

Blood protein assessment of leading incident diseases and mortality in the UK Biobank
- PMID: 38987645
- PMCID: PMC11257969
- DOI: 10.1038/s43587-024-00655-7
Blood protein assessment of leading incident diseases and mortality in the UK Biobank
Abstract
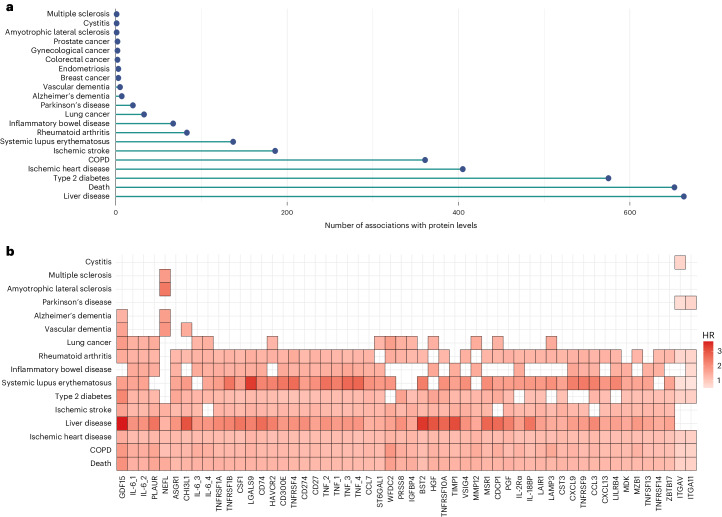
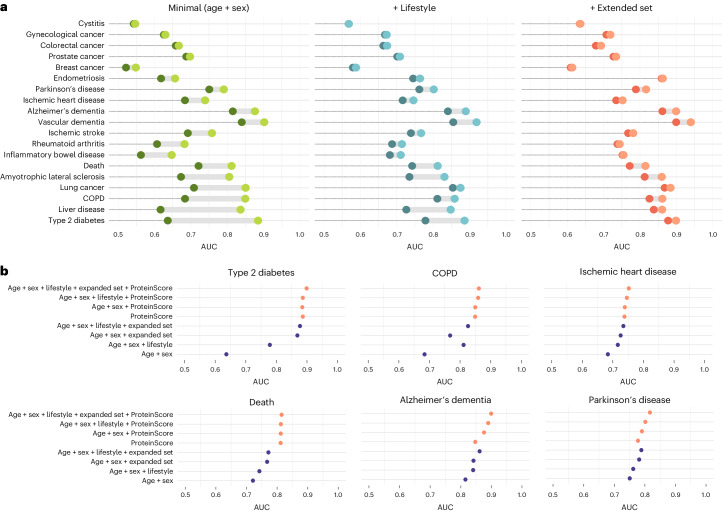
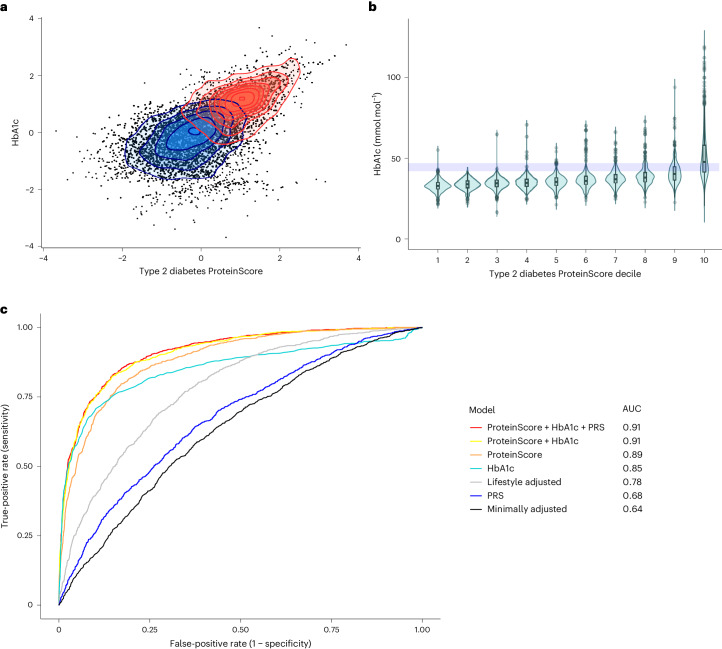
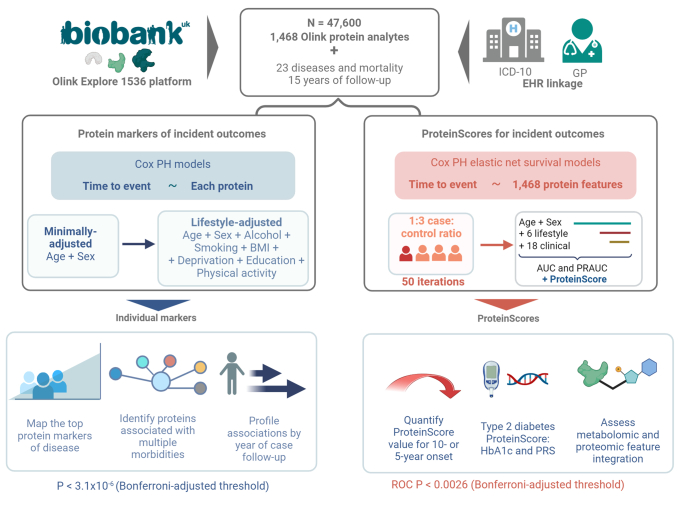
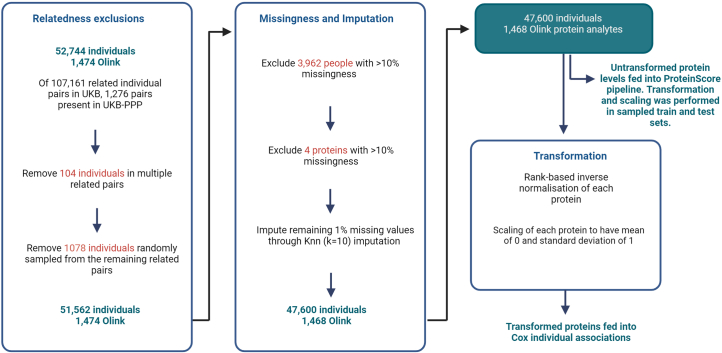
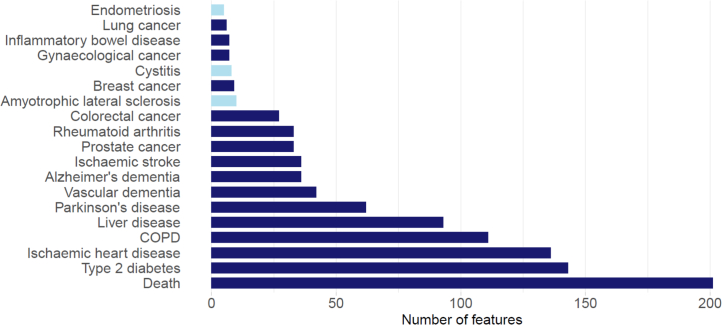
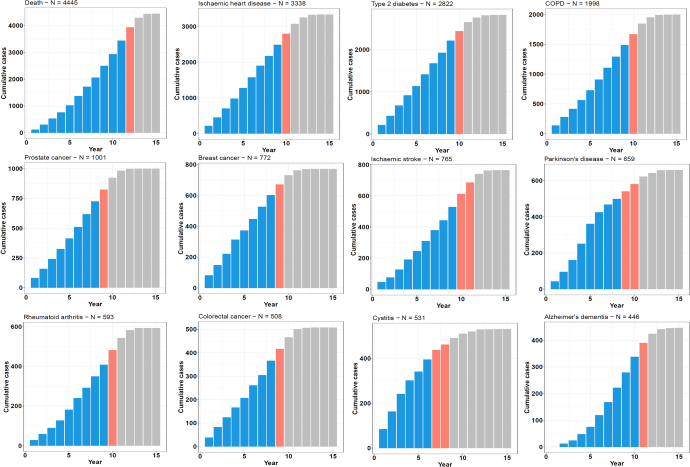
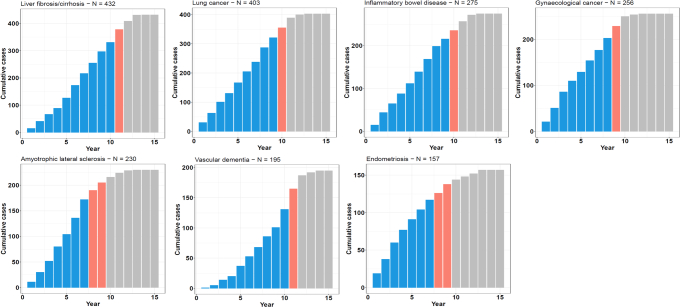
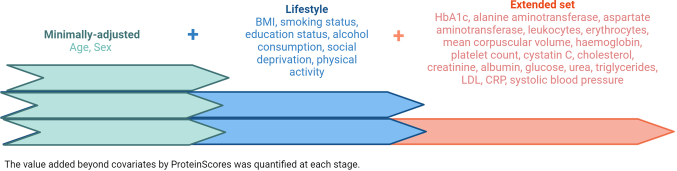
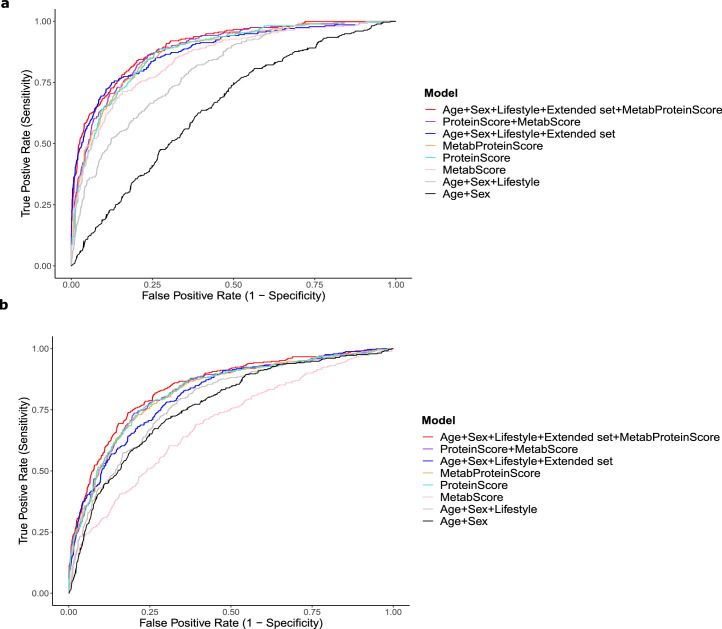
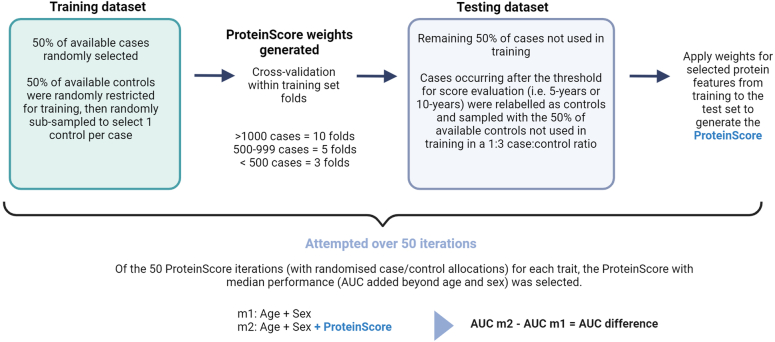
