

Learning to express reward prediction error-like dopaminergic activity requires plastic representations of time
- PMID: 38997276
- PMCID: PMC11245539
- DOI: 10.1038/s41467-024-50205-3
Learning to express reward prediction error-like dopaminergic activity requires plastic representations of time
Abstract
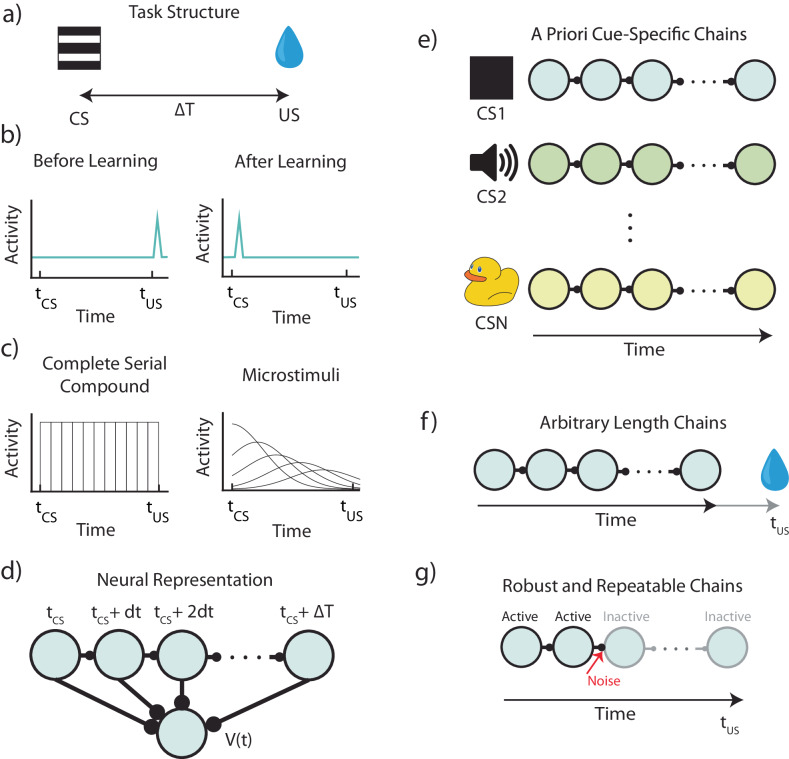
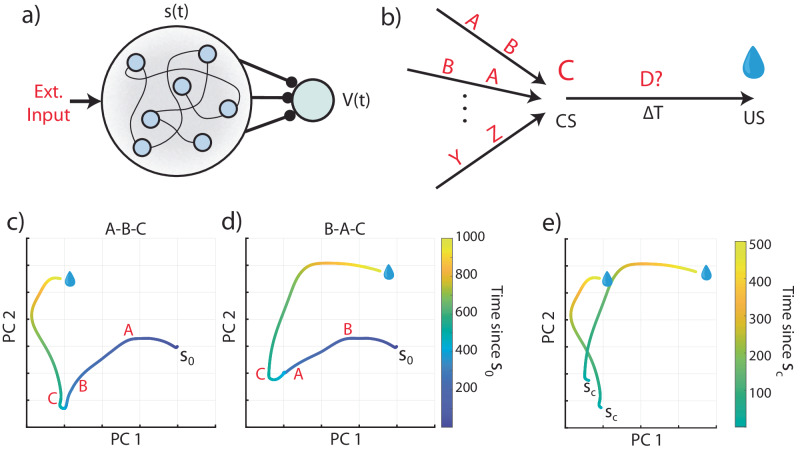
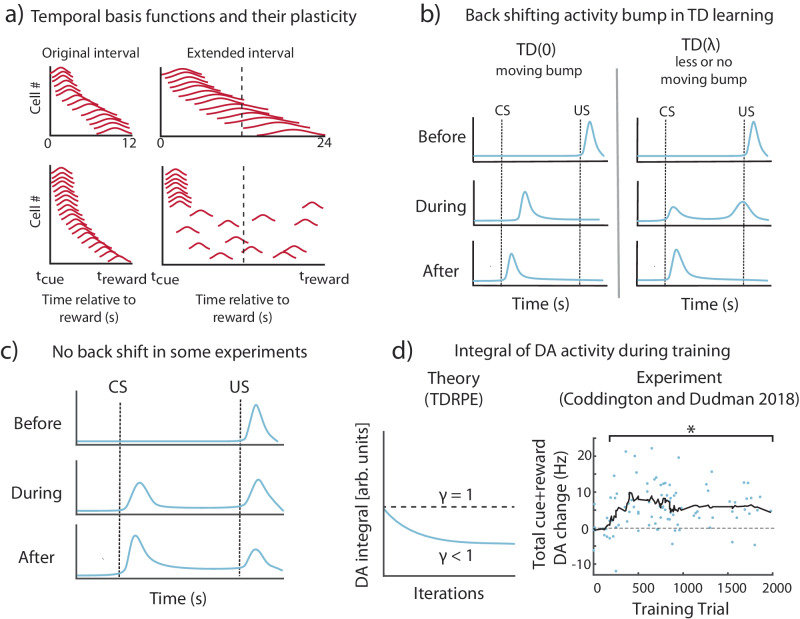
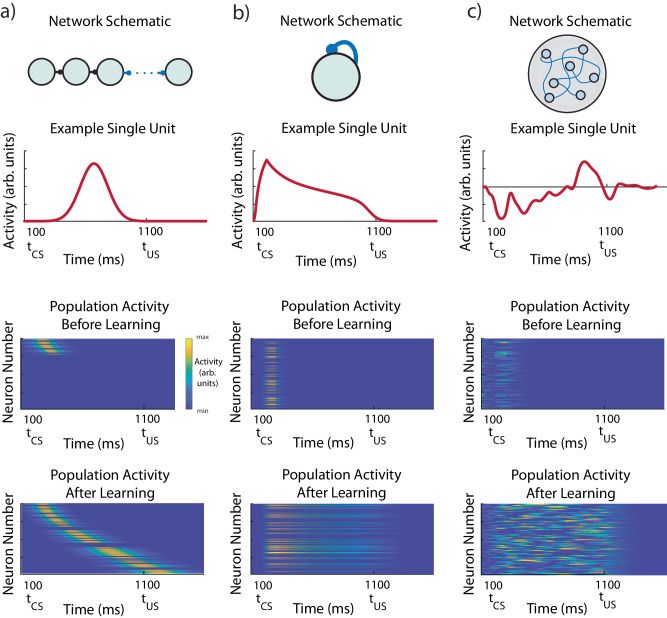
The dominant theoretical framework to account for reinforcement learning in the brain is temporal difference learning (TD) learning, whereby certain units signal reward prediction errors (RPE). The TD algorithm has been traditionally mapped onto the dopaminergic system, as firing properties of dopamine neurons can resemble RPEs. However, certain predictions of TD learning are inconsistent with experimental results, and previous implementations of the algorithm have made unscalable assumptions regarding stimulus-specific fixed temporal bases. We propose an alternate framework to describe dopamine signaling in the brain, FLEX (Flexibly Learned Errors in Expected Reward). In FLEX, dopamine release is similar, but not identical to RPE, leading to predictions that contrast to those of TD. While FLEX itself is a general theoretical framework, we describe a specific, biophysically plausible implementation, the results of which are consistent with a preponderance of both existing and reanalyzed experimental data.
© 2024. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
Update of
-
Learning to Express Reward Prediction Error-like Dopaminergic Activity Requires Plastic Representations of Time.Res Sq [Preprint]. 2023 Sep 19:rs.3.rs-3289985. doi: 10.21203/rs.3.rs-3289985/v1. Res Sq. 2023. Update in: Nat Commun. 2024 Jul 12;15(1):5856. doi: 10.1038/s41467-024-50205-3. PMID: 37790466 Free PMC article. Updated. Preprint.
Similar articles
-
Learning to Express Reward Prediction Error-like Dopaminergic Activity Requires Plastic Representations of Time.Res Sq [Preprint]. 2023 Sep 19:rs.3.rs-3289985. doi: 10.21203/rs.3.rs-3289985/v1. Res Sq. 2023. Update in: Nat Commun. 2024 Jul 12;15(1):5856. doi: 10.1038/s41467-024-50205-3. PMID: 37790466 Free PMC article. Updated. Preprint.
