

A cerebellar granule cell-climbing fiber computation to learn to track long time intervals
- PMID: 38870929
- PMCID: PMC11343686
- DOI: 10.1016/j.neuron.2024.05.019
A cerebellar granule cell-climbing fiber computation to learn to track long time intervals
Abstract
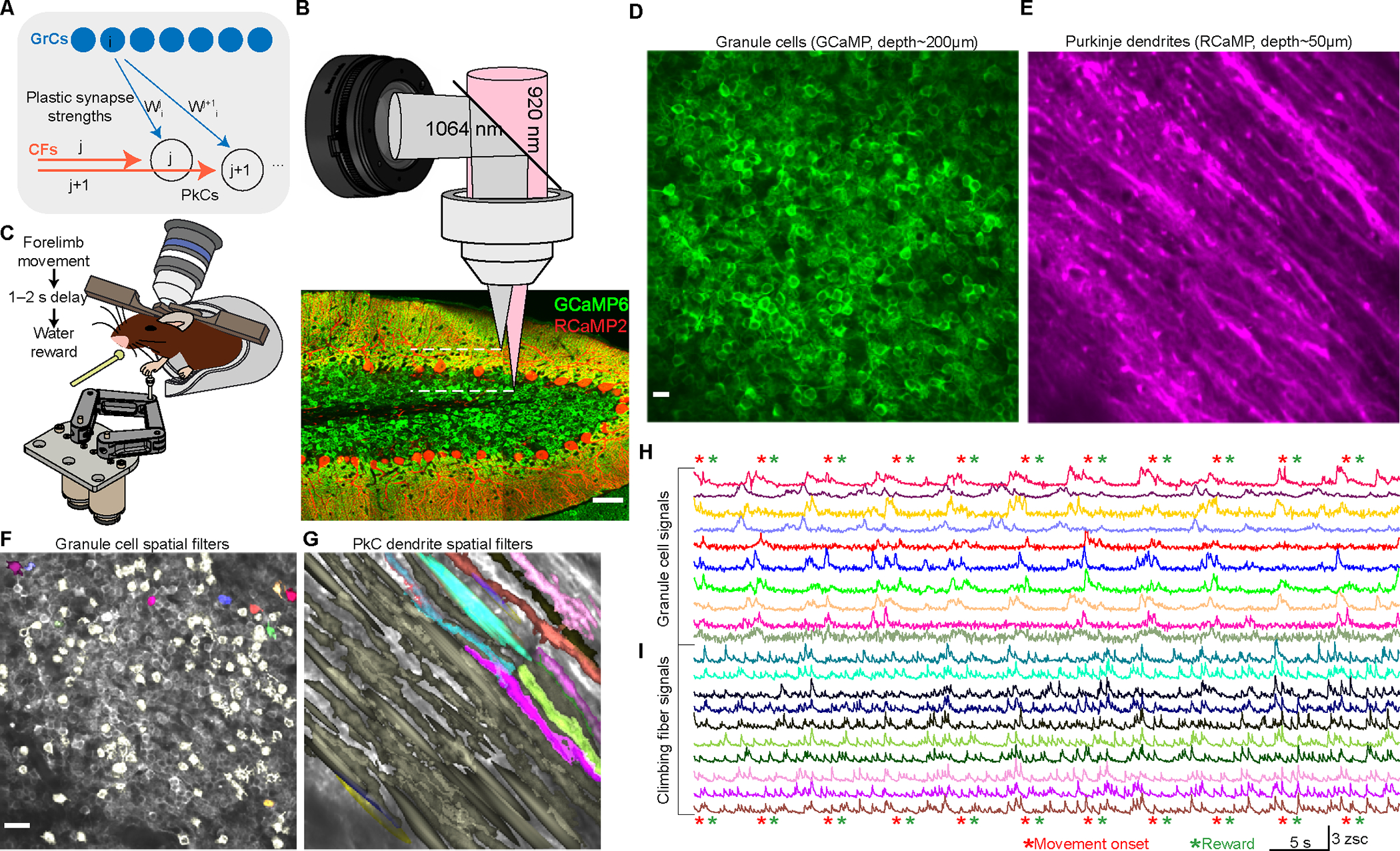
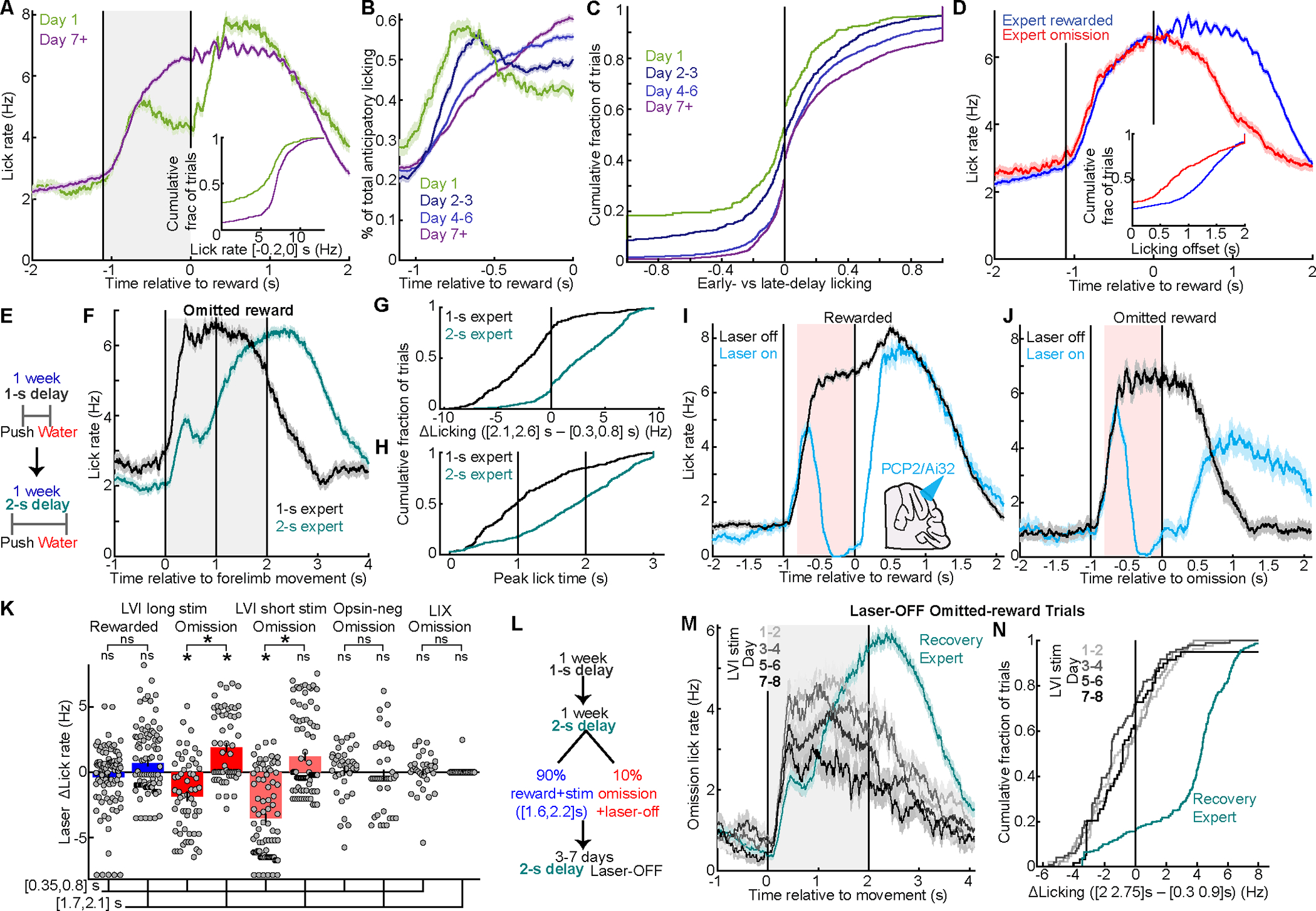
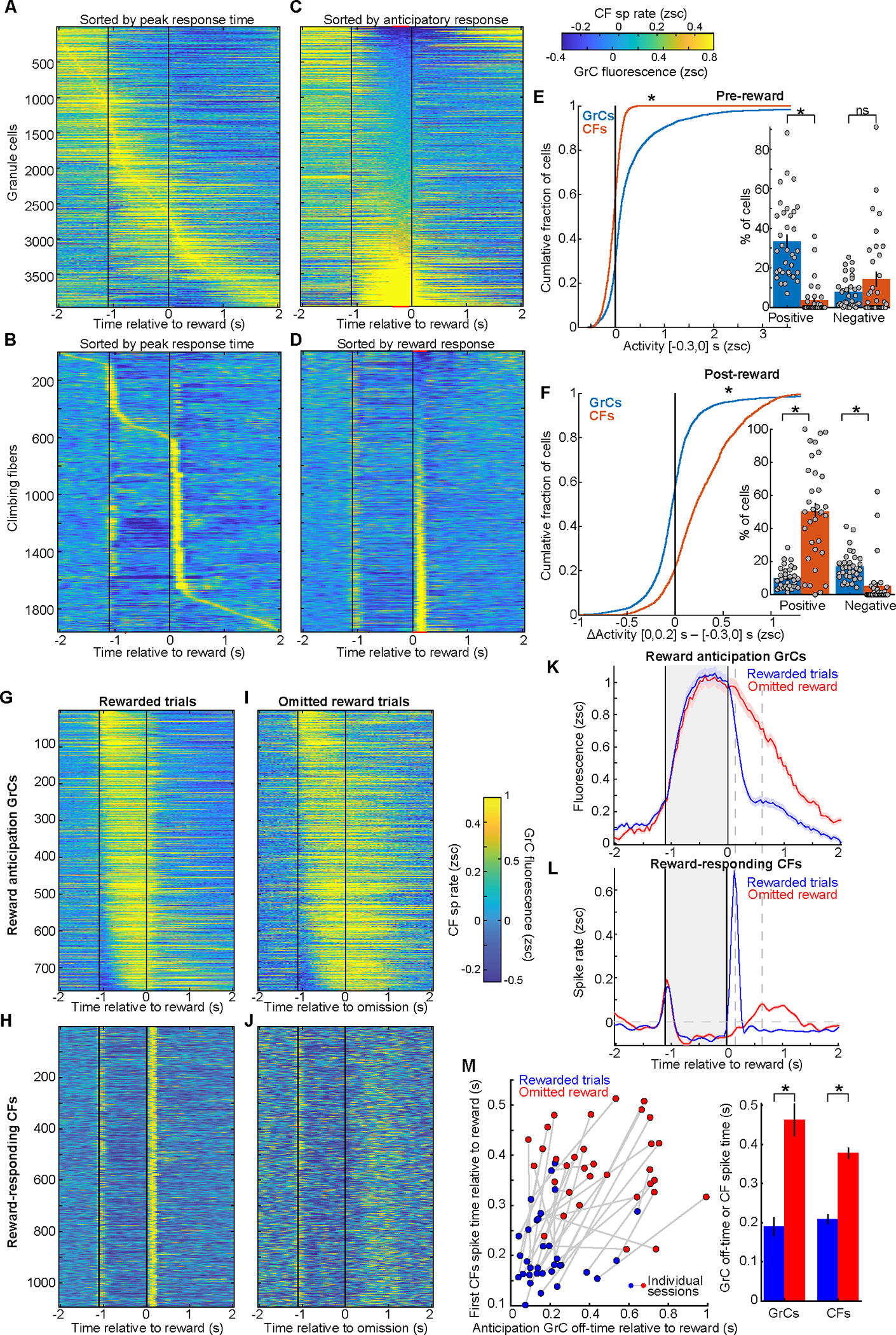
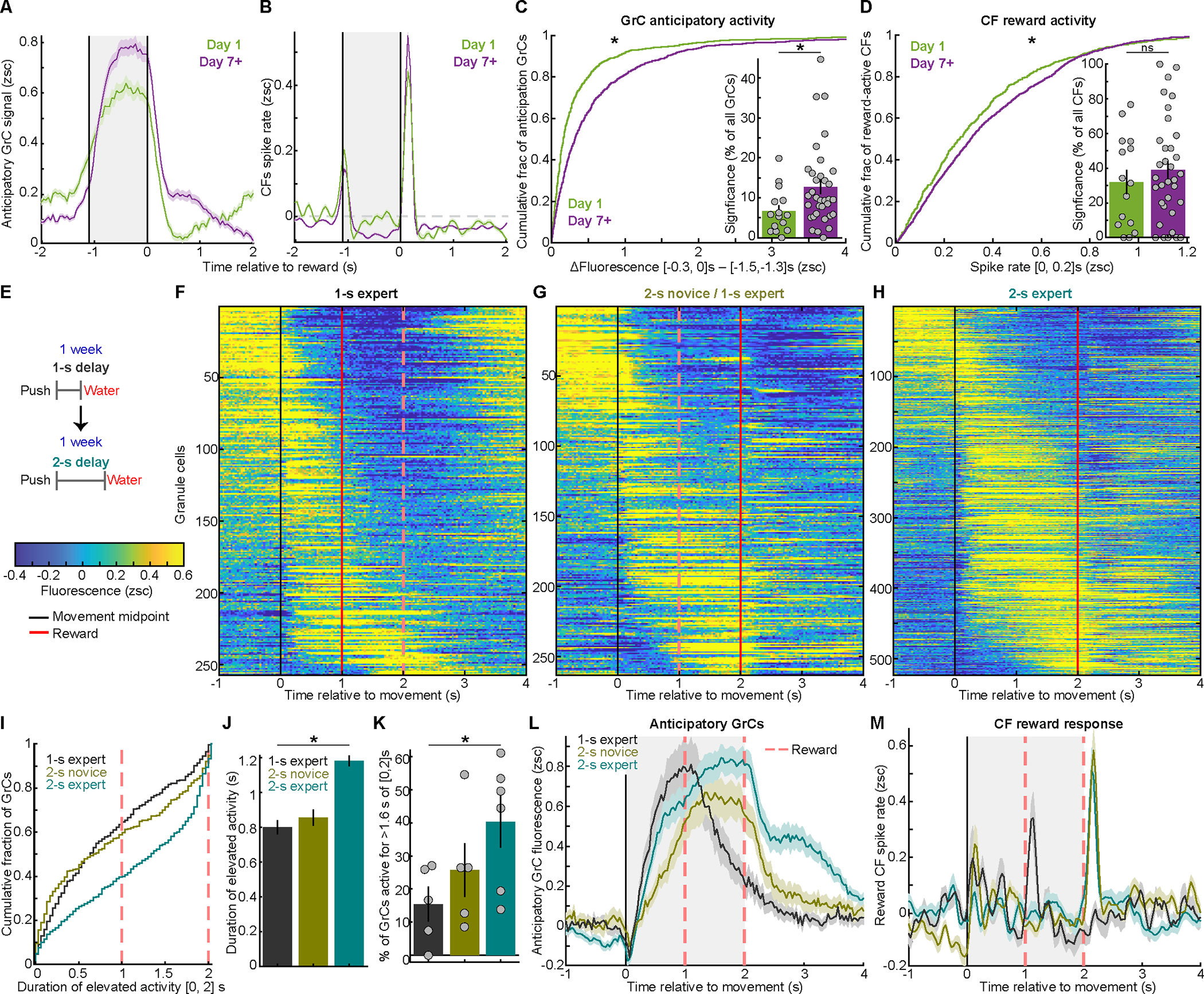
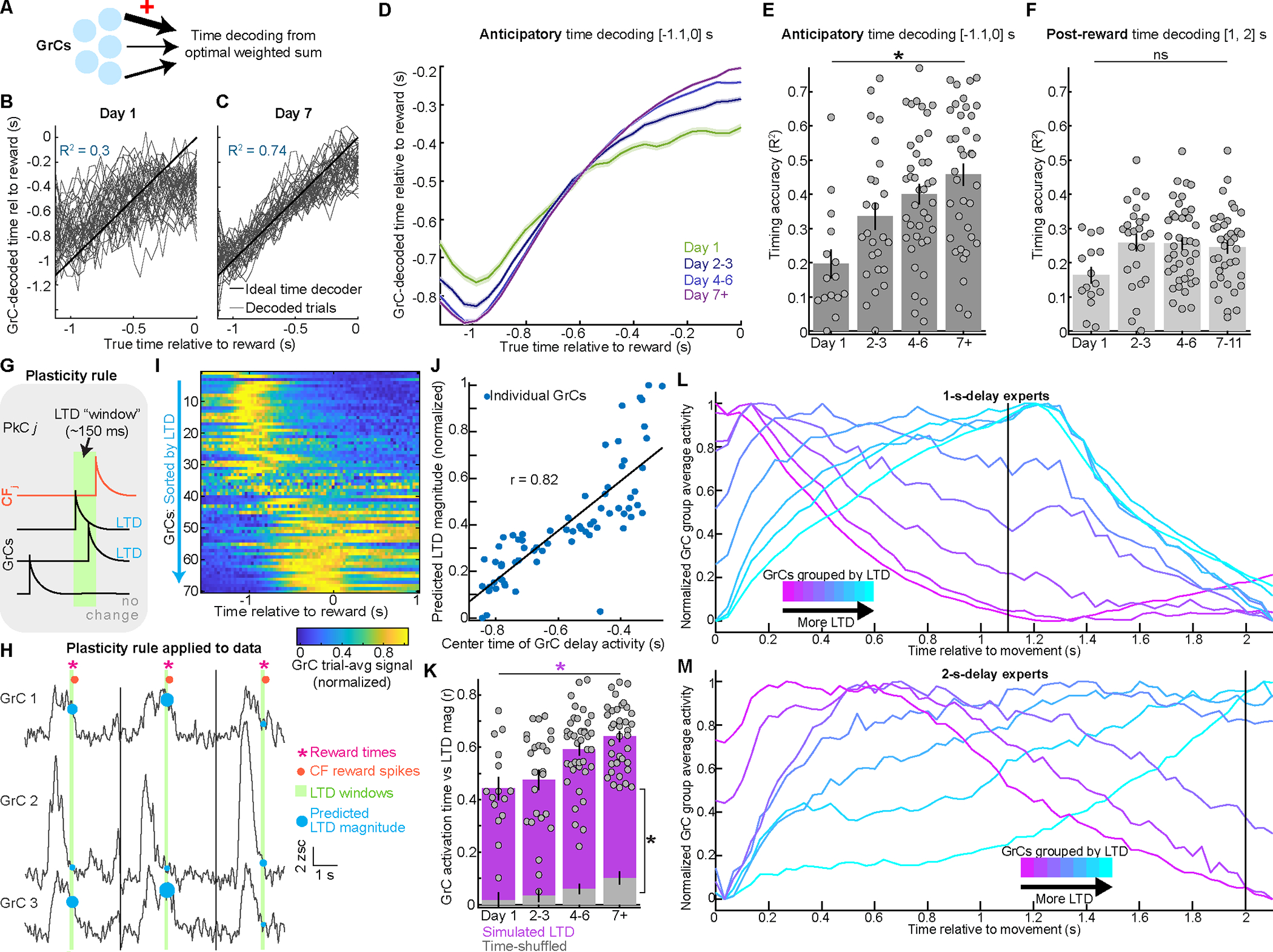
