

Semantic encoding during language comprehension at single-cell resolution
- PMID: 38961302
- PMCID: PMC11254762
- DOI: 10.1038/s41586-024-07643-2
Semantic encoding during language comprehension at single-cell resolution
Abstract
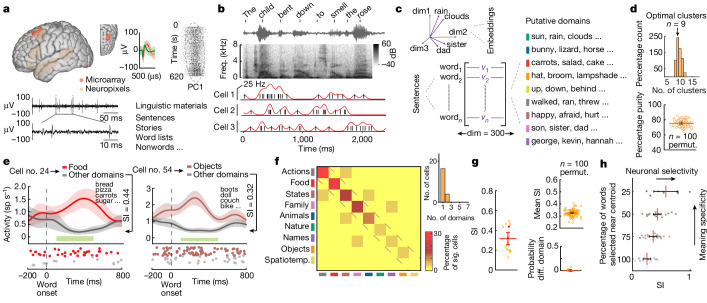
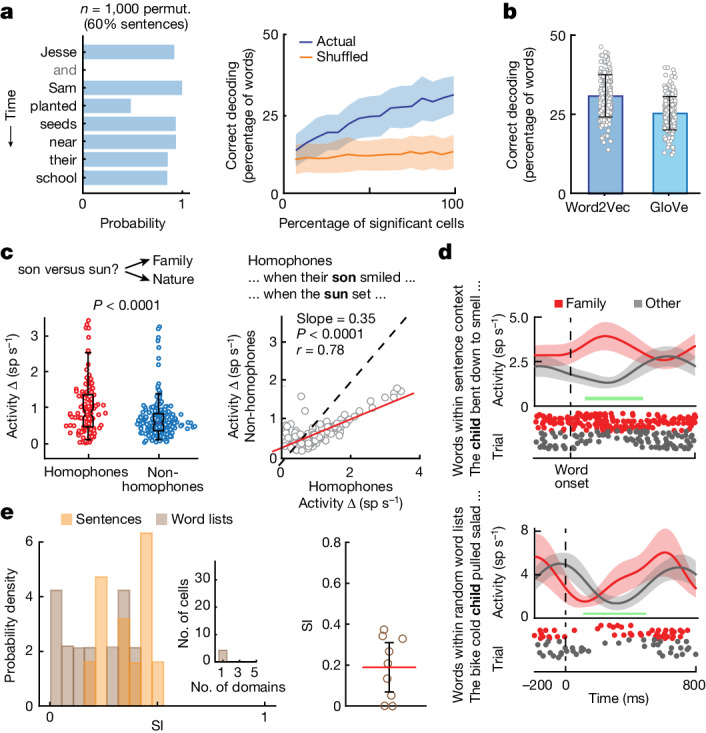
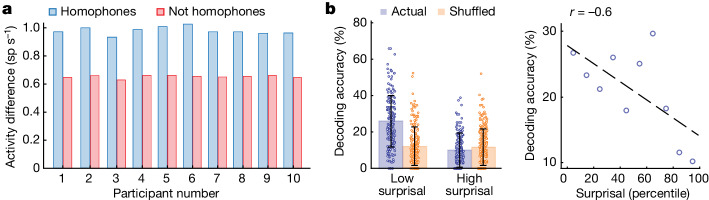
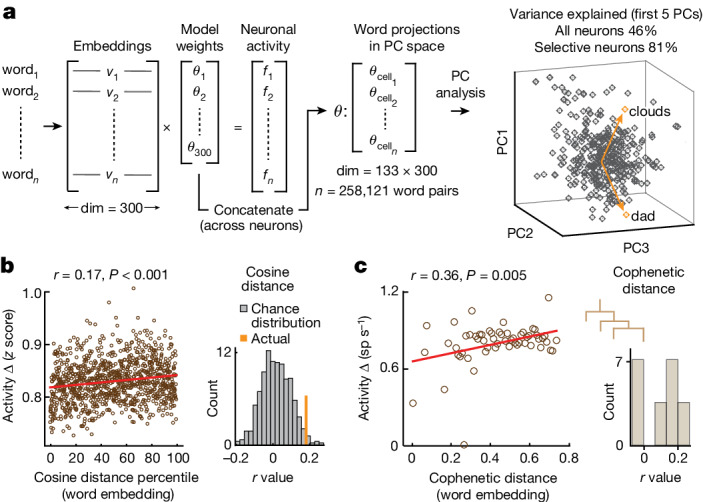
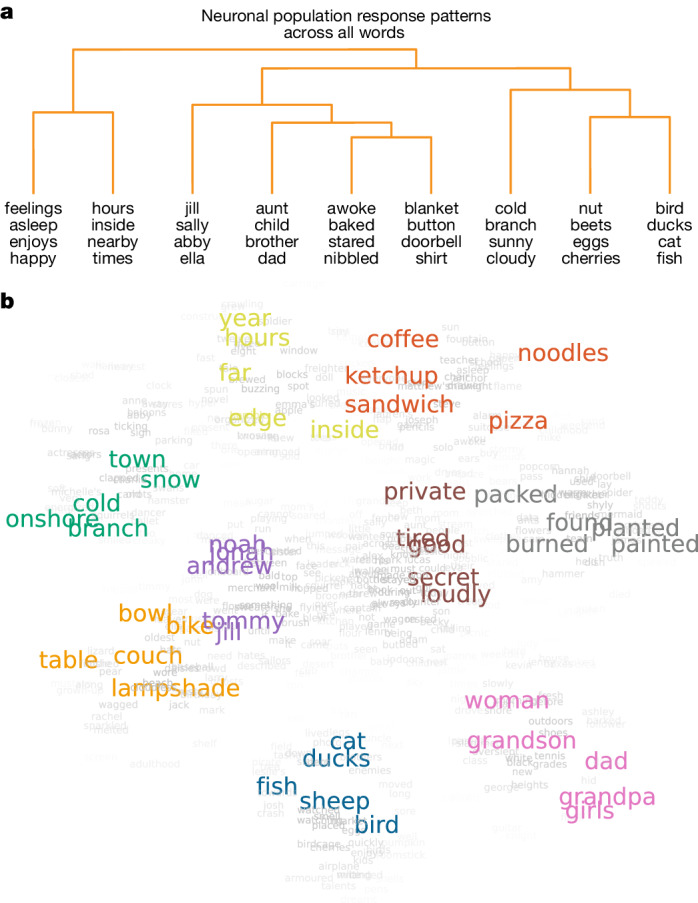
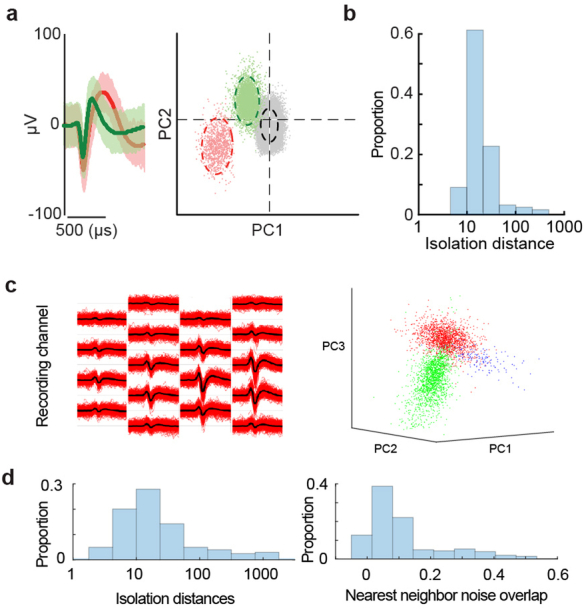
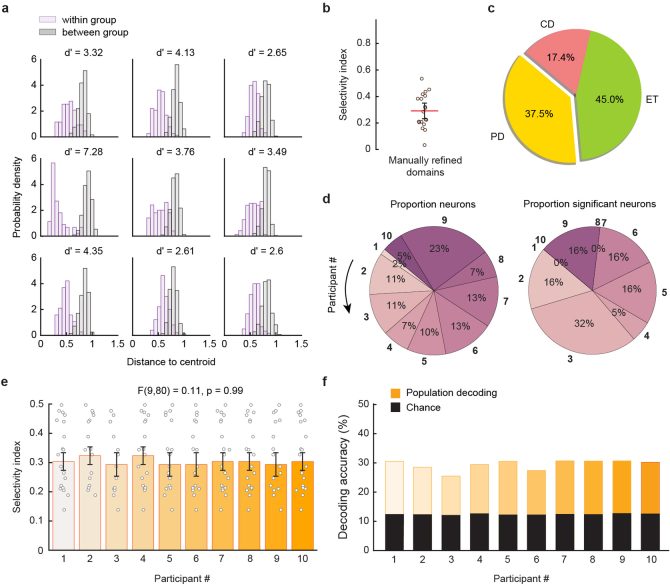
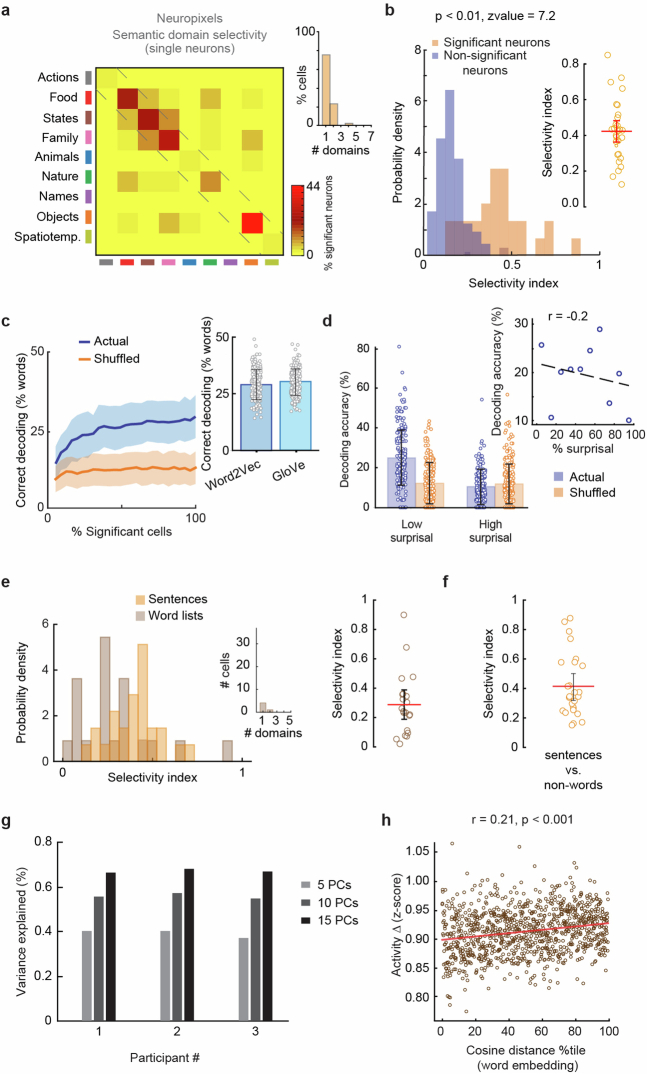
From sequences of speech sounds1,2 or letters3, humans can extract rich and nuanced meaning through language. This capacity is essential for human communication. Yet, despite a growing understanding of the brain areas that support linguistic and semantic processing4-12, the derivation of linguistic meaning in neural tissue at the cellular level and over the timescale of action potentials remains largely unknown. Here we recorded from single cells in the left language-dominant prefrontal cortex as participants listened to semantically diverse sentences and naturalistic stories. By tracking their activities during natural speech processing, we discover a fine-scale cortical representation of semantic information by individual neurons. These neurons responded selectively to specific word meanings and reliably distinguished words from nonwords. Moreover, rather than responding to the words as fixed memory representations, their activities were highly dynamic, reflecting the words' meanings based on their specific sentence contexts and independent of their phonetic form. Collectively, we show how these cell ensembles accurately predicted the broad semantic categories of the words as they were heard in real time during speech and how they tracked the sentences in which they appeared. We also show how they encoded the hierarchical structure of these meaning representations and how these representations mapped onto the cell population. Together, these findings reveal a finely detailed cortical organization of semantic representations at the neuron scale in humans and begin to illuminate the cellular-level processing of meaning during language comprehension.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
References
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
