

Keypoint-MoSeq: parsing behavior by linking point tracking to pose dynamics
- PMID: 38997595
- PMCID: PMC11245396
- DOI: 10.1038/s41592-024-02318-2
Keypoint-MoSeq: parsing behavior by linking point tracking to pose dynamics
Abstract
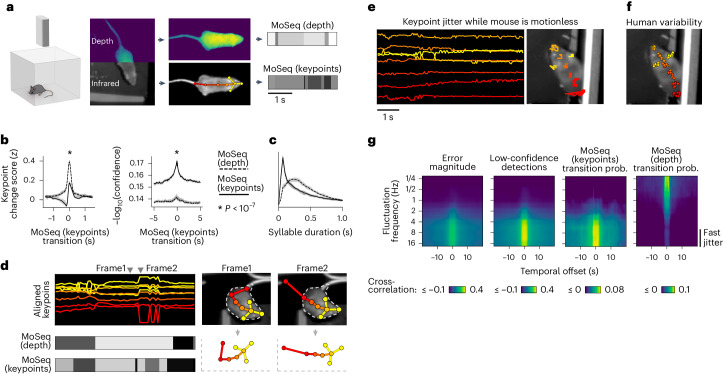
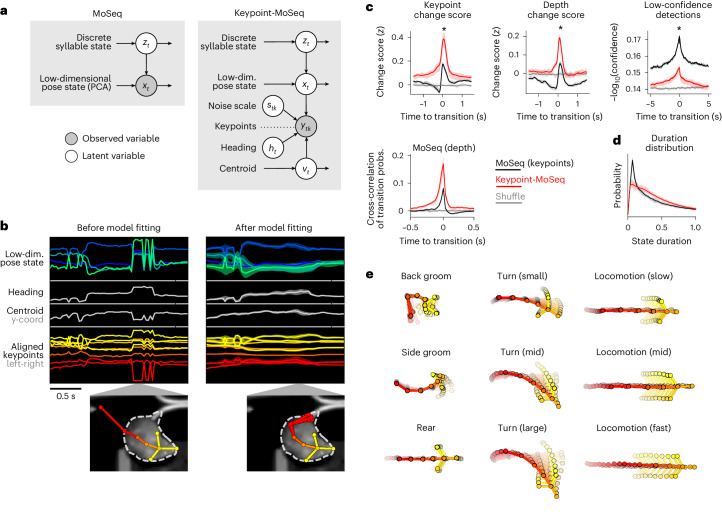
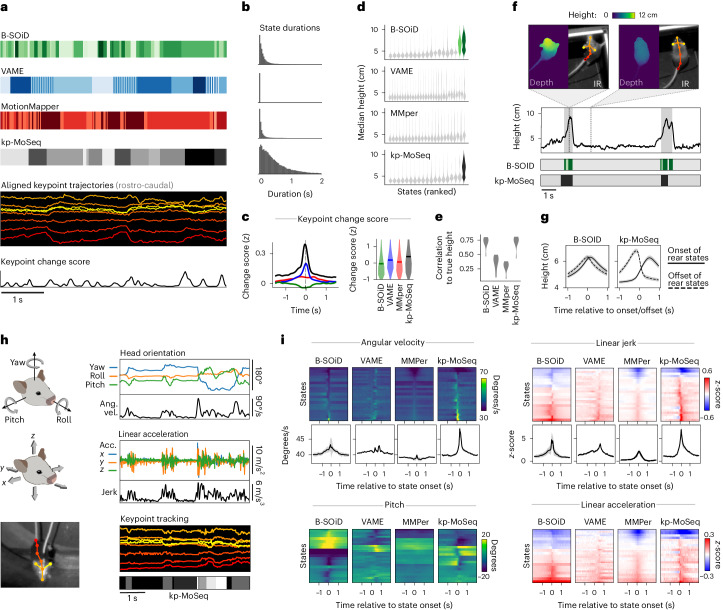
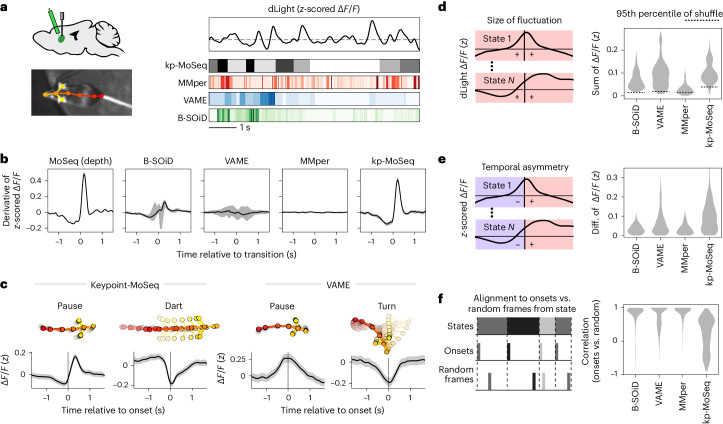
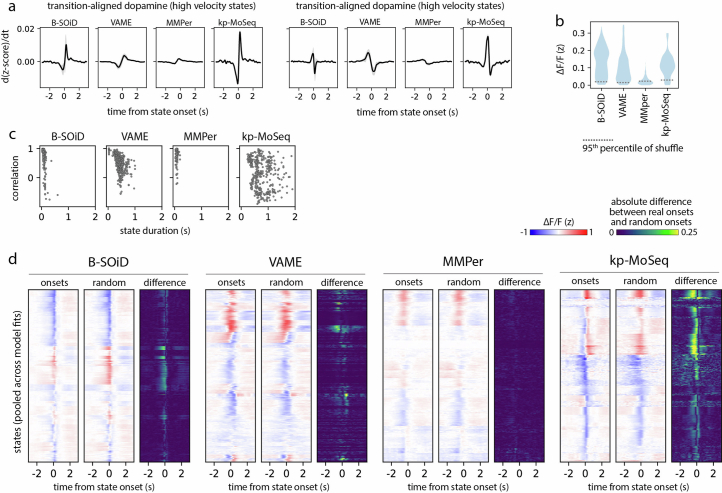
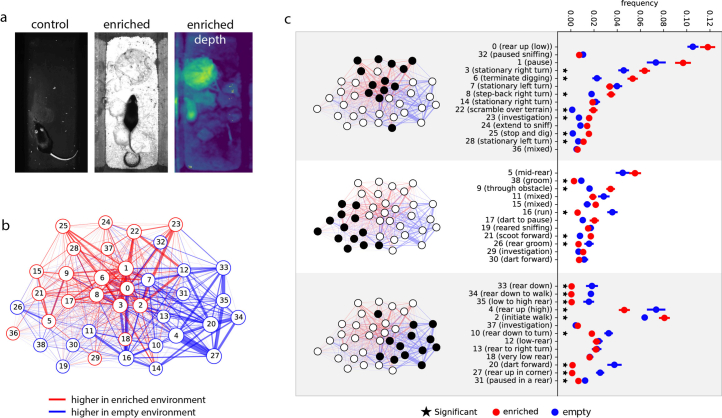
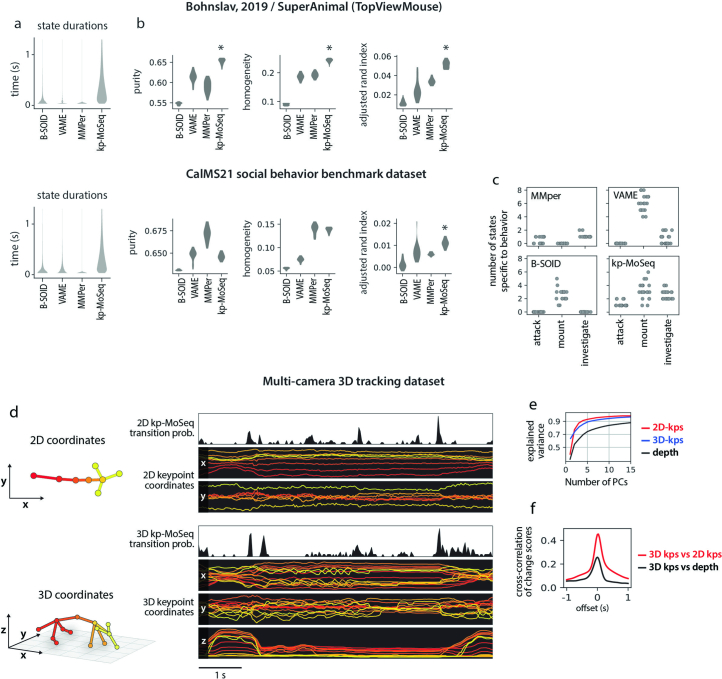
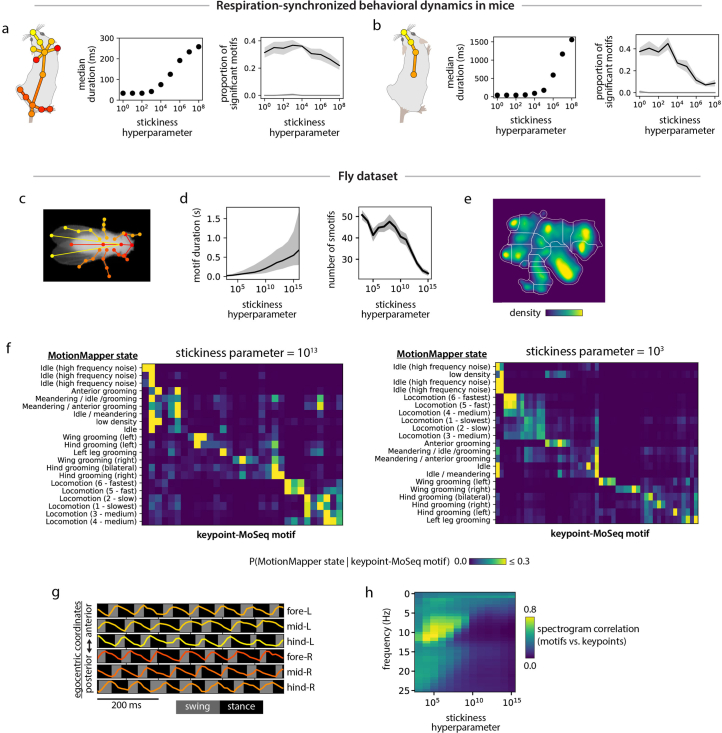
Keypoint tracking algorithms can flexibly quantify animal movement from videos obtained in a wide variety