

CodonBERT large language model for mRNA vaccines
- PMID: 38951026
- PMCID: PMC11368176
- DOI: 10.1101/gr.278870.123
CodonBERT large language model for mRNA vaccines
Abstract
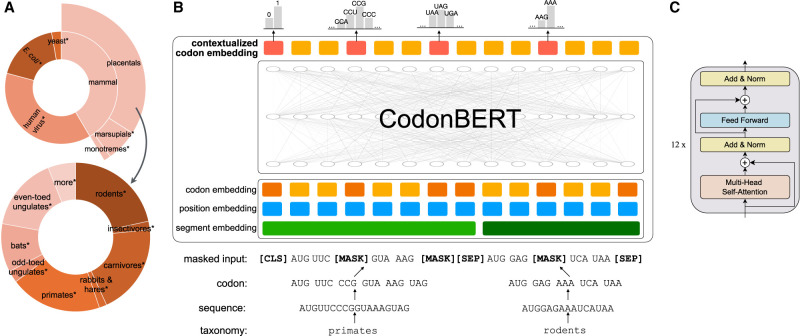
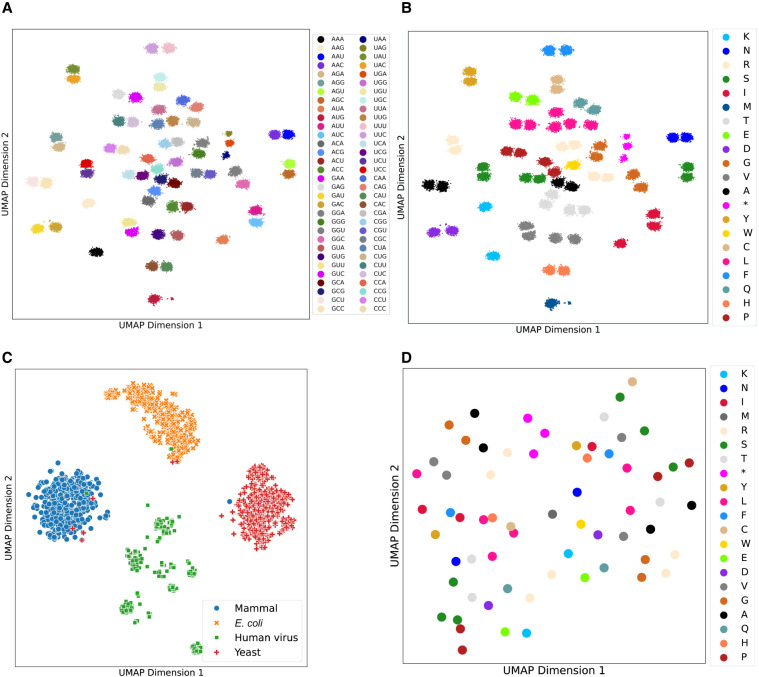
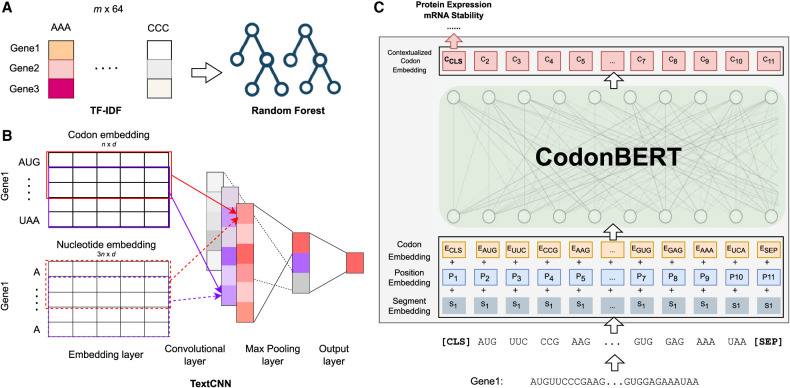
mRNA-based vaccines and therapeutics are gaining popularity and usage across a wide range of conditions. One of the critical issues when designing such mRNAs is sequence optimization. Even small proteins or peptides can be encoded by an enormously large number of mRNAs. The actual mRNA sequence can have a large impact on several properties, including expression, stability, immunogenicity, and more. To enable the selection of an optimal sequence, we developed CodonBERT, a large language model (LLM) for mRNAs. Unlike prior models, CodonBERT uses codons as inputs, which enables it to learn better representations. CodonBERT was trained using more than 10 million mRNA sequences from a diverse set of organisms. The resulting model captures important biological concepts. CodonBERT can also be extended to perform prediction tasks for various mRNA properties. CodonBERT outperforms previous mRNA prediction methods, including on a new flu vaccine data set.
© 2024 Li et al.; Published by Cold Spring Harbor Laboratory Press.
Figures
References
-
- Al-Hawash AB, Zhang X, Ma F. 2017. Strategies of codon optimization for high-level heterologous protein expression in microbial expression systems. Gene Rep 9: 46–53. 10.1016/j.genrep.2017.08.006 - DOI
MeSH terms
Substances
LinkOut - more resources
Full Text Sources