-
An imperfect dopaminergic error signal can drive temporal-difference learning.PLoS Comput Biol. 2011 May;7(5):e1001133. doi: 10.1371/journal.pcbi.1001133. Epub 2011 May 12. PLoS Comput Biol. 2011. PMID: 21589888 Free PMC article.
-
A Dual Role Hypothesis of the Cortico-Basal-Ganglia Pathways: Opponency and Temporal Difference Through Dopamine and Adenosine.Front Neural Circuits. 2019 Jan 7;12:111. doi: 10.3389/fncir.2018.00111. eCollection 2018. Front Neural Circuits. 2019. PMID: 30687019 Free PMC article.
-
The curious case of dopaminergic prediction errors and learning associative information beyond value.Nat Rev Neurosci. 2025 Mar;26(3):169-178. doi: 10.1038/s41583-024-00898-8. Epub 2025 Jan 8. Nat Rev Neurosci. 2025. PMID: 39779974 Review.
-
Updating dopamine reward signals.Curr Opin Neurobiol. 2013 Apr;23(2):229-38. doi: 10.1016/j.conb.2012.11.012. Epub 2012 Dec 22. Curr Opin Neurobiol. 2013. PMID: 23267662 Free PMC article. Review.
Cited by
-
Negative affect-driven impulsivity as hierarchical model-based overgeneralization.Trends Cogn Sci. 2025 May;29(5):407-420. doi: 10.1016/j.tics.2025.01.002. Epub 2025 Feb 6. Trends Cogn Sci. 2025. PMID: 39919952 Review.
-
Dopamine release plateau and outcome signals in dorsal striatum contrast with classic reinforcement learning formulations.Nat Commun. 2024 Oct 14;15(1):8856. doi: 10.1038/s41467-024-53176-7. Nat Commun. 2024. PMID: 39402067 Free PMC article.
References
-
- Sutton, R. S. & Barto, A. G. Reinforcement Learning, Second Edition: An Introduction. (MIT Press, 2018).
MeSH terms
Substances
Grants and funding
- R01 EB022891/EB/NIBIB NIH HHS/United States
- N00014-16-R-BA01/United States Department of Defense | United States Navy | ONR | Office of Naval Research Global (ONR Global)
- WT_/Wellcome Trust/United Kingdom
- EP/R035806/1/Simons Foundation
- BB/N013956/1/RCUK | Biotechnology and Biological Sciences Research Council (BBSRC)
LinkOut - more resources
Full Text Sources
