

AITeQ: a machine learning framework for Alzheimer's prediction using a distinctive five-gene signature
- PMID: 38877887
- PMCID: PMC11179120
- DOI: 10.1093/bib/bbae291
AITeQ: a machine learning framework for Alzheimer's prediction using a distinctive five-gene signature
Abstract
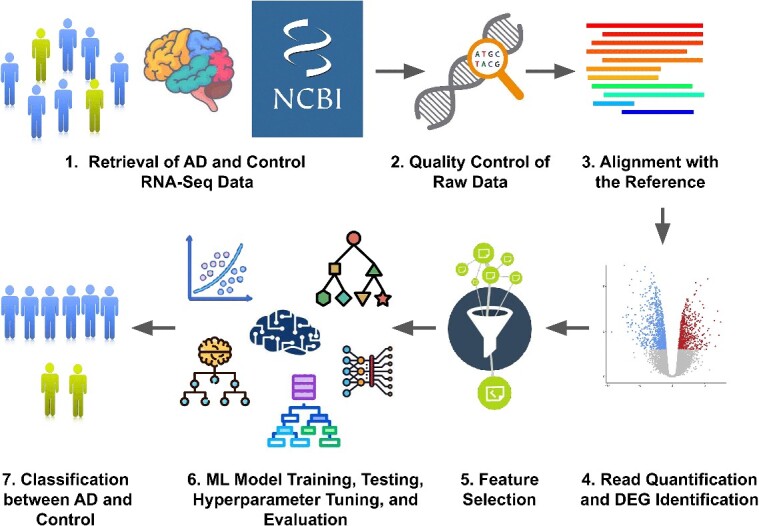
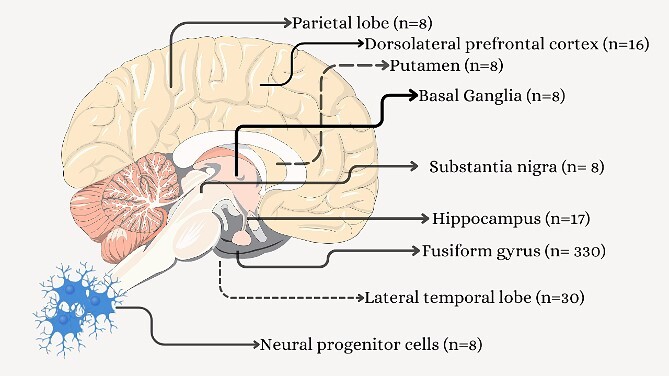
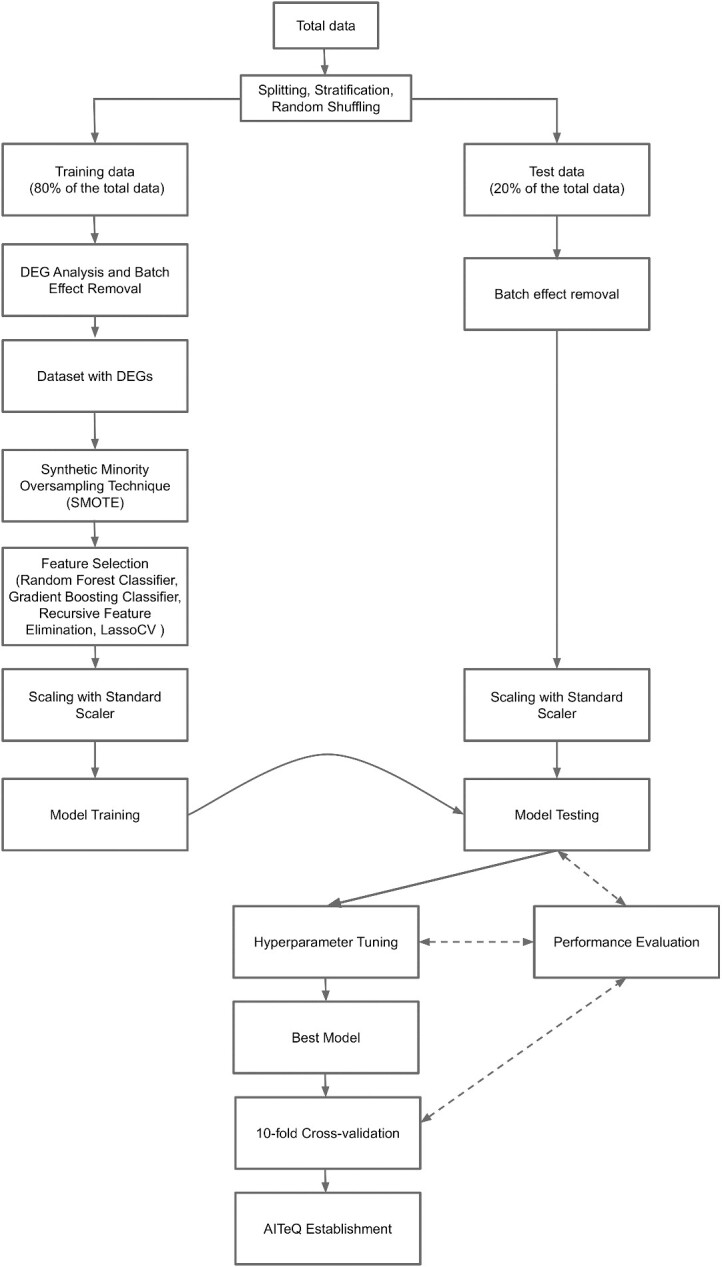
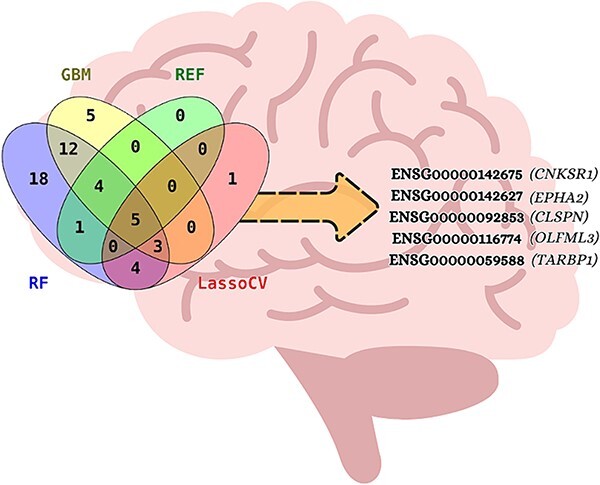
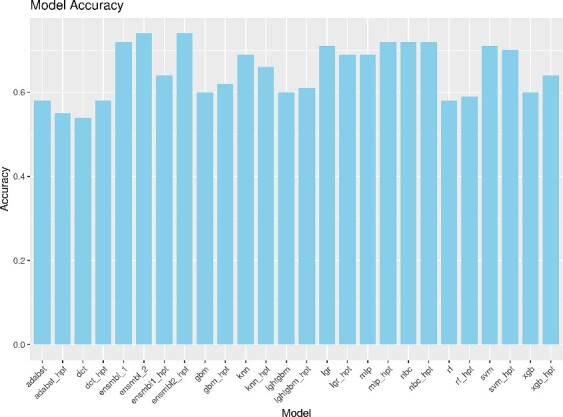
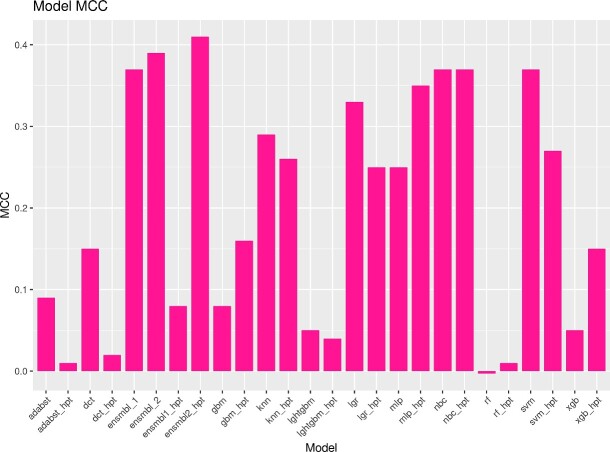
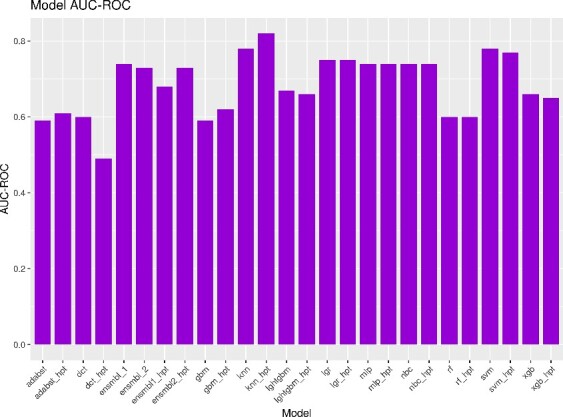
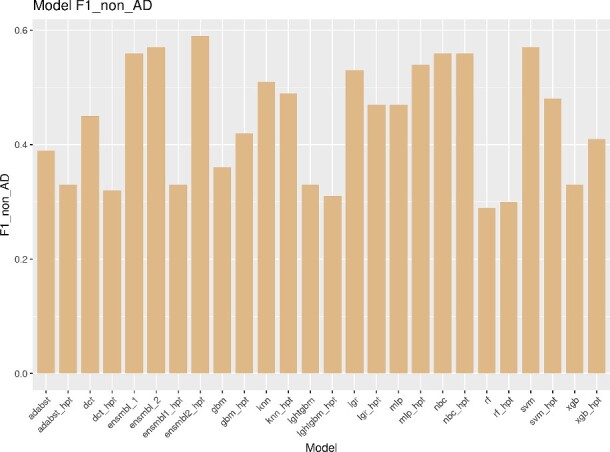
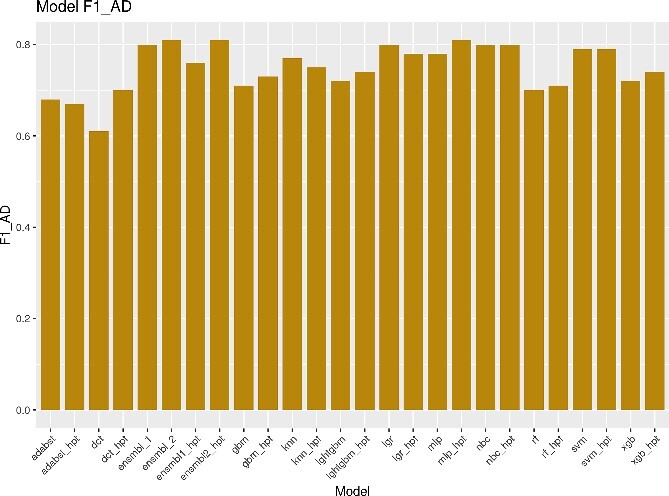
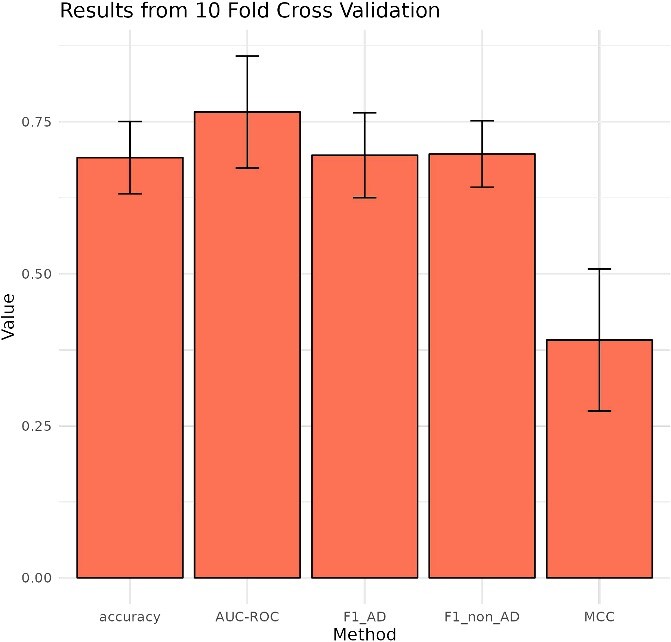
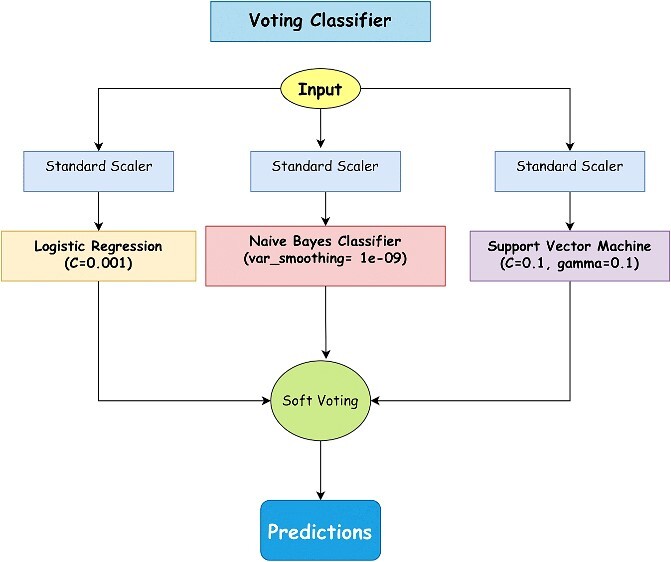
Neurodegenerative diseases, such as Alzheimer's disease, pose a significant global health challenge with their complex etiology and elusive biomarkers. In this study, we developed the Alzheimer's Identification Tool (AITeQ) using ribonucleic