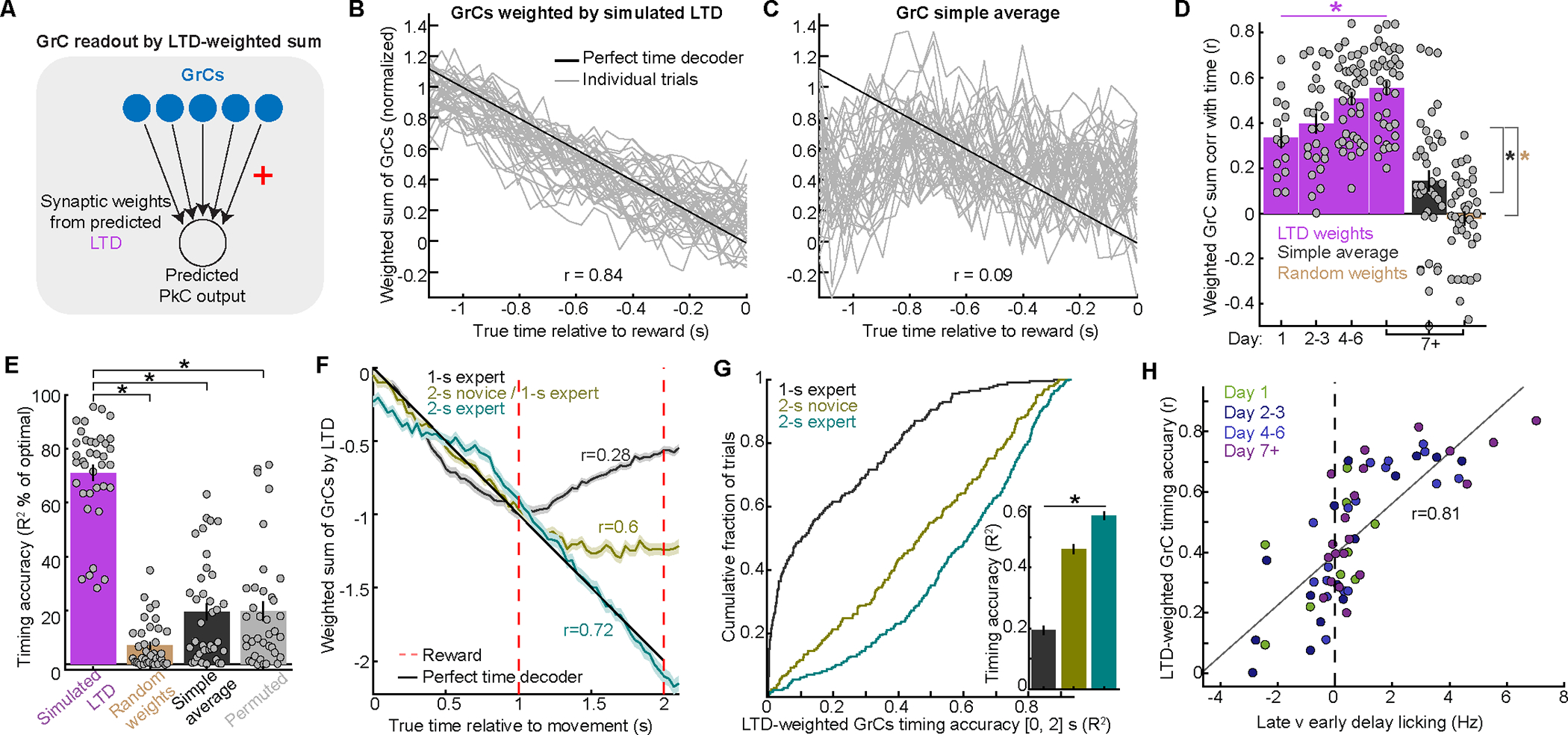
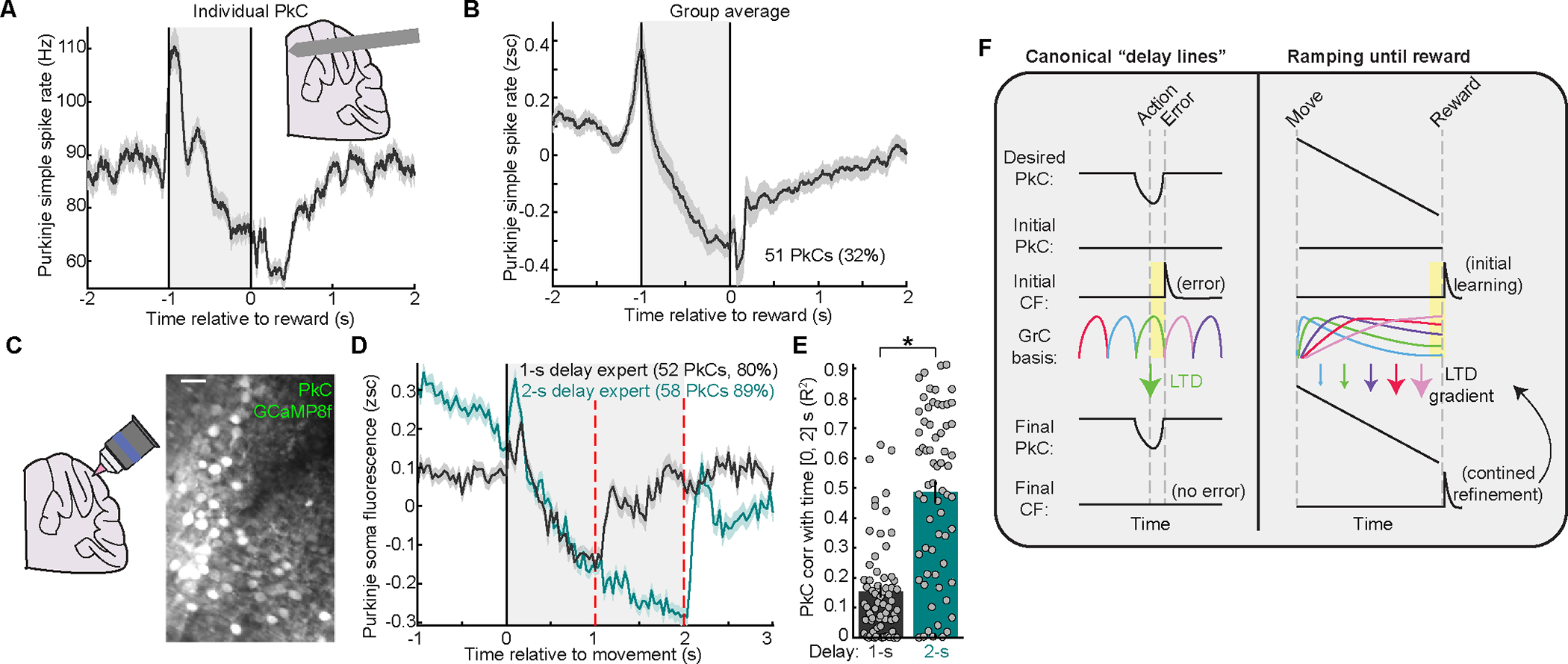
In classical cerebellar learning, Purkinje cells (PkCs) associate climbing fiber (CF) error signals with predictive granule cells (GrCs) that were active just prior (∼150 ms). The cerebellum also contributes to behaviors characterized by longer timescales. To investigate how GrC-CF-PkC circuits might learn seconds-long predictions, we imaged simultaneous GrC-CF activity over days of forelimb operant conditioning for delayed water reward. As mice learned reward timing, numerous GrCs developed anticipatory activity ramping at different rates until reward delivery, followed by widespread time-locked CF spiking. Relearning longer delays further lengthened GrC activations. We computed CF-dependent GrC→PkC plasticity rules, demonstrating that reward-evoked CF spikes sufficed to grade many GrC synapses by anticipatory timing. We predicted and confirmed that PkCs could thereby continuously ramp across seconds-long intervals from movement to reward. Learning thus leads to new GrC temporal bases linking predictors to remote CF reward signals-a strategy well suited for learning to track the long intervals common in cognitive domains.
