

Representations and generalization in artificial and brain neural networks
- PMID: 38913896
- PMCID: PMC11228472
- DOI: 10.1073/pnas.2311805121
Representations and generalization in artificial and brain neural networks
Abstract
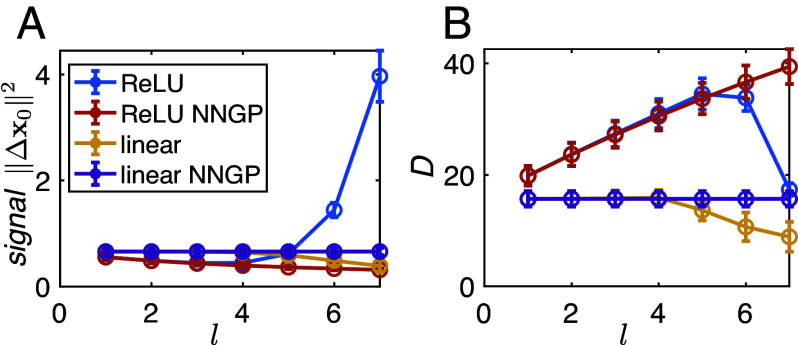
Humans and animals excel at generalizing from limited data, a capability yet to be fully replicated in artificial intelligence. This perspective investigates generalization in biological and artificial deep neural networks (DNNs), in both in-distribution and out-of-distribution contexts. We introduce two hypotheses: First, the geometric properties of the neural manifolds associated with discrete cognitive entities, such as objects, words, and concepts, are powerful order parameters. They link the neural substrate to the generalization capabilities and provide a unified methodology bridging gaps between neuroscience, machine learning, and cognitive science. We overview recent progress in studying the geometry of neural manifolds, particularly in visual object recognition, and discuss theories connecting manifold dimension and radius to generalization capacity. Second, we suggest that the theory of learning in wide DNNs, especially in the thermodynamic limit, provides mechanistic insights into the learning processes generating desired neural representational geometries and generalization. This includes the role of weight norm regularization, network architecture, and hyper-parameters. We will explore recent advances in this theory and ongoing challenges. We also discuss the dynamics of learning and its relevance to the issue of representational drift in the brain.
Keywords: deep neural networks; few-shot learning; neural manifolds; representational drift; visual cortex.
Conflict of interest statement
Competing interests statement:The authors declare no competing interest.
Figures







References
-
- C. Tan et al.., “A survey on deep transfer learning” in Artificial Neural Networks and Machine Learning–ICANN 2018: 27th International Conference on Artificial Neural Networks, Rhodes, Greece, October 4–7, 2018, Proceedings, Part III 27, N. Lawrence, Eds. (Springer, 2018), pp. 270–279.
-
- Wang Y., Yao Q., Kwok J. T., Ni L. M., Generalizing from a few examples: A survey on few-shot learning. ACM Comp. Surv. (CSUR) 53, 1–34 (2020).
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