acid-sequencing (RNA-seq), a machine learning (ML) model based on an optimized ensemble algorithm for the identification of Alzheimer's from RNA-seq data. Analysis of RNA-seq data from several studies identified 87 differentially expressed genes. This was followed by a ML protocol involving feature selection, model training, performance evaluation, and hyperparameter tuning. The feature selection process undertaken in this study, employing a combination of four different methodologies, culminated in the identification of a compact yet impactful set of five genes. Twelve diverse ML models were trained and tested using these five genes (CNKSR1, EPHA2, CLSPN, OLFML3, and TARBP1). Performance metrics, including precision, recall, F1 score, accuracy, Matthew's correlation coefficient, and receiver operating characteristic area under the curve were assessed for the finally selected model. Overall, the ensemble model consisting of logistic regression, naive Bayes classifier, and support vector machine with optimized hyperparameters was identified as the best and was used to develop AITeQ. AITeQ is available at: https://github.com/ishtiaque-ahammad/AITeQ.
Keywords: AITeQ; Alzheimer’s disease; differentially expressed genes; machine learning; transcriptomics.
© The Author(s) 2024. Published by Oxford University Press.
Figures
Similar articles
-
Identifying novel transcript biomarkers for hepatocellular carcinoma (HCC) using RNA-Seq datasets and machine learning.BMC Cancer. 2021 Aug 27;21(1):962. doi: 10.1186/s12885-021-08704-9. BMC Cancer. 2021. PMID: 34445986 Free PMC article.
-
AlzGenPred - CatBoost-based gene classifier for predicting Alzheimer's disease using high-throughput sequencing data.Sci Rep. 2024 Dec 5;14(1):30294. doi: 10.1038/s41598-024-82208-x. Sci Rep. 2024. PMID: 39639110 Free PMC article.
-
Breast cancer prediction with transcriptome profiling using feature selection and machine learning methods.BMC Bioinformatics. 2022 Oct 1;23(1):410. doi: 10.1186/s12859-022-04965-8. BMC Bioinformatics. 2022. PMID: 36183055 Free PMC article.
-
Biological and Medical Importance of Cellular Heterogeneity Deciphered by Single-Cell RNA Sequencing.Cells. 2020 Jul 22;9(8):1751. doi: 10.3390/cells9081751. Cells. 2020. PMID: 32707839 Free PMC article. Review.
-
Accelerating Hyperparameter Tuning in Machine Learning for Alzheimer's Disease With High Performance Computing.Front Artif Intell. 2021 Dec 8;4:798962. doi: 10.3389/frai.2021.798962. eCollection 2021. Front Artif Intell. 2021. PMID: 34957393 Free PMC article. Review.
Cited by
-
Predicting Alzheimer's Cognitive Resilience Score: A Comparative Study of Machine Learning Models Using RNA-seq Data.bioRxiv [Preprint]. 2024 Aug 26:2024.08.25.609610. doi: 10.1101/2024.08.25.609610. bioRxiv. 2024. PMID: 39253457 Free PMC article. Preprint.
References
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
Miscellaneous
