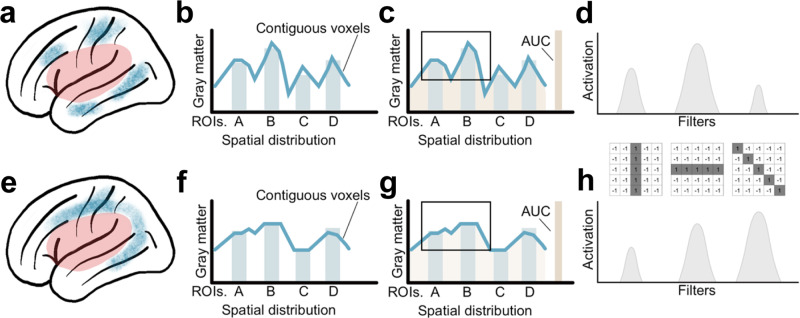
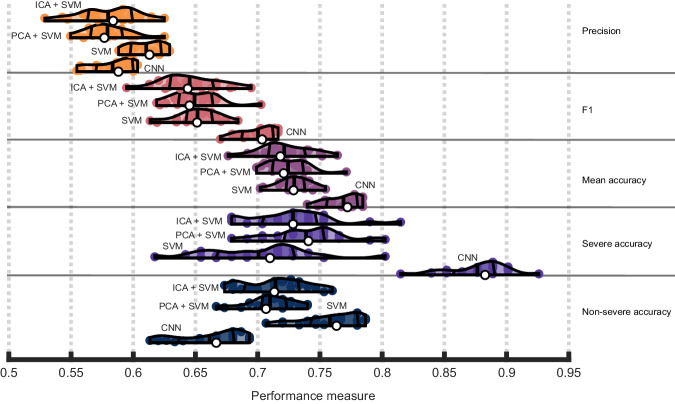
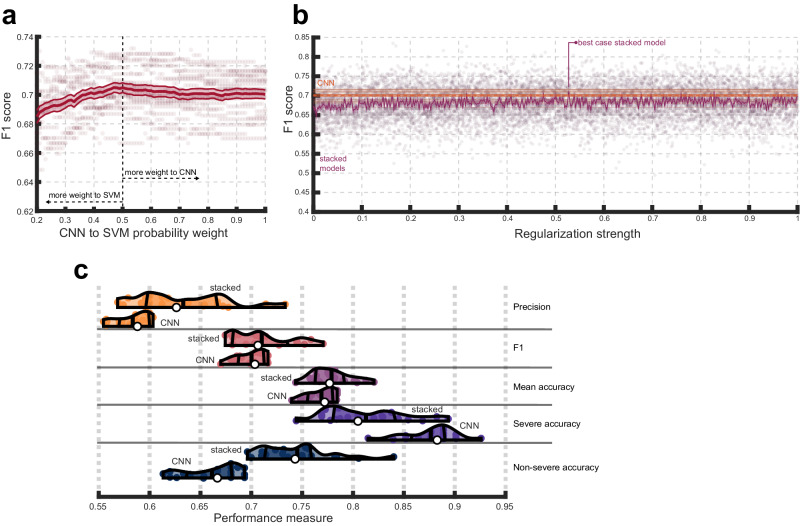
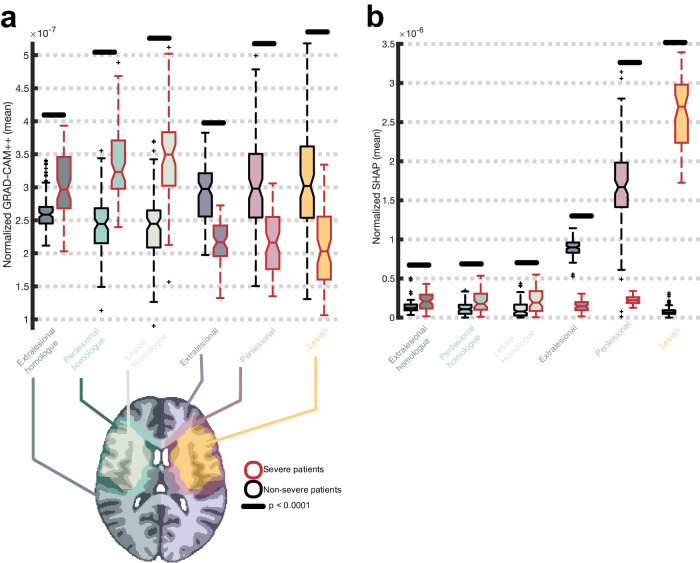
Results: CNNs achieve higher balanced accuracy and F1 scores, even when SVMs are nonlinear or integrate linear or nonlinear dimensionality reduction. Parity only occurs when SVMs access features learned by CNNs. Saliency maps demonstrate that CNNs leverage distributed morphometry patterns, whereas SVMs focus on the area around the lesion. Ensemble clustering of CNN saliencies reveals distinct morphometry patterns unrelated to lesion size, consistent across individuals, and which implicate unique networks associated with different cognitive processes as measured by the wider neuroimaging literature. Individualized predictions depend on both ipsilateral and contralateral features outside the lesion.