Keywords: associative learning; cerebellum; climbing fibers; granule cells; neural ramping; operant conditioning; reward learning; temporal encoding; temporal learning; two-photon imaging.
Published by Elsevier Inc.
Conflict of interest statement
Declaration of interests The authors declare no competing interests.
Figures
Similar articles
-
Cerebellar granule cells encode the expectation of reward.Nature. 2017 Apr 6;544(7648):96-100. doi: 10.1038/nature21726. Epub 2017 Mar 20. Nature. 2017. PMID: 28321129 Free PMC article.
-
Climbing fibers encode a temporal-difference prediction error during cerebellar learning in mice.Nat Neurosci. 2015 Dec;18(12):1798-803. doi: 10.1038/nn.4167. Epub 2015 Nov 9. Nat Neurosci. 2015. PMID: 26551541 Free PMC article.
-
The Origin of Physiological Local mGluR1 Supralinear Ca2+ Signals in Cerebellar Purkinje Neurons.J Neurosci. 2020 Feb 26;40(9):1795-1809. doi: 10.1523/JNEUROSCI.2406-19.2020. Epub 2020 Jan 22. J Neurosci. 2020. PMID: 31969470 Free PMC article.
-
Climbing fibers mediate vestibular modulation of both "complex" and "simple spikes" in Purkinje cells.Cerebellum. 2015 Oct;14(5):597-612. doi: 10.1007/s12311-015-0725-1. Cerebellum. 2015. PMID: 26424151 Review.
-
Activity-dependent plasticity of developing climbing fiber-Purkinje cell synapses.Neuroscience. 2009 Sep 1;162(3):612-23. doi: 10.1016/j.neuroscience.2009.01.032. Epub 2009 Jan 23. Neuroscience. 2009. PMID: 19302832 Review.
Cited by
-
Hippocampal sequences represent working memory and implicit timing.bioRxiv [Preprint]. 2025 Mar 17:2025.03.17.643736. doi: 10.1101/2025.03.17.643736. bioRxiv. 2025. PMID: 40166270 Free PMC article. Preprint.
-
Learning temporal relationships between symbols with Laplace Neural Manifolds.ArXiv [Preprint]. 2024 Sep 22:arXiv:2302.10163v4. ArXiv. 2024. PMID: 36866224 Free PMC article. Preprint.
-
Social and emotional learning in the cerebellum.Nat Rev Neurosci. 2024 Dec;25(12):776-791. doi: 10.1038/s41583-024-00871-5. Epub 2024 Oct 21. Nat Rev Neurosci. 2024. PMID: 39433716 Review.
-
A Preprocessing Toolbox for 2-Photon Subcellular Calcium Imaging.eNeuro. 2025 May 29;12(5):ENEURO.0565-24.2025. doi: 10.1523/ENEURO.0565-24.2025. Print 2025 May. eNeuro. 2025. PMID: 40360280 Free PMC article.
-
Processing reliant on granule cells is essential for motor learning but dispensable for social preference and numerous other cerebellar-dependent behaviors.Nat Commun. 2025 Jul 2;16(1):6101. doi: 10.1038/s41467-025-61190-6. Nat Commun. 2025. PMID: 40603888 Free PMC article.
References
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
Research Materials
