

Lightning Pose: improved animal pose estimation via semi-supervised learning, Bayesian ensembling and cloud-native open-source tools
- PMID: 38918605
- PMCID: PMC12087009
- DOI: 10.1038/s41592-024-02319-1
Lightning Pose: improved animal pose estimation via semi-supervised learning, Bayesian ensembling and cloud-native open-source tools
Abstract
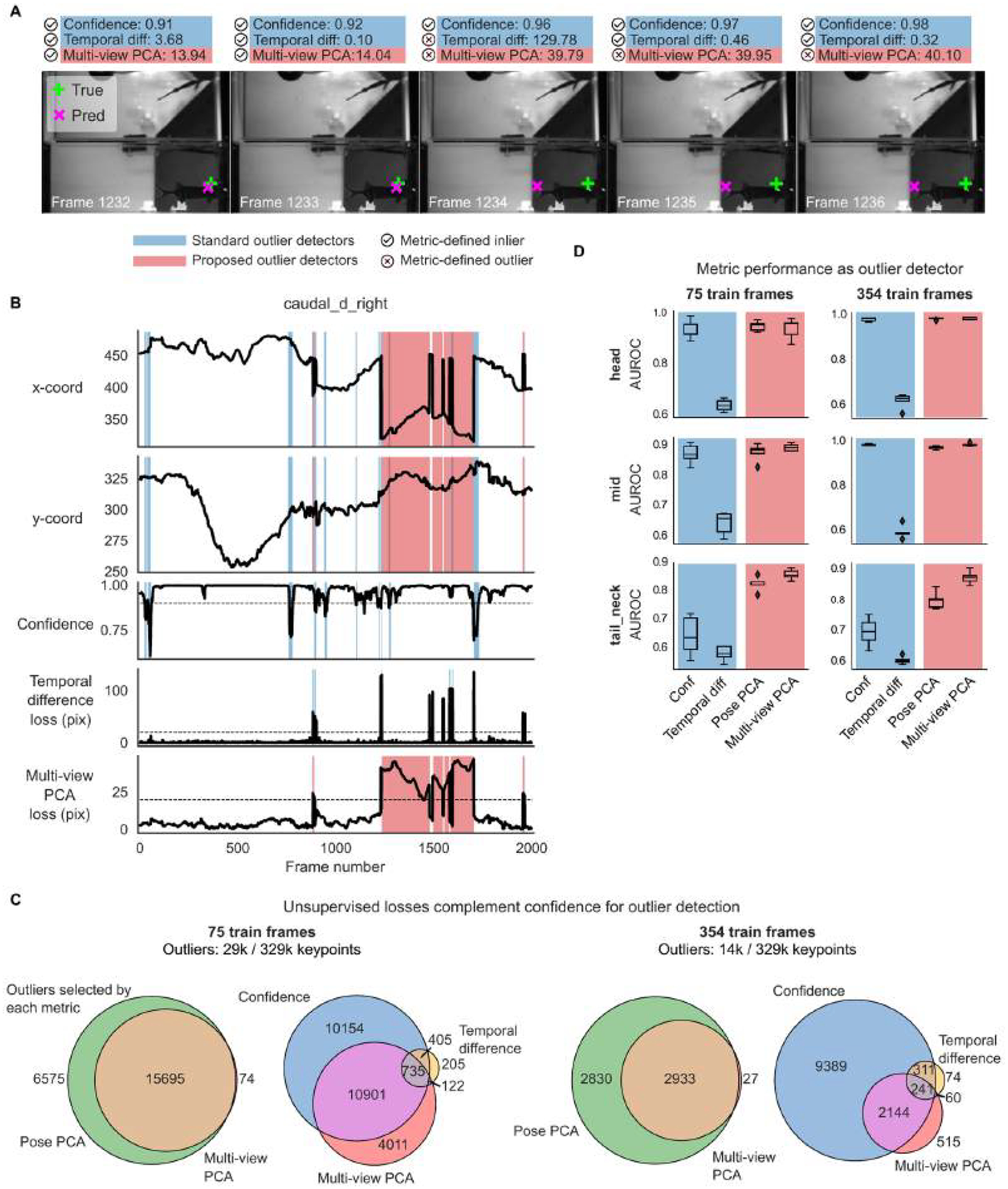
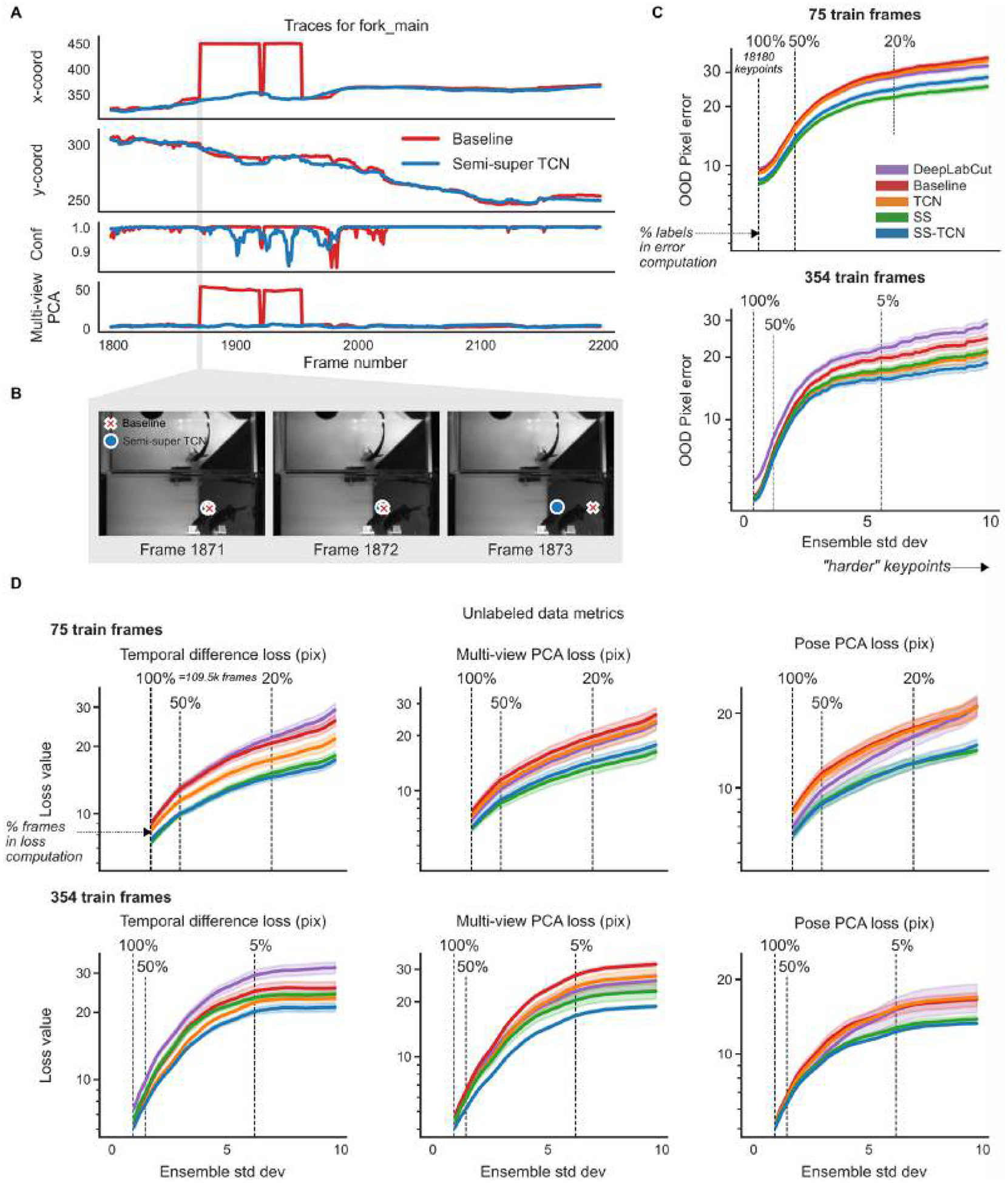
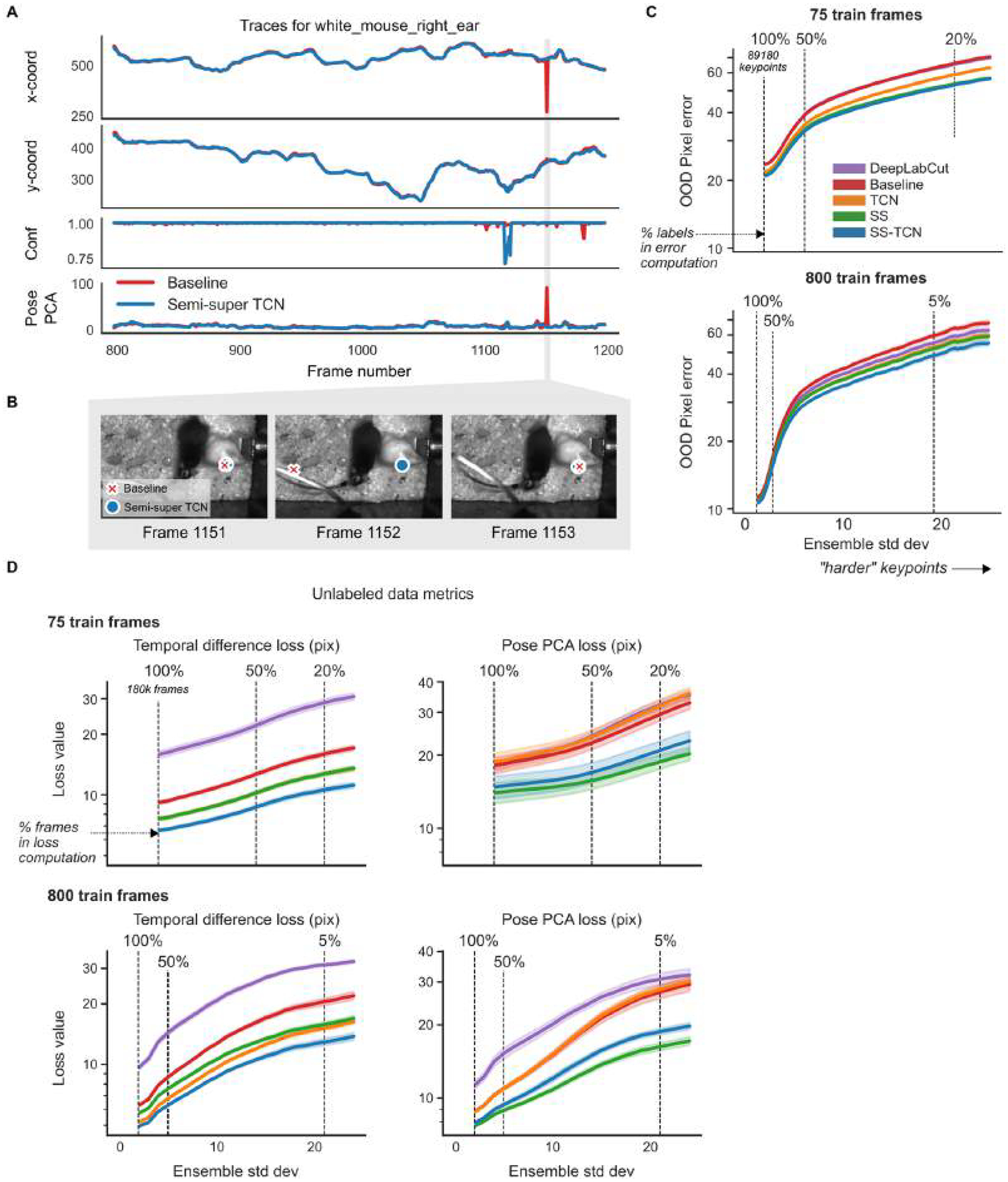
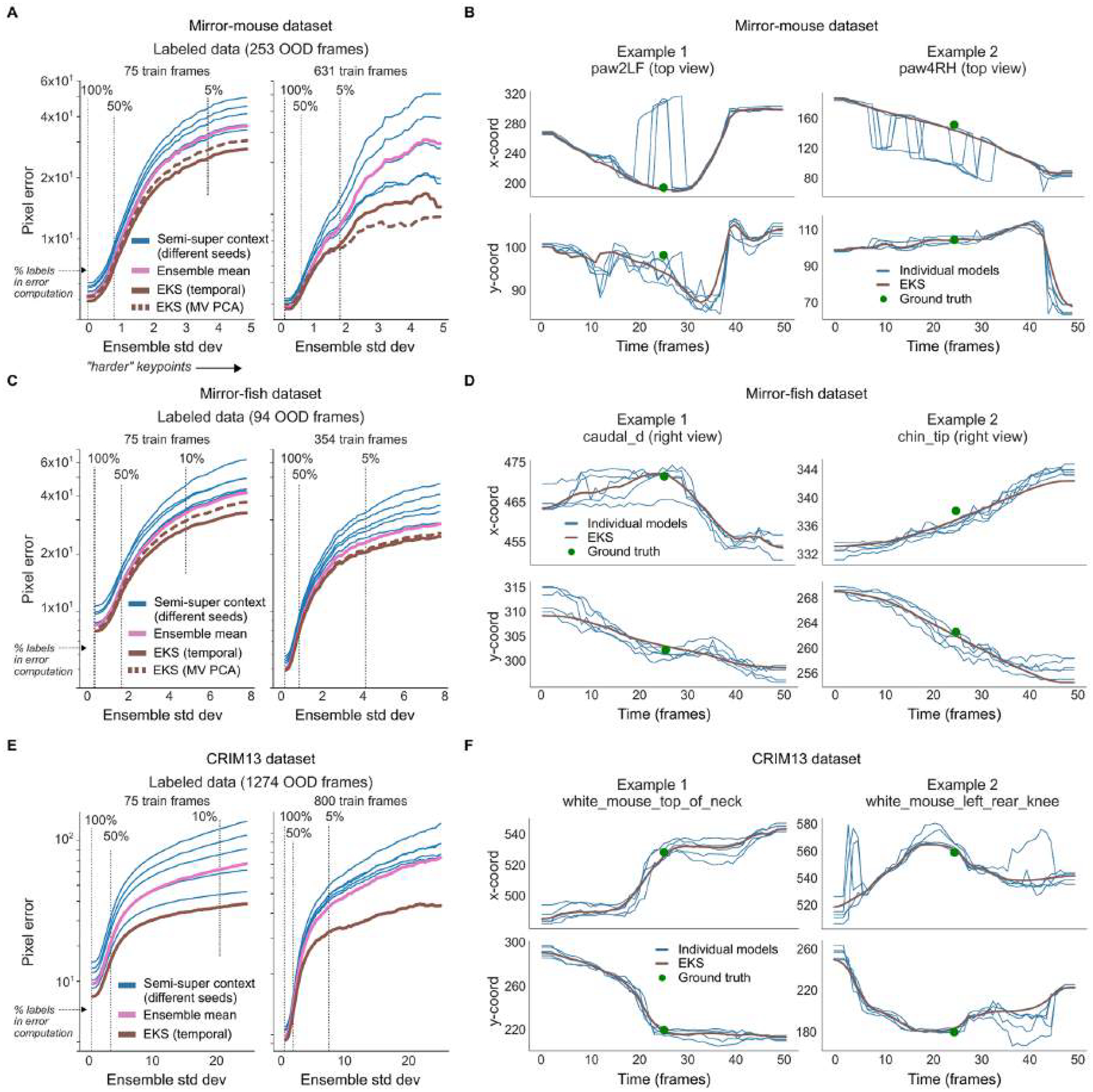
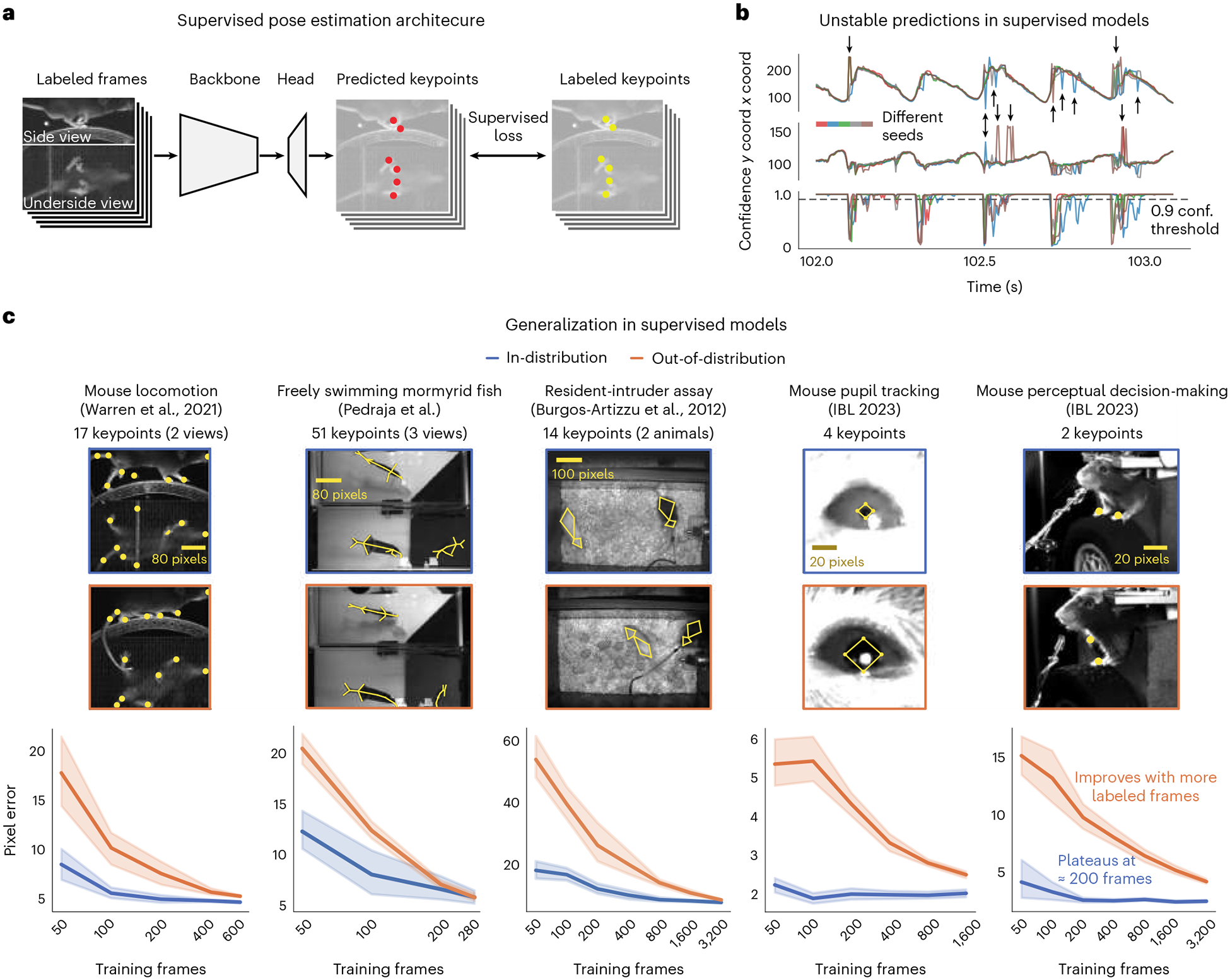
Contemporary pose estimation methods enable precise measurements of behavior via supervised deep learning with hand-labeled video frames. Although effective in many cases, the supervised approach requires extensive labeling and often produces outputs that are unreliable for downstream analyses. Here, we introduce 'Lightning Pose', an efficient pose estimation package with three algorithmic contributions. First, in addition to training on a few labeled video frames, we use many unlabeled videos and penalize the network whenever its predictions violate motion continuity, multiple-view geometry and posture plausibility (semi-supervised learning). Second, we introduce a network architecture that resolves occlusions by predicting pose on any given frame using surrounding unlabeled frames. Third, we refine the pose predictions post hoc by combining ensembling and Kalman smoothing. Together, these components render pose trajectories more accurate and scientifically usable. We released a cloud application that allows users to label data, train networks and process new videos directly from the browser.