Conclusions: Three-dimensional network distributions of morphometry are directly associated with aphasia severity, underscoring the potential for CNNs to improve outcome prognostication from neuroimaging data, and highlighting the prospective benefits of interrogating spatial dependence at different scales in multivariate feature space.
Plain language summary
Some stroke survivors experience difficulties understanding and producing language. We performed brain imaging to capture information about brain structure in stroke survivors and used it to predict which survivors have more severe language problems. We found that a type of artificial intelligence (AI) specifically designed to find patterns in spatial data was more accurate at this task than more traditional methods. AI found more complex patterns of brain structure that distinguish stroke survivors with severe language problems by analyzing the brain’s spatial properties. Our findings demonstrate that AI tools can provide new information about brain structure and function following stroke. With further developments, these models may be able to help clinicians understand the extent to which language problems can be improved after a stroke.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures





Update of
-
Distinct brain morphometry patterns revealed by deep learning improve prediction of aphasia severity.Res Sq [Preprint]. 2023 Jul 3:rs.3.rs-3126126. doi: 10.21203/rs.3.rs-3126126/v1. Res Sq. 2023. Update in: Commun Med (Lond). 2024 Jun 12;4(1):115. doi: 10.1038/s43856-024-00541-8. PMID: 37461696 Free PMC article. Updated. Preprint.
Similar articles
-
Distinct brain morphometry patterns revealed by deep learning improve prediction of aphasia severity.Res Sq [Preprint]. 2023 Jul 3:rs.3.rs-3126126. doi: 10.21203/rs.3.rs-3126126/v1. Res Sq. 2023. Update in: Commun Med (Lond). 2024 Jun 12;4(1):115. doi: 10.1038/s43856-024-00541-8. PMID: 37461696 Free PMC article. Updated. Preprint.
-
Short-Term Memory Impairment.2024 Jun 8. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan–. 2024 Jun 8. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2025 Jan–. PMID: 31424720 Free Books & Documents.
-
Comparison of Two Modern Survival Prediction Tools, SORG-MLA and METSSS, in Patients With Symptomatic Long-bone Metastases Who Underwent Local Treatment With Surgery Followed by Radiotherapy and With Radiotherapy Alone.Clin Orthop Relat Res. 2024 Dec 1;482(12):2193-2208. doi: 10.1097/CORR.0000000000003185. Epub 2024 Jul 23. Clin Orthop Relat Res. 2024. PMID: 39051924
-
The Black Book of Psychotropic Dosing and Monitoring.Psychopharmacol Bull. 2024 Jul 8;54(3):8-59. Psychopharmacol Bull. 2024. PMID: 38993656 Free PMC article. Review.
-
Signs and symptoms to determine if a patient presenting in primary care or hospital outpatient settings has COVID-19.Cochrane Database Syst Rev. 2022 May 20;5(5):CD013665. doi: 10.1002/14651858.CD013665.pub3. Cochrane Database Syst Rev. 2022. PMID: 35593186 Free PMC article.
Cited by
-
Aphasia severity prediction using a multi-modal machine learning approach.Neuroimage. 2025 Aug 15;317:121300. doi: 10.1016/j.neuroimage.2025.121300. Epub 2025 Jun 17. Neuroimage. 2025. PMID: 40554033 Free PMC article.
-
Stable multivariate lesion symptom mapping.Apert Neuro. 2024;4:10.52294/001c.117311. doi: 10.52294/001c.117311. Epub 2024 Jun 7. Apert Neuro. 2024. PMID: 39364269 Free PMC article.
-
Precision-Optimised Post-Stroke Prognoses.Ann Clin Transl Neurol. 2025 Aug;12(8):1619-1627. doi: 10.1002/acn3.70077. Epub 2025 Jun 12. Ann Clin Transl Neurol. 2025. PMID: 40506865 Free PMC article.
References
Grants and funding
LinkOut - more resources
Full Text Sources
