

An activity-specificity trade-off encoded in human transcription factors
- PMID: 38969762
- PMCID: PMC11321997
- DOI: 10.1038/s41556-024-01411-0
An activity-specificity trade-off encoded in human transcription factors
Abstract
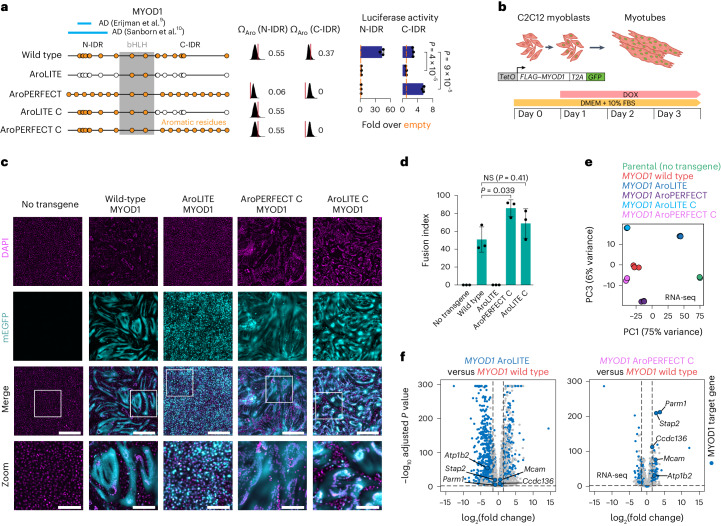
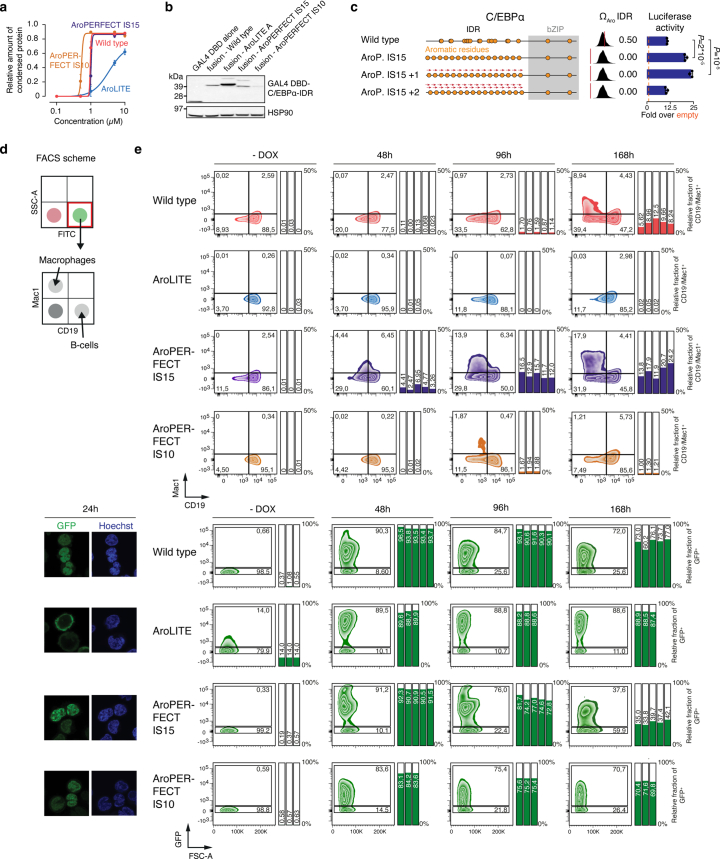
Transcription factors (TFs) control specificity and activity of gene transcription, but whether a relationship between these two features exists is unclear. Here we provide evidence for an evolutionary trade-off between the activity and specificity in human TFs encoded as submaximal dispersion of aromatic residues in their intrinsically disordered protein regions. We identified approximately 500 human TFs that encode short periodic blocks of aromatic residues in their intrinsically disordered regions, resembling imperfect prion-like sequences. Mutation of periodic aromatic residues reduced transcriptional activity, whereas increasing the aromatic dispersion of multiple human TFs enhanced transcriptional activity and reprogramming efficiency, promoted liquid-liquid phase separation in vitro and more promiscuous DNA binding in cells. Together with recent work on enhancer elements, these results suggest an important evolutionary role of suboptimal features in transcriptional control. We propose that rational engineering of amino acid features that alter phase separation may be a strategy to optimize TF-dependent processes, including cellular reprogramming.
© 2024. The Author(s).
Conflict of interest statement
The Max Planck Society has filed a patent application (EP23215195) based on the study. D.H. is a founder and scientific advisor of Nuage Therapeutics. The other authors declare no competing interests.
Figures















References
Publication types
MeSH terms
Substances
Grants and funding
- HN 4/3-1/Deutsche Forschungsgemeinschaft (German Research Foundation)
- XXX/Consell Català de Recerca i Innovació (Catalan Council for Research and Innovation)
- FKZ 031L0169A/Bundesministerium für Bildung, Wissenschaft, Forschung und Technologie (Federal Ministry for Education, Science, Research and Technology)
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
Research Materials
Miscellaneous