The circulating proteome offers insights into the biological pathways that underlie disease. Here, we test relationships between 1,468 Olink protein levels and the incidence of 23 age-related diseases and mortality in the UK Biobank (n = 47,600). We report 3,209 associations between 963 protein levels and 21 incident outcomes. Next, protein-based scores (ProteinScores) are developed using penalized Cox regression. When applied to test sets, six ProteinScores improve the area under the curve estimates for the 10-year onset of incident outcomes beyond age, sex and a comprehensive set of 24 lifestyle factors, clinically relevant biomarkers and physical measures. Furthermore, the ProteinScore for type 2 diabetes outperforms a polygenic risk score and HbA1c-a clinical marker used to monitor and diagnose type 2 diabetes. The performance of scores using metabolomic and proteomic features is also compared. These data characterize early proteomic contributions to major age-related diseases, demonstrating the value of the plasma proteome for risk stratification.
© 2024. The Author(s).
Conflict of interest statement
B.B.S., R.A., J.G., T.L., K.F. and H.R. are employed by Biogen. C.N.F., Z.K., D.A.G., M.D. and T.M. are employed by Optima Partners—a data consultancy agency employed by Biogen. D.A.G., R.F.H. and R.E.M. have received consultancy fees from Optima Partners. R.E.M. is an advisor to the Epigenetic Clock Development Foundation. R.F.H. has received consultancy fees from Illumina. The other authors declare no competing interests.
Figures
References
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