of settings. However, it remains unclear how to parse continuous keypoint data into discrete actions. This challenge is particularly acute because keypoint data are susceptible to high-frequency jitter that clustering algorithms can mistake for transitions between actions. Here we present keypoint-MoSeq, a machine learning-based platform for identifying behavioral modules ('syllables') from keypoint data without human supervision. Keypoint-MoSeq uses a generative model to distinguish keypoint noise from behavior, enabling it to identify syllables whose boundaries correspond to natural sub-second discontinuities in pose dynamics. Keypoint-MoSeq outperforms commonly used alternative clustering methods at identifying these transitions, at capturing correlations between neural activity and behavior and at classifying either solitary or social behaviors in accordance with human annotations. Keypoint-MoSeq also works in multiple species and generalizes beyond the syllable timescale, identifying fast sniff-aligned movements in mice and a spectrum of oscillatory behaviors in fruit flies. Keypoint-MoSeq, therefore, renders accessible the modular structure of behavior through standard video recordings.
© 2024. The Author(s).
Conflict of interest statement
S.R.D. sits on the scientific advisory boards of Neumora and Gilgamesh Therapeutics, which have licensed or sub-licensed the MoSeq technology. The other authors declare no competing interests.
Figures
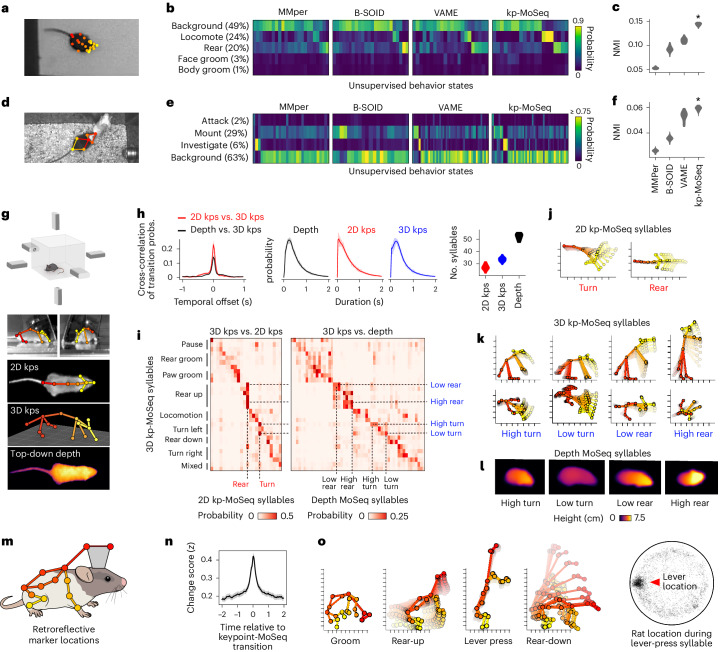
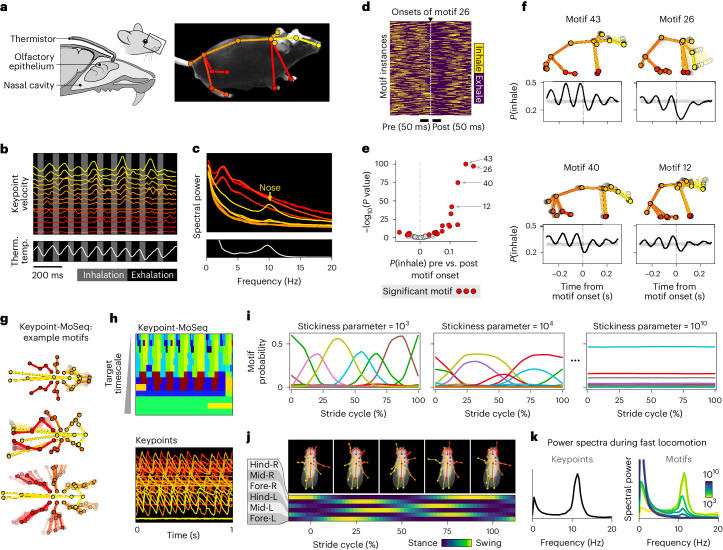
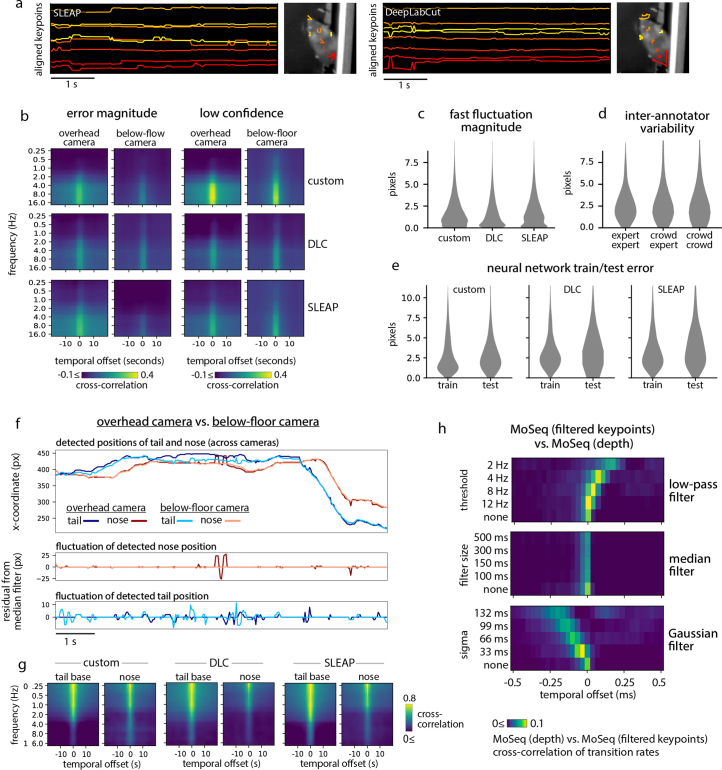
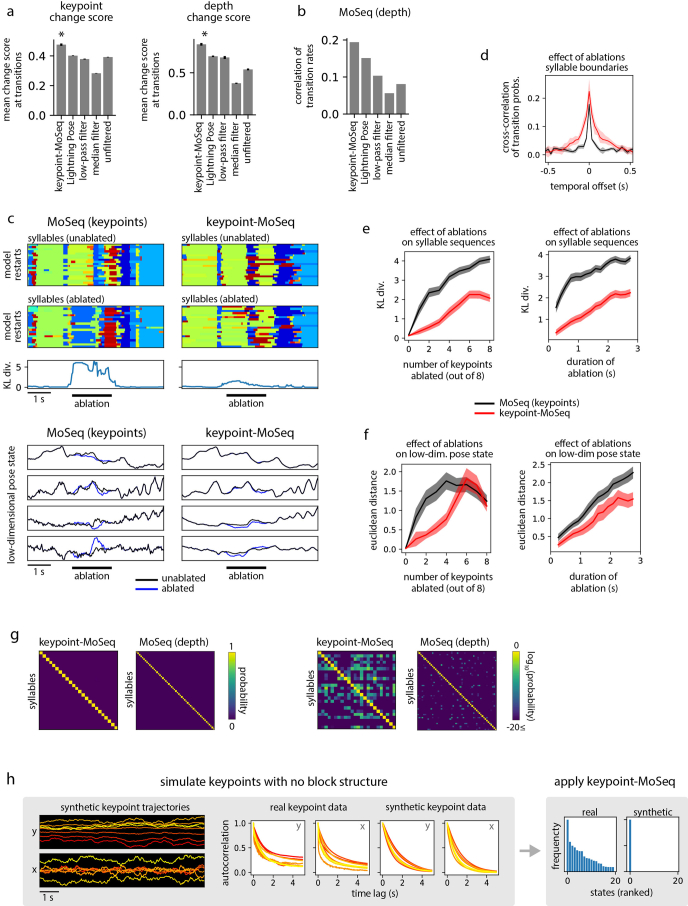
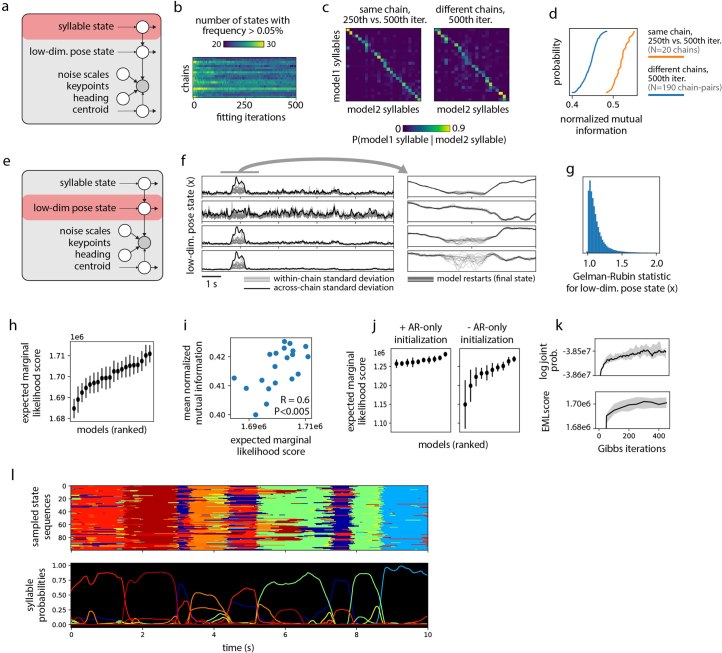
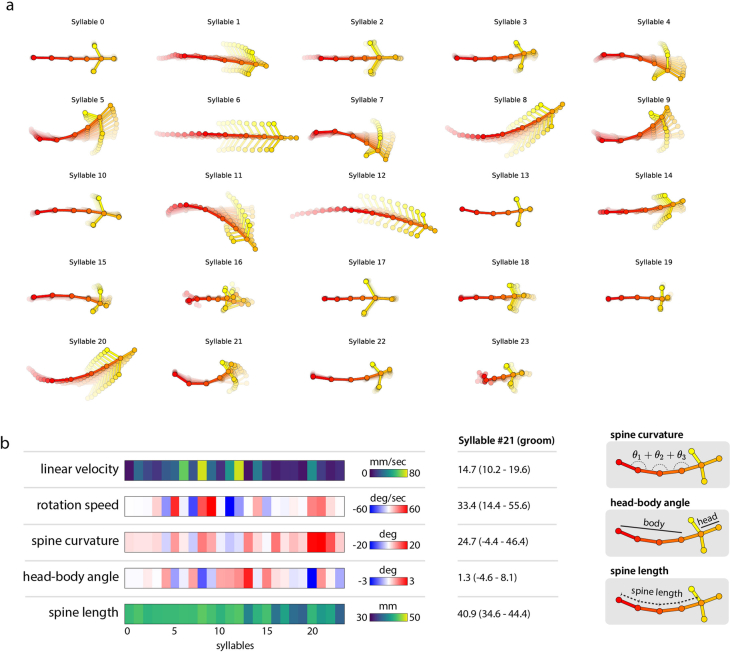
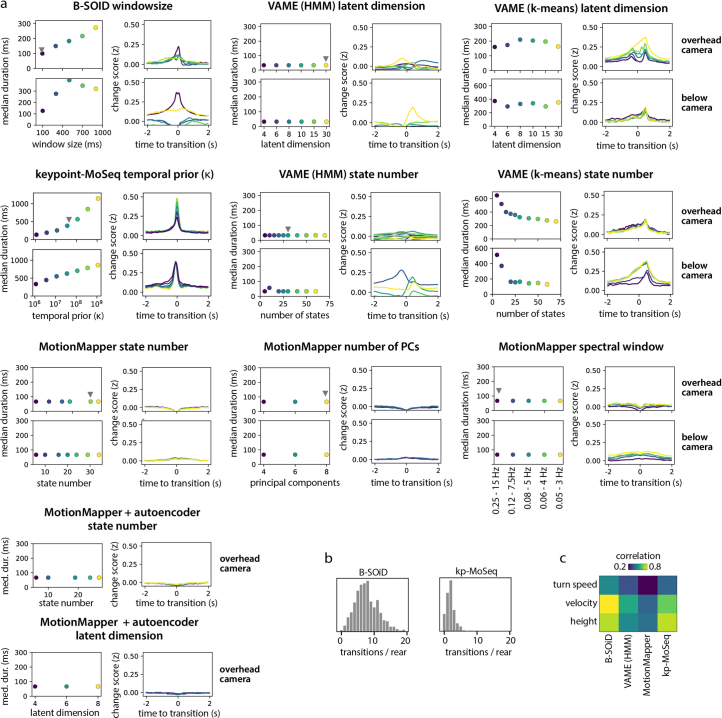
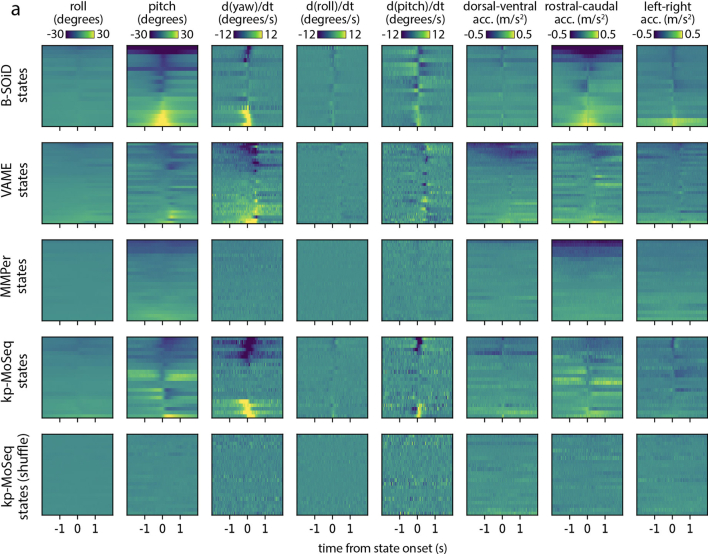
Update of
-
Keypoint-MoSeq: parsing behavior by linking point tracking to pose dynamics.bioRxiv [Preprint]. 2023 Dec 23:2023.03.16.532307. doi: 10.1101/2023.03.16.532307. bioRxiv. 2023. Update in: Nat Methods. 