

GPU optimization techniques to accelerate optiGAN-a particle simulation GAN
- PMID: 38881563
- PMCID: PMC11170465
- DOI: 10.1088/2632-2153/ad51c9
GPU optimization techniques to accelerate optiGAN-a particle simulation GAN
Abstract
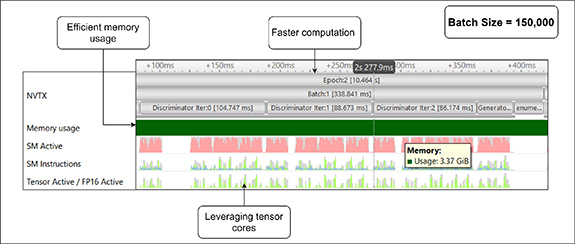
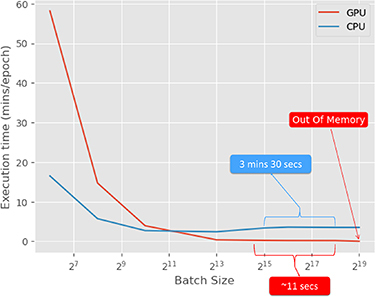
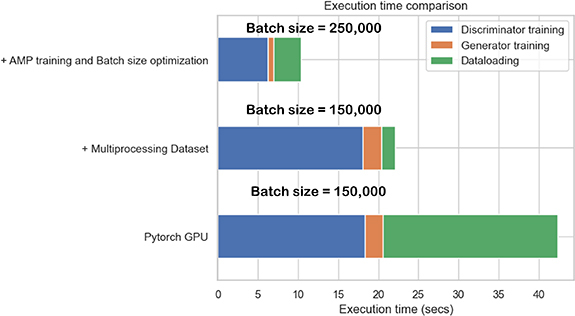
The demand for specialized hardware to train AI models has increased in tandem with the increase in the model complexity over the recent years. Graphics processing unit (GPU) is one such hardware that is capable of parallelizing operations performed on a large chunk of data. Companies like Nvidia, AMD, and Google have been constantly scaling-up the hardware performance as fast as they can. Nevertheless, there is still a gap between the required processing power and processing capacity of the hardware. To increase the hardware utilization, the software has to be optimized too. In this paper, we present some general GPU optimization techniques we used to efficiently train the optiGAN model, a Generative Adversarial Network that is capable of generating multidimensional probability distributions of optical photons at the photodetector face in radiation detectors, on an 8GB Nvidia Quadro RTX 4000 GPU. We analyze and compare the performances of all the optimizations based on the execution time and the memory consumed using the Nvidia Nsight Systems profiler tool. The optimizations gave approximately a 4.5x increase in the runtime performance when compared to a naive training on the GPU, without compromising the model performance. Finally we discuss optiGANs future work and how we are planning to scale the model on GPUs.
Keywords: Monte-Carlo simulation; generative adversarial networks; graphics processing unit; multidimensional probability distributions; performance optimization; radiation detector.
© 2024 The Author(s). Published by IOP Publishing Ltd.
Figures






References
-
- Allison J, et al. Recent developments in Geant4. Nucl. Instrum. Methods Phys. Res. A . 2016;835:186–225. doi: 10.1016/j.nima.2016.06.125. - DOI
-
- Arjovsky M, Chintala S, Bottou L. Wasserstein GAN. 2017 (arXiv: 1701.07875 [cs, stat])
-
- Chetlur S, Woolley C, Vandermersch P, Cohen J, Tran J, Catanzaro B, Shelhamer E. cuDNN: efficient primitives for deep learning. 2014 (arXiv: 1410.0759 [cs])
-
- Dao T. FlashAttention-2: faster attention with better parallelism and work partitioning. 2023 (arXiv: 2307.08691 [cs])
-
- Data Sheet: Quadro RTX 4000 2019. (available at: www.nvidia.com/content/dam/en-zz/Solutions/design-visualization/quadro-p...)
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous