

The annotation of GBA1 has been concealed by its protein-coding pseudogene GBAP1
- PMID: 38924406
- PMCID: PMC11204300
- DOI: 10.1126/sciadv.adk1296
The annotation of GBA1 has been concealed by its protein-coding pseudogene GBAP1
Abstract
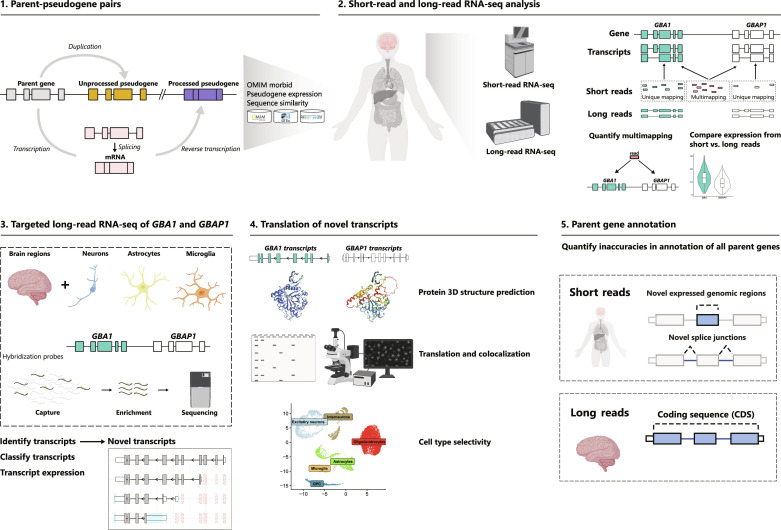
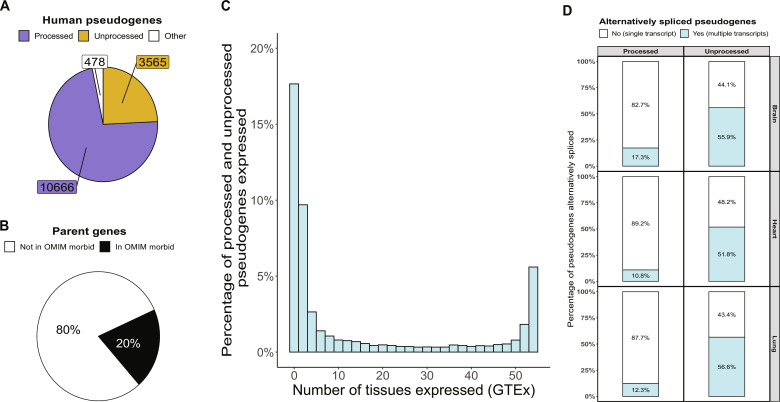
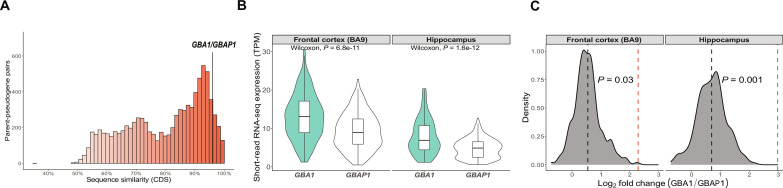
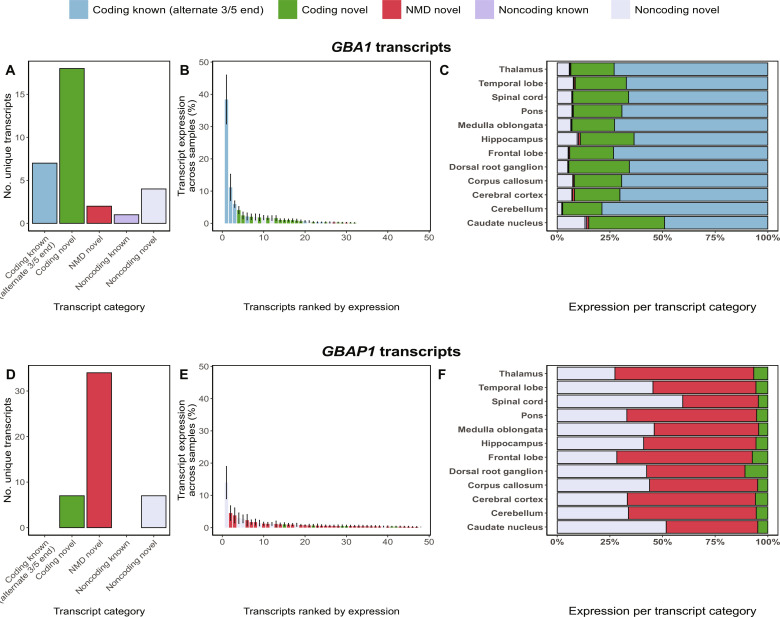
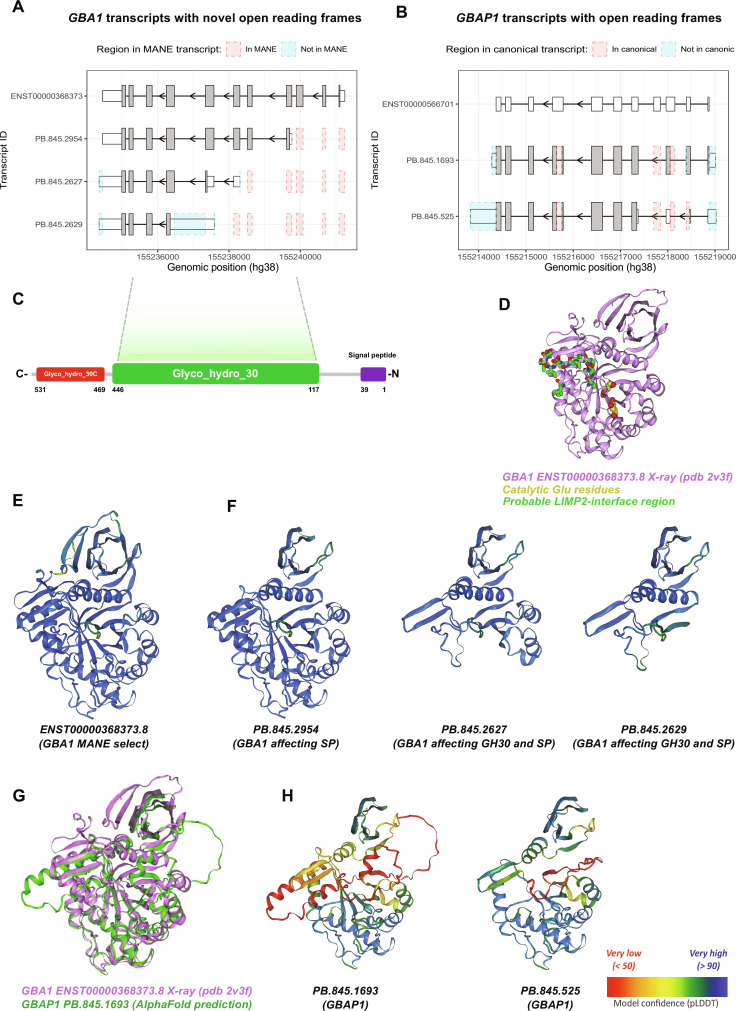
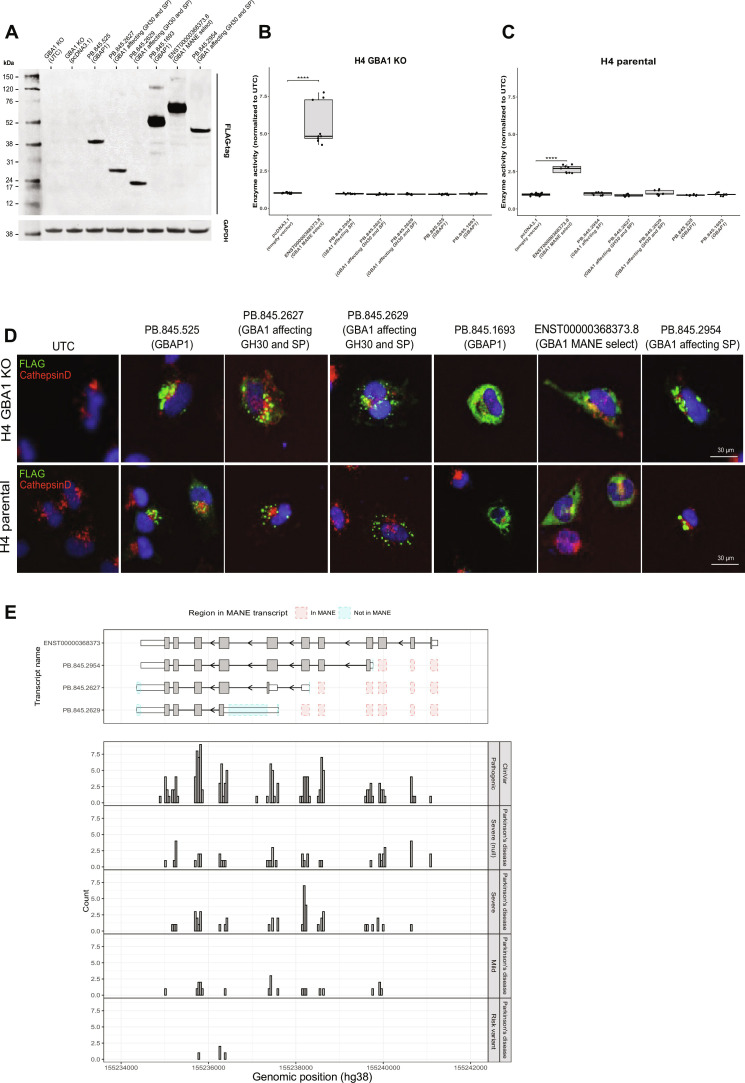
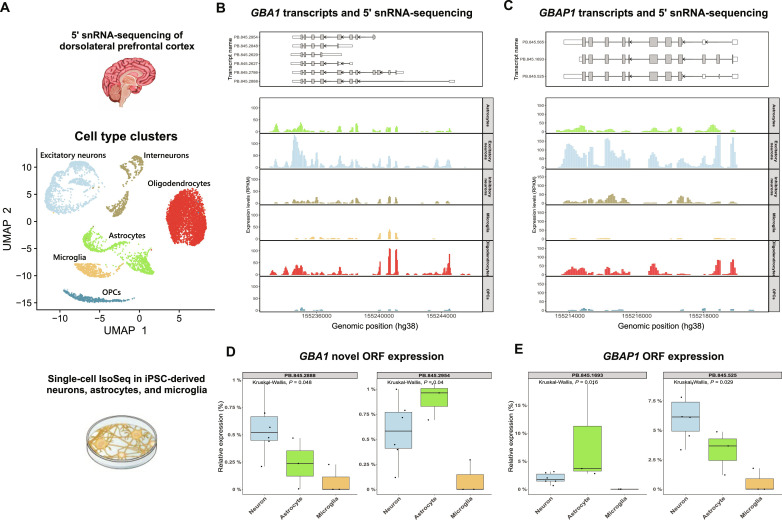
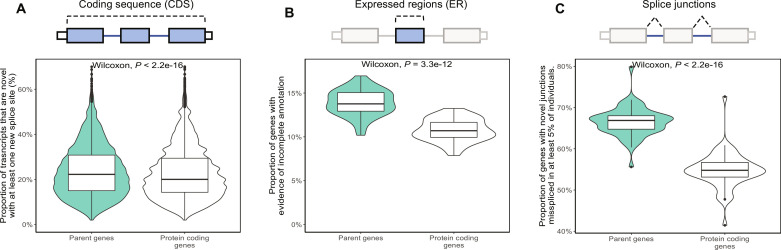
Mutations in GBA1 cause Gaucher disease and are the most important genetic risk factor for Parkinson's disease. However, analysis of transcription at this locus is complicated by its highly homologous pseudogene, GBAP1. We show that >50% of short RNA-sequencing reads mapping to GBA1 also map to GBAP1. Thus, we used long-read RNA sequencing in the human brain, which allowed us to accurately quantify expression from both GBA1 and GBAP1. We discovered significant differences in expression compared to short-read data and identify currently unannotated transcripts of both GBA1 and GBAP1. These included protein-coding transcripts from both genes that were translated in human brain, but without the known lysosomal function-yet accounting for almost a third of transcription. Analyzing brain-specific cell types using long-read and single-nucleus RNA sequencing revealed region-specific variations in transcript expression. Overall, these findings suggest nonlysosomal roles for GBA1 and GBAP1 with implications for our understanding of the role of GBA1 in health and disease.
Figures
References
-
- Ebbert M. T. W., Jensen T. D., Jansen-West K., Sens J. P., Reddy J. S., Ridge P. G., Kauwe J. S. K., Belzil V., Pregent L., Carrasquillo M. M., Keene D., Larson E., Crane P., Asmann Y. W., Ertekin-Taner N., Younkin S. G., Ross O. A., Rademakers R., Petrucelli L., Fryer J. D., Systematic analysis of dark and camouflaged genes reveals disease-relevant genes hiding in plain sight. Genome Biol. 20, 1–23 (2019). - PMC - PubMed
-
- Toffoli M., Chen X., Sedlazeck F. J., Lee C. Y., Mullin S., Higgins A., Koletsi S., Garcia-Segura M. E., Sammler E., Scholz S. W., Schapira A. H. V., Eberle M. A., Proukakis C., Comprehensive short and long read sequencing analysis for the Gaucher and Parkinson’s disease-associated GBA gene. Commun. Biol. 5, 1–10 (2022). - PMC - PubMed
-
- Weinreb N. J., Brady R. O., Tappel A. L., The lysosomal localization of sphingolipid hydrolases. Biochim. Biophys. Acta 159, 141–146 (1968). - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