© 2024. The Author(s), under exclusive licence to Springer Nature America, Inc.
Conflict of interest statement
Competing interests
R.S.L. assisted in the initial development of the cloud application as a solution architect at Lightning AI in Spring/Summer 2022. R.S.L. left the company in August 2022 and continues to hold shares. The remaining authors declare no competing interests.
Figures









Update of
-
Lightning Pose: improved animal pose estimation via semi-supervised learning, Bayesian ensembling, and cloud-native open-source tools.bioRxiv [Preprint]. 2024 Apr 3:2023.04.28.538703. doi: 10.1101/2023.04.28.538703. bioRxiv. 2024. Update in: Nat Methods. 2024 Jul;21(7):1316-1328. doi: 10.1038/s41592-024-02319-1. PMID: 37162966 Free PMC article. Updated. Preprint.
References
-
- Krakauer JW, Ghazanfar AA, Gomez-Marin A, Maclver MA & Poeppel D Neuroscience needs behavior: correcting a reductionist bias. Neuron 93, 480–490 (2017). - PubMed
MeSH terms
Grants and funding
- 216324/WT_/Wellcome Trust/United Kingdom
- R01 DK131086/DK/NIDDK NIH HHS/United States
- IOS-2115007/National Science Foundation (NSF)
- 543023/Simons Foundation
- GAT3708/Gatsby Charitable Foundation
- R01 NS118448/NS/NINDS NIH HHS/United States
- WT_/Wellcome Trust/United Kingdom
- NS075023/U.S. Department of Health & Human Services | NIH | National Institute of Neurological Disorders and Stroke (NINDS)
- 1RF1NS118448-01/U.S. Department of Health & Human Services | NIH | National Institute of Neurological Disorders and Stroke (NINDS)
- 5R01DK131086-02/U.S. Department of Health & Human Services | NIH | National Institute of Diabetes and Digestive and Kidney Diseases (National Institute of Diabetes & Digestive & Kidney Diseases)
- 1707398/National Science Foundation (NSF)
- VI.Veni.212.184/Nederlandse Organisatie voor Wetenschappelijk Onderzoek (Netherlands Organisation for Scientific Research)
- RF1 NS118448/NS/NINDS NIH HHS/United States
- K99 NS128075/NS/NINDS NIH HHS/United States
- U19 NS107613/NS/NINDS NIH HHS/United States
- R01 NS075023/NS/NINDS NIH HHS/United States
- K99NS128075/U.S. Department of Health & Human Services | NIH | National Institute of Neurological Disorders and Stroke (NINDS)
- U19NS123716/U.S. Department of Health & Human Services | NIH | National Institute of Neurological Disorders and Stroke (NINDS)
- U19 NS123716/NS/NINDS NIH HHS/United States
LinkOut - more resources
Full Text Sources