2024 Jul;21(7):1329-1339. doi: 10.1038/s41592-024-02318-2. PMID: 36993589 Free PMC article. Updated. Preprint.
References
-
- Tinbergen, N. The Study of Instinct (Clarendon Press, 1951).
-
- Dawkins, R. In Growing Points in Ethology (Bateson, P. P. G. & Hinde, R. A. eds.) Chap 1 (Cambridge University Press, 1976).
-
- Baerends GP. The functional organization of behaviour. Anim. Behav. 1976;24:726–738. doi: 10.1016/S0003-3472(76)80002-4. - DOI
MeSH terms
Grants and funding
- F31 NS113385/NS/NINDS NIH HHS/United States
- U24NS109520/U.S. Department of Health & Human Services | National Institutes of Health (NIH)
- U19 NS113201/NS/NINDS NIH HHS/United States
- F31 NS122155/NS/NINDS NIH HHS/United States
- RF1AG073625/U.S. Department of Health & Human Services | National Institutes of Health (NIH)
- F31NS122155/U.S. Department of Health & Human Services | National Institutes of Health (NIH)
- RF1 AG073625/AG/NIA NIH HHS/United States
- R01 NS114020/NS/NINDS NIH HHS/United States
- U24 NS109520/NS/NINDS NIH HHS/United States
- P30 EY012196/EY/NEI NIH HHS/United States
- F31NS113385/U.S. Department of Health & Human Services | National Institutes of Health (NIH)
- R01NS114020/U.S. Department of Health & Human Services | National Institutes of Health (NIH)
